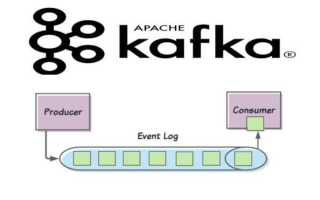
Apache Kafka – это распределённая платформа потоковой передачи данных, которая позволяет обрабатывать миллионы сообщений в секунду с гарантией доставки. В Java-приложениях Kafka часто используется для интеграции микросервисов, построения систем реального времени и анализа больших объёмов данных. Kafka обеспечивает высокую отказоустойчивость за счёт репликации топиков и масштабируемость через шардирование партиций.
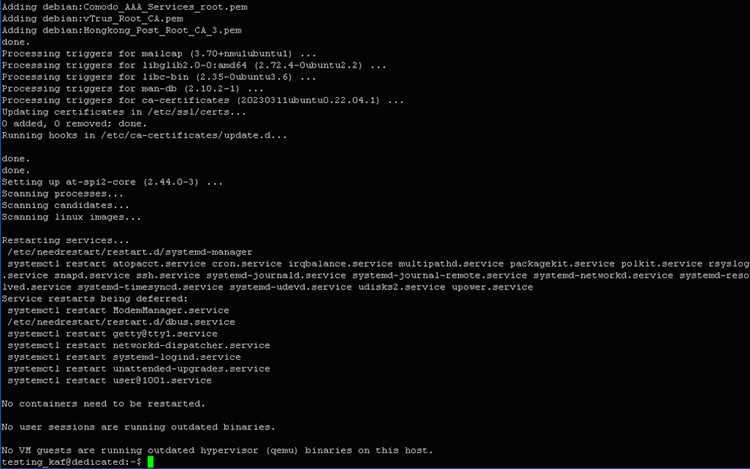 – это распределённая платформа потоковой передачи данных, которая позволяет обрабатывать миллионы сообщений в секунду с гарантией доставки. В Java-приложениях Kafka часто используется для интеграции микросервисов, построения систем реального времени и анализа больших объёмов данных. Kafka обеспечивает высокую отказоустойчивость за счёт репликации топиков и масштабируемость через шардирование партиций.»>
– это распределённая платформа потоковой передачи данных, которая позволяет обрабатывать миллионы сообщений в секунду с гарантией доставки. В Java-приложениях Kafka часто используется для интеграции микросервисов, построения систем реального времени и анализа больших объёмов данных. Kafka обеспечивает высокую отказоустойчивость за счёт репликации топиков и масштабируемость через шардирование партиций.»>
Для работы с Kafka в Java применяются официальные клиенты Kafka Producer и Consumer. Producer отвечает за отправку сообщений в топики, а Consumer – за их считывание и обработку. Подключение через Maven или Gradle позволяет управлять зависимостями и использовать актуальные версии клиентов, совместимые с вашим Kafka-брокером.
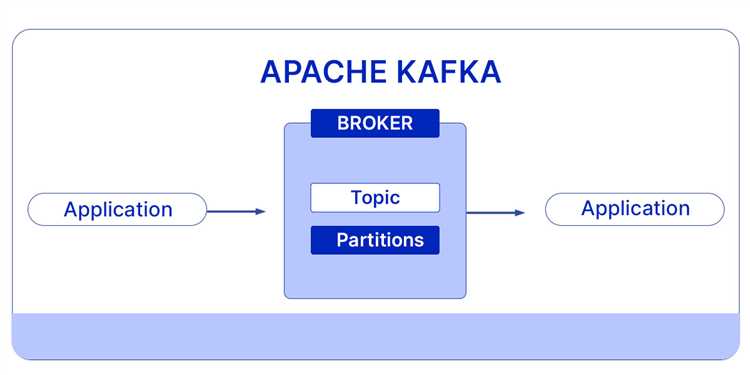 применяются официальные клиенты Kafka Producer и Consumer. Producer отвечает за отправку сообщений в топики, а Consumer – за их считывание и обработку. Подключение через Maven или Gradle позволяет управлять зависимостями и использовать актуальные версии клиентов, совместимые с вашим Kafka-брокером.»>
применяются официальные клиенты Kafka Producer и Consumer. Producer отвечает за отправку сообщений в топики, а Consumer – за их считывание и обработку. Подключение через Maven или Gradle позволяет управлять зависимостями и использовать актуальные версии клиентов, совместимые с вашим Kafka-брокером.»>
При разработке важно учитывать архитектуру топиков, количество партиций и политику хранения сообщений. Kafka хранит данные в виде непрерывного лога, что позволяет повторно считывать сообщения и управлять смещениями (offsets) на уровне приложения. Для оптимальной производительности рекомендуются настройки batch-передачи сообщений, асинхронная отправка и использование сериализации Avro или JSON для структурированных данных.

В этой статье показаны практические шаги по запуску Kafka-сервера, подключению Java-приложения, отправке и чтению сообщений, а также управлению смещениями и мониторингу потоков данных. Все примеры ориентированы на реальную работу с Kafka, чтобы вы могли интегрировать её в свои проекты без лишней теории.
Вопрос-ответ:
Для чего в Java используют Kafka и чем она отличается от обычной очереди сообщений?
Kafka применяется для обработки больших потоков данных и передачи сообщений между сервисами с высокой производительностью. В отличие от классических очередей сообщений, Kafka хранит данные в виде непрерывного лога и позволяет потребителям считывать сообщения многократно, управляя смещениями (offsets). Это обеспечивает возможность масштабирования через партиции и повторное считывание сообщений без их потери.
Как настроить локальный Kafka-брокер для тестирования Java-приложений?
Для локальной разработки достаточно скачать дистрибутив Kafka с официального сайта и запустить Zookeeper и брокер через скрипты bin/zookeeper-server-start.sh и bin/kafka-server-start.sh. В Java-проекте необходимо подключить клиентскую библиотеку через Maven или Gradle, указав актуальную версию. После этого можно создавать топики командой kafka-topics.sh и отправлять в них сообщения с помощью Producer, а считывать — с помощью Consumer.
Как Java-приложение правильно управляет смещениями сообщений в Kafka?
Смещения (offsets) в Kafka хранятся либо на стороне брокера, либо локально в приложении. Consumer может использовать автоматическое подтверждение прочтения сообщений или управлять смещениями вручную через commitSync() и commitAsync(). Ручное управление позволяет точно контролировать, какие сообщения были обработаны, и повторно обрабатывать данные в случае сбоев. Такой подход полезен для систем, где важна строгая последовательность обработки и отсутствие потери сообщений.
Какие форматы сериализации сообщений лучше использовать в Java с Kafka?
На практике чаще всего применяются JSON и Avro. JSON удобен для быстрого прототипирования и обмена данными между разными сервисами, но занимает больше памяти и требует парсинга при обработке. Avro обеспечивает компактное бинарное хранение и поддержку схем, что уменьшает размер сообщений и облегчает проверку структуры данных на стороне потребителя. Выбор зависит от требований к производительности и совместимости сервисов.
Какие ошибки чаще всего возникают при работе с Kafka в Java и как их избежать?
Частые ошибки связаны с неверной конфигурацией топиков, несовпадением версий клиента и брокера, а также с некорректной обработкой смещений. Чтобы избежать проблем, рекомендуется проверять наличие топиков перед отправкой сообщений, использовать совместимые версии библиотек, настроить таймауты для Producer и Consumer, а также логировать обработку сообщений для выявления повторов или пропусков. Мониторинг состояния брокеров через JMX помогает заранее выявлять сбои и узкие места.
Как настроить Java-приложение для одновременной работы с несколькими топиками Kafka и обработкой потоков данных параллельно?
Для работы с несколькими топиками в одном приложении создаются отдельные экземпляры Consumer для каждого топика или один Consumer с подпиской на несколько топиков. Важно учитывать количество партиций: если топик имеет несколько партиций, можно распределить потоки обработки между разными потоками Java, назначая каждому поток Consumer для своей партиции. Для управления смещениями удобно использовать commitAsync(), чтобы не блокировать основной поток обработки. При этом Producer может отправлять сообщения в разные топики асинхронно, используя разные ключи для распределения по партициям. Такой подход позволяет обрабатывать сообщения параллельно, поддерживать порядок в каждой партиции и контролировать нагрузку на приложение.