Содержание статьи

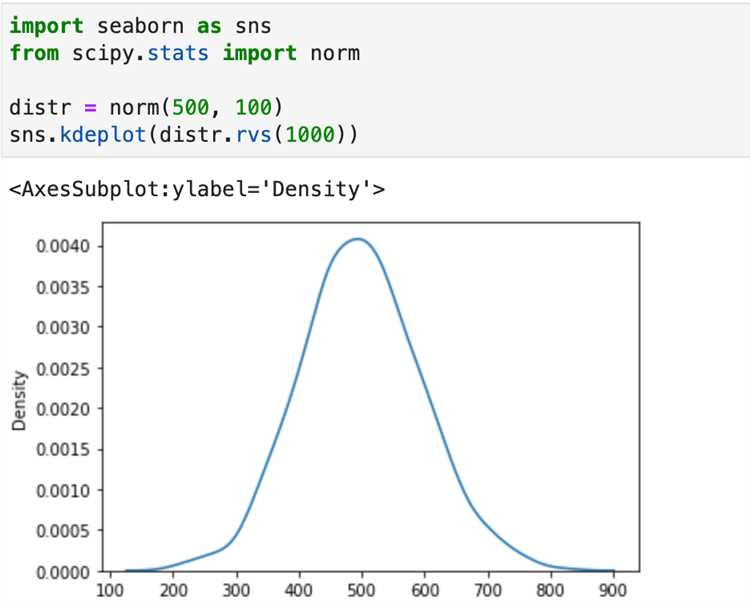
Дисперсия измеряет разброс значений вокруг среднего и помогает оценить изменчивость данных. В Python её можно вычислять как вручную через формулу σ² = Σ(xᵢ — μ)² / n, так и с помощью встроенных библиотек, включая NumPy и pandas. Для массивов с тысячами элементов ручной расчёт занимает много времени, поэтому чаще применяют оптимизированные функции.
При работе с выборками важно различать выборочную и генеральную дисперсию. Формула выборочной дисперсии делит сумму квадратов отклонений на n-1, что компенсирует смещение оценки при ограниченном объёме данных. В Python это учитывается параметром ddof в NumPy и pandas.
Для анализа больших наборов данных вычисление дисперсии по столбцам DataFrame позволяет быстро выявлять колебания показателей. Использование методов df.var() или numpy.var() упрощает обработку сотен и тысяч строк без ручных циклов. Визуальное сравнение дисперсий разных наборов данных через графики помогает оценить относительную изменчивость и принять решения о стандартизации или фильтрации данных.
Расчёт дисперсии для списка чисел вручную с использованием формулы
Для расчёта дисперсии вручную создаём список чисел, например: data = [4, 8, 6, 5, 3, 7]. Сначала вычисляем среднее значение μ с помощью формулы μ = Σxᵢ / n. В данном примере сумма элементов равна 33, количество элементов – 6, значит μ = 5.5.
Далее вычисляем отклонения каждого значения от среднего: (xᵢ — μ), затем возводим их в квадрат. Для списка выше квадраты отклонений: (4-5.5)²=2.25, (8-5.5)²=6.25, (6-5.5)²=0.25, (5-5.5)²=0.25, (3-5.5)²=6.25, (7-5.5)²=2.25.
Суммируем полученные квадраты отклонений: 2.25+6.25+0.25+0.25+6.25+2.25 = 17.5. Для генеральной дисперсии делим на количество элементов n=6, получаем σ² = 17.5 / 6 ≈ 2.9167. Для выборочной дисперсии делим на n-1 = 5, результат σ² ≈ 3.5.
В Python этот процесс реализуется через цикл: создаём переменную для суммы квадратов отклонений, проходим по списку, прибавляем (x — μ)**2 к сумме, затем делим на n или n-1 в зависимости от типа дисперсии. Такой подход полезен для небольших наборов данных или для учебных целей, когда важно видеть каждый шаг вычислений.
Использование библиотеки NumPy для вычисления дисперсии массива
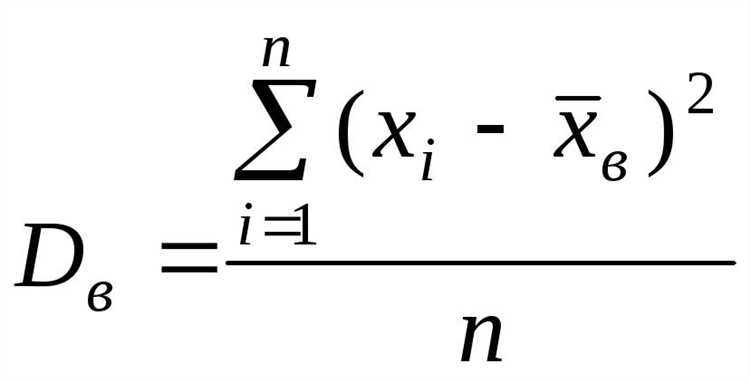
Библиотека NumPy позволяет вычислять дисперсию массивов чисел быстро и с минимальным кодом. Основная функция для этого – numpy.var(), которая возвращает дисперсию по всей структуре данных или по указанной оси.
Пример работы с одномерным массивом:
- Импортируем библиотеку: import numpy as np.
- Создаём массив: data = np.array([4, 8, 6, 5, 3, 7]).
- Вычисляем генеральную дисперсию: np.var(data), результат 2.9167.
- Вычисляем выборочную дисперсию, используя параметр ddof=1: np.var(data, ddof=1), результат 3.5.
Для многомерных массивов можно вычислять дисперсию по строкам или столбцам, указывая параметр axis:
- axis=0 – по столбцам.
- axis=1 – по строкам.
NumPy автоматически обрабатывает большие массивы и оптимизирует вычисления, поэтому для массивов размером в сотни тысяч элементов достаточно одной функции, без ручных циклов. Рекомендуется явно указывать ddof, чтобы корректно отличать выборочную и генеральную дисперсию в анализе данных.
Различие между выборочной и генеральной дисперсией в Python
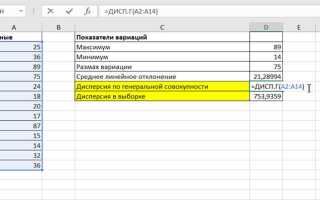
Генеральная дисперсия отражает разброс всех значений полной совокупности. Формула для неё: σ² = Σ(xᵢ — μ)² / n, где n – размер совокупности. В Python её легко вычислить через numpy.var(data, ddof=0) или pandas.Series.var(ddof=0). Для массива [4, 8, 6, 5, 3, 7] результат будет 2.9167.
Выборочная дисперсия оценивает разброс данных в выборке и корректирует смещение, деля сумму квадратов отклонений на n-1. В Python это задаётся параметром ddof=1. Для той же выборки numpy.var(data, ddof=1) возвращает 3.5. Такой подход необходим при статистическом анализе выборок, чтобы не недооценивать изменчивость.
Рекомендации при работе с Python:
- Если анализируем полный набор данных, используйте ddof=0.
- Если данные представляют выборку из большей совокупности, задайте ddof=1 для корректной оценки дисперсии.
- При многомерных массивах указывайте axis, чтобы контролировать направление вычислений.
Вычисление дисперсии по столбцу в DataFrame с помощью pandas
В pandas дисперсию по столбцу вычисляют через метод df[‘column’].var(). Этот метод по умолчанию возвращает выборочную дисперсию (ddof=1), корректируя деление на n-1 для оценки разброса выборки.
Пример: создаём DataFrame df = pd.DataFrame({‘A’: [4, 8, 6, 5, 3, 7], ‘B’: [10, 12, 15, 11, 14, 13]}). Чтобы получить дисперсию столбца A, используем df[‘A’].var(), результат 3.5. Для столбца B метод возвращает 3.5, что отражает одинаковый разброс значений.
Для расчёта генеральной дисперсии добавляем параметр ddof=0: df[‘A’].var(ddof=0), результат 2.9167. Рекомендуется явно указывать ddof, чтобы избежать недоразумений при сравнении разных наборов данных.
Метод работает с числовыми и datetime столбцами, игнорируя пропущенные значения NaN. Для нескольких столбцов одновременно можно использовать df[[‘A’,’B’]].var(), что возвращает серию с дисперсиями каждого столбца, упрощая анализ нескольких показателей в одном вызове.
Применение дисперсии для оценки разброса данных в проектах анализа
Дисперсия позволяет количественно оценивать изменчивость показателей и выявлять столбцы с высокой вариативностью. В проектах анализа данных её используют для контроля качества данных, сравнения метрик между группами и выявления аномалий.
Например, при анализе продаж по магазинам дисперсия выручки σ² = 1200 указывает на значительные колебания между точками, а низкая дисперсия σ² = 50 – на стабильность. В Python удобно вычислять дисперсию через pandas для каждого показателя и использовать результат для фильтрации столбцов с чрезмерной изменчивостью.
Рекомендации при практическом применении:
- Используйте дисперсию совместно с средним и медианой для оценки центральной тенденции и разброса.
- Сравнивайте дисперсии разных наборов данных для выявления несоответствий и нестабильных процессов.
- Для визуального анализа строите гистограммы и boxplot рядом с вычисленной дисперсией – это облегчает интерпретацию разброса и выявление выбросов.
- При больших данных используйте NumPy для вычислений, чтобы сократить время обработки и избежать ошибок округления.
Сравнение дисперсий позволяет определить, какой набор данных имеет больший разброс и потенциальные аномалии. В Python для этого используют pandas или NumPy для расчёта дисперсии и matplotlib или seaborn для графического отображения.
Пример двух наборов данных:
| Набор | Значения |
|---|---|
| Data1 | [4, 8, 6, 5, 3, 7] |
| Data2 | [10, 12, 15, 11, 14, 13] |
Вычисляем дисперсию:
- Data1: np.var([4, 8, 6, 5, 3, 7], ddof=1) = 3.5
- Data2: np.var([10, 12, 15, 11, 14, 13], ddof=1) = 4.7
Графический анализ упрощает сравнение. Рекомендуется строить:
- Boxplot для каждого набора – позволяет видеть медиану, межквартильный размах и выбросы.
- Гистограммы рядом – наглядно демонстрируют распределение и ширину разброса.
- Bar chart дисперсий – прямой способ сравнить количественные значения σ².
Используя комбинацию вычислений и визуализации, можно быстро оценить стабильность процессов, сравнивать метрики и выявлять наборы данных с непредсказуемыми колебаниями.
Вопрос-ответ:
Чем выборочная дисперсия отличается от генеральной в Python?
Выборочная дисперсия используется для оценки разброса данных в выборке, представляющей часть всей совокупности. При расчёте её сумма квадратов отклонений делится на n-1, а не на n, что корректирует смещение оценки. В Python это задаётся параметром ddof=1 в функциях numpy.var() или pandas.Series.var(). Генеральная дисперсия делится на n и применяется, если у нас есть полный набор данных.
Как вручную вычислить дисперсию для списка чисел?
Сначала вычисляем среднее значение μ списка, суммируя все элементы и деля на количество элементов. Затем находим отклонение каждого значения от среднего, возводим его в квадрат и суммируем эти квадраты. Для генеральной дисперсии делим полученную сумму на количество элементов, а для выборочной — на n-1. Например, для списка [4, 8, 6, 5, 3, 7] выборочная дисперсия ≈ 3.5, генеральная ≈ 2.9167.
Можно ли сразу вычислить дисперсию по всем столбцам DataFrame?
Да, в pandas можно использовать df.var() без указания конкретного столбца. Метод вернёт серию, где каждому числовому столбцу соответствует его дисперсия. Если нужны генеральные значения, задайте ddof=0. Метод автоматически игнорирует пропуски NaN и корректно вычисляет дисперсию для каждого столбца.
Как визуально сравнить дисперсию нескольких наборов данных?
Для визуальной оценки разброса создают графики: boxplot показывает медиану, квартильный размах и выбросы, гистограммы демонстрируют распределение значений, а столбчатая диаграмма позволяет сравнить численные значения дисперсий. Например, если Data1 имеет σ² = 3.5, а Data2 σ² = 4.7, то графически можно сразу увидеть, что второй набор имеет более широкий разброс.
Когда лучше использовать NumPy вместо ручного расчёта дисперсии?
NumPy удобен для больших массивов, где ручной цикл займёт много времени. Функция numpy.var() работает с массивами любой размерности и поддерживает параметры ddof и axis, что позволяет легко получать выборочную или генеральную дисперсию по строкам или столбцам. Для массивов более нескольких тысяч элементов это надёжнее и быстрее, чем ручные вычисления.
Можно ли использовать pandas для расчёта дисперсии только для определённого диапазона строк?
Да, в pandas можно сначала выбрать нужный диапазон строк через срез или метод loc, а затем применить .var(). Например, df.loc[2:5, ‘A’].var() вычислит дисперсию столбца A только для строк с индексами от 2 до 5. Это полезно, если нужно анализировать периодические данные или фрагменты выборки без изменения всего DataFrame.
Как учитывать пропущенные значения при расчёте дисперсии в NumPy и pandas?
В NumPy стандартная функция np.var() не игнорирует NaN, и при их наличии результат будет NaN. Для массивов с пропущенными данными следует использовать np.nanvar(), которая автоматически исключает пропуски из расчёта. В pandas метод .var() по умолчанию игнорирует NaN, поэтому дисперсия вычисляется только по существующим значениям, без дополнительных настроек. Это позволяет работать с неполными наборами данных без ручной фильтрации.