Содержание статьи

Сводная таблица в SQL – это результат запроса, который преобразует набор строк в структурированный отчет с агрегированными значениями. Такой подход применяется при анализе продаж, логов, финансовых операций и метрик, когда требуется увидеть распределение данных по категориям и периодам. На практике это означает работу с функциями SUM, COUNT, AVG и управляемым группированием данных на уровне запроса.
В SQL нет универсального оператора, который одинаково работает во всех СУБД, поэтому создание сводных таблиц часто опирается на комбинацию GROUP BY, условных выражений и специализированных конструкций вроде PIVOT. В PostgreSQL и MySQL обычно используют CASE WHEN, а в SQL Server и Oracle доступны встроенные механизмы разворота данных. Выбор подхода напрямую зависит от структуры исходной таблицы и требований к формату результата.
При проектировании сводной таблицы важно заранее определить измерения и показатели: какие поля станут строками, какие – столбцами, а какие – агрегируемыми значениями. Ошибки на этом этапе приводят к дублированию данных или некорректным итогам. Отдельного внимания требует обработка NULL-значений, так как они могут искажать сумму или количество при агрегации.
Практическая работа со сводными таблицами в SQL также включает оптимизацию запросов для больших объемов данных. Использование индексов, предварительная фильтрация через WHERE и ограничение набора столбцов позволяют получить результат без перегрузки сервера. Грамотно построенная сводная таблица становится основой для отчетов, дашбордов и последующего анализа данных.
Подготовка исходных данных для агрегации
Перед построением сводной таблицы необходимо привести исходные данные к форме, пригодной для группировки и вычислений. На этом этапе устраняются дубликаты, уточняется тип данных и задается логика отбора строк. Любая агрегация в SQL опирается на корректный набор записей, поэтому ошибки подготовки напрямую отражаются на результате.
Первый шаг – проверка структуры таблицы и типов столбцов. Поля, участвующие в вычислениях, должны иметь числовые типы, а измерения – однозначные значения без смешения форматов.
- привести строки с числами к типам INT, NUMERIC или DECIMAL
- нормализовать даты в формате DATE или TIMESTAMP
- устранить текстовые значения, используемые вместо чисел
Далее выполняется фильтрация данных, которые не должны участвовать в агрегации. Для этого используется WHERE, позволяющий сократить объем обрабатываемых строк до релевантного набора.
- исключение тестовых и архивных записей
- отбор данных за конкретный период
- фильтрация по статусу, региону или типу операции
Особое внимание следует уделить NULL-значениям. Они не учитываются в функциях SUM и AVG, но влияют на результат при объединении данных. В большинстве случаев их заменяют на нули или явно исключают.
- использование COALESCE для подстановки значений по умолчанию
- удаление строк с критичными пропусками
- разделение логики для обязательных и необязательных полей
Если данные поступают из нескольких источников, перед агрегацией требуется корректное объединение через JOIN. Тип соединения влияет на полноту результата, поэтому его выбирают осознанно.
- INNER JOIN – только совпадающие записи
- LEFT JOIN – сохранение строк из основной таблицы
- FULL JOIN – объединение всех доступных данных
Завершающий этап – формирование вычисляемых полей, которые будут участвовать в сводной таблице. Расчеты выполняются до группировки, чтобы агрегатные функции работали с готовыми значениями.
- вычисление сумм с учетом скидок и налогов
- приведение значений к единой валюте
- категоризация данных с помощью CASE WHEN
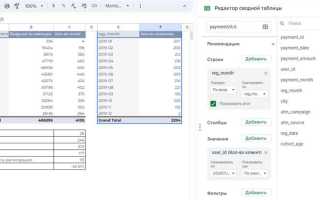
Использование GROUP BY для формирования строк сводной таблицы
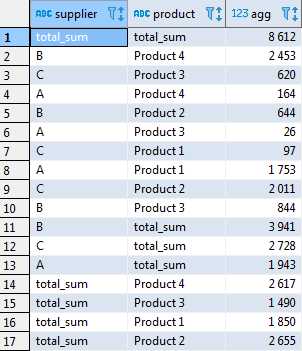
Оператор GROUP BY определяет, какие значения станут строками сводной таблицы. Каждая уникальная комбинация полей, указанных в группировке, формирует отдельную строку результата. При работе с отчетами по продажам это могут быть категории товаров, регионы, даты или идентификаторы клиентов.
Все столбцы, не участвующие в агрегатных функциях, обязаны присутствовать в GROUP BY. Нарушение этого правила приводит к ошибке выполнения запроса или некорректной логике агрегации. Например, если требуется получить сумму заказов по месяцам и регионам, оба поля должны быть явно перечислены в группировке.
Для формирования читаемых строк часто используют производные выражения вместо сырых значений. Группировка по вычисляемым полям позволяет управлять уровнем детализации результата.
При работе с датами целесообразно агрегировать данные по периодам, а не по полным временным меткам. Для этого применяются функции приведения и извлечения компонентов даты.
Глубина детализации напрямую зависит от количества полей в GROUP BY. Избыточная группировка приводит к раздробленному результату с малым числом значений в каждой строке. Минимальный набор измерений упрощает анализ и снижает нагрузку на сервер.
Важно учитывать порядок обработки данных: фильтрация через WHERE выполняется до группировки, а условия для агрегированных значений задаются через HAVING. Это позволяет отсекать строки на основе рассчитанных показателей, например исключать группы с нулевой суммой.
Для стабильного результата при работе с большими наборами данных рекомендуется:
– группировать только по индексированным полям, когда это возможно;
– избегать функций в GROUP BY, если их можно вынести в подзапрос;
– проверять уникальность комбинаций измерений до построения сводной таблицы.
Создание столбцов сводной таблицы с помощью CASE WHEN
Конструкция CASE WHEN применяется для разворота данных в столбцы в тех СУБД, где отсутствует оператор PIVOT или требуется полный контроль над логикой формирования результата. Каждый вычисляемый столбец описывает отдельное условие, а агрегатная функция суммирует или подсчитывает значения, соответствующие этому условию.
Базовый принцип заключается в использовании CASE WHEN внутри агрегатных функций. Условие определяет, какие строки участвуют в расчете, а все остальные возвращают NULL или ноль. Такой подход позволяет формировать несколько столбцов в одном запросе без дополнительных подзапросов.
Для числовых показателей чаще всего применяется SUM в сочетании с возвратом нуля по умолчанию. Это предотвращает искажение итогов и упрощает дальнейшую обработку результата. Для подсчета записей используется COUNT с условием на ненулевое значение.
При создании столбцов важно заранее зафиксировать набор значений, по которым выполняется разворот. Если в данных появляются новые категории, они не будут автоматически добавлены в результат, что требует пересмотра запроса. По этой причине CASE WHEN подходит для отчетов со стабильной структурой.
Логику условий рекомендуется формировать максимально явно, избегая пересечений. Каждая строка должна попадать только под одно условие, иначе значения будут распределены между несколькими столбцами. Это особенно критично при анализе статусов, типов операций и диапазонов дат.
Для повышения читаемости и поддержки запроса вычисляемые столбцы следует именовать с учетом бизнес-смысла, а сложные условия выносить в подзапрос или представление. Такой подход упрощает сопровождение сводной таблицы и снижает риск логических ошибок при изменении требований.
Построение сводной таблицы через оператор PIVOT

Оператор PIVOT используется для разворота строк в столбцы на уровне SQL-запроса и доступен в SQL Server, Oracle и ряде аналитических СУБД. В отличие от условной агрегации, PIVOT задает структуру сводной таблицы декларативно, что упрощает чтение и сопровождение запроса при фиксированном наборе столбцов.
Работа с PIVOT начинается с подготовки подзапроса, в котором данные уже приведены к нужному уровню детализации. В этом подзапросе выбираются измерения для строк, поле для разворота и агрегируемое значение. Любая лишняя колонка приведет к дублированию строк после применения оператора.
В секции PIVOT явно указывается агрегатная функция и перечень значений, которые будут преобразованы в столбцы. Эти значения задаются статически, поэтому запрос требует обновления при изменении списка категорий. Неполное перечисление приводит к потере данных, а лишние значения формируют столбцы с пустыми результатами.
Для корректной интерпретации результата важно контролировать имена создаваемых столбцов. Большинство СУБД позволяют задать алиасы, которые используются в отчетах и внешних инструментах аналитики. Четкое именование упрощает интеграцию сводной таблицы с BI-системами и прикладным кодом.
PIVOT чувствителен к NULL-значениям в агрегируемом поле. При отсутствии данных итоговые ячейки возвращают NULL, что может потребовать дополнительной обработки на уровне запроса или приложения. В расчетных отчетах это учитывается заранее, чтобы итоговые значения не требовали ручной корректировки.
Работа с динамическим набором столбцов в сводной таблице
Динамический набор столбцов возникает в случаях, когда категории данных заранее неизвестны или регулярно меняются, например при анализе событий, статусов или пользовательских атрибутов. Статические конструкции, такие как фиксированный CASE WHEN или оператор PIVOT с жестко заданным списком значений, в таких сценариях требуют постоянного ручного обновления.
На уровне SQL задача решается через формирование запроса во время выполнения. Сначала извлекается актуальный список значений, которые должны стать столбцами, после чего на его основе собирается текст основного запроса. Такой подход реализуется с помощью динамического SQL и поддерживается большинством промышленных СУБД.
При генерации списка столбцов важно обеспечить детерминированный порядок и исключить дубликаты. Обычно для этого применяется отдельный запрос с DISTINCT и сортировкой. Полученные значения экранируются и используются для построения выражений агрегации или секции разворота.
Динамическая сводная таблица требует повышенного внимания к безопасности. Все параметры, участвующие в генерации SQL-кода, должны быть получены из доверенных источников или дополнительно проверены. Это снижает риск выполнения некорректных запросов и упрощает поддержку системы.
С точки зрения производительности динамический подход увеличивает нагрузку на планировщик запросов, так как текст SQL постоянно меняется. Для компенсации этого эффекта часто используют кэширование результата, материализованные представления или промежуточные таблицы с обновлением по расписанию.
Обработка NULL и форматирование результата сводной таблицы
NULL-значения напрямую влияют на интерпретацию сводной таблицы, так как агрегатные функции и логика разворота данных обрабатывают их по-разному. При отсутствии данных в ячейке результат часто теряет смысл для аналитика, поэтому правила работы с NULL задаются на уровне запроса.
Для числовых показателей наиболее распространённый подход – явная подстановка нуля. Это выполняется с помощью COALESCE или аналогичных функций, применяемых к результатам агрегации. Такой приём позволяет корректно отображать отсутствие значений без искажения общей структуры сводной таблицы.
При использовании PIVOT NULL возникает в случаях, когда для заданной комбинации строки и столбца нет исходных записей. Если эти значения участвуют в дальнейших расчётах, обработку следует выполнять сразу после разворота данных, а не на уровне клиентского приложения.
Текстовые поля и категориальные столбцы требуют отдельного подхода. Вместо пустых значений обычно используется осмысленная метка, отражающая отсутствие данных. Это упрощает фильтрацию и снижает вероятность ошибочной интерпретации результата.
Форматирование результата включает приведение чисел к требуемой точности, округление и согласование единиц измерения. Эти операции выполняются после агрегации, чтобы избежать накопления погрешностей. Для финансовых и статистических отчетов форматирование фиксируется в запросе, а не перекладывается на уровень визуализации.
Завершающий этап – проверка согласованности результата. Суммы по строкам и столбцам должны соответствовать исходным данным, а отсутствие значений не должно нарушать логику отчета. Контроль на этом этапе предотвращает распространение ошибок в последующем анализе.
Вопрос-ответ:
Чем отличается сводная таблица на основе GROUP BY от отчета с оператором PIVOT?
GROUP BY формирует строки результата и позволяет агрегировать данные по любым сочетаниям полей, а столбцы при этом остаются фиксированными. PIVOT выполняет разворот значений одного поля в отдельные колонки, что дает более наглядный отчет при стабильном наборе категорий. Выбор подхода зависит от того, требуется ли управлять структурой столбцов или достаточно сгруппировать строки с расчетом показателей.
Как избежать появления лишних строк при построении сводной таблицы?
Лишние строки появляются, если в GROUP BY включены поля, не влияющие на бизнес-смысл отчета. Перед агрегацией стоит проверить уникальность комбинаций измерений и убрать технические идентификаторы, временные метки и служебные признаки. Полезно сначала выполнить запрос без агрегатных функций и оценить, какие значения реально участвуют в группировке.
Почему при использовании CASE WHEN в сводной таблице часть значений пропадает?
Такое поведение связано с условиями, которые не покрывают все возможные варианты данных. Если строка не попадает ни под одно условие, агрегатная функция получает NULL и не учитывает значение. Для контроля ситуации добавляют ветку ELSE с нулем или заранее анализируют диапазон допустимых значений.
Можно ли построить сводную таблицу с неизвестным заранее набором столбцов?
Да, для этого применяется динамический SQL. Сначала формируется список уникальных значений, которые должны стать столбцами, затем на его основе собирается текст запроса с агрегацией и разворотом данных. Такой подход чаще используется в аналитических отчетах, где структура результата зависит от текущего состояния данных.
Как правильно работать с NULL в результатах сводной таблицы?
NULL означает отсутствие данных для конкретной комбинации строки и столбца. В числовых показателях его обычно заменяют на ноль, чтобы сохранить целостность отчета. Для категориальных полей применяют явные обозначения отсутствия значений, что упрощает фильтрацию и последующий анализ.
Почему агрегатные значения в сводной таблице не совпадают с итогами из исходной таблицы?
Расхождения чаще всего связаны с логикой группировки и фильтрации данных. Если условие WHERE отсекает часть строк до выполнения GROUP BY, итоговые суммы будут меньше ожидаемых. Также ошибка возникает при соединении таблиц через JOIN, когда одна строка исходных данных дублируется из-за связей «один ко многим». Перед агрегацией полезно проверить количество строк после всех объединений и убедиться, что каждая запись участвует в расчётах ровно один раз.