Содержание статьи

SQL Server – это система управления базами данных, разработанная Microsoft, которая позволяет хранить, обрабатывать и анализировать большие объемы данных. На практике она используется для управления корпоративными данными, построения отчетов и интеграции с приложениями.
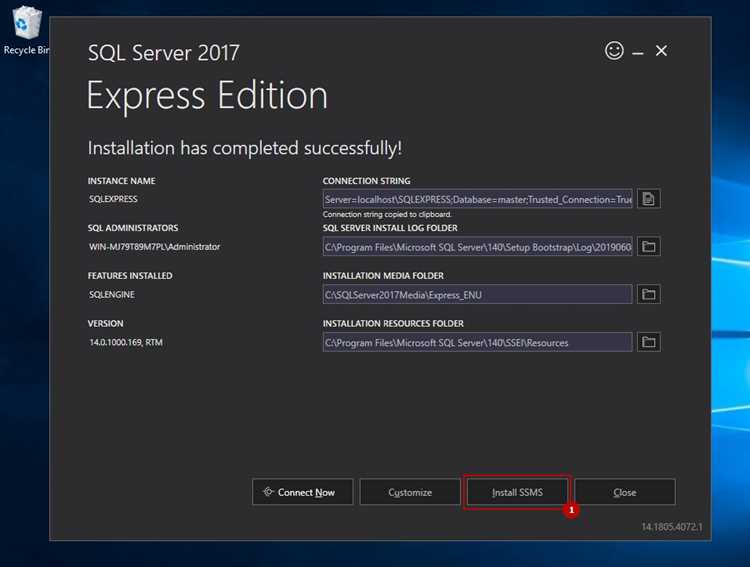
Начать работу с SQL Server стоит с установки версии Express для тестирования или Developer для полного функционала. После установки важно настроить аутентификацию, создать первую базу данных и подключиться к ней через SQL Server Management Studio (SSMS).
Создание таблиц требует точного выбора типов данных: INT для чисел, VARCHAR для текстовых строк, DATETIME для дат и времени. Правильное определение типов сокращает ошибки при вводе и ускоряет выполнение запросов.
Основные операции с данными включают вставку записей через INSERT, изменение через UPDATE и удаление через DELETE. Для выборки информации используется оператор SELECT с фильтрацией через WHERE, сортировкой ORDER BY и группировкой GROUP BY.
Для начинающих важно сразу освоить работу с первичными и внешними ключами, чтобы поддерживать целостность данных при связывании таблиц. Практика с простыми связями и тестовыми наборами данных поможет быстрее понять логику запросов и построение структур баз.
Установка и настройка SQL Server на Windows
Для начала работы с SQL Server необходимо скачать установочный пакет с официального сайта Microsoft. Для тестовых проектов подходит версия Express (ограничение на 10 ГБ на базу), для учебных и практических целей лучше использовать Developer, которая поддерживает все функции платной версии.
После запуска установщика выберите тип установки Basic для быстрого развертывания или Custom, чтобы самостоятельно задать путь установки, компоненты и порты. Рекомендуется оставлять стандартный порт 1433 для TCP/IP соединений.
Следующий шаг – настройка режима аутентификации. Для начинающих удобнее использовать Mixed Mode, который позволяет подключаться как с учетной записью Windows, так и с SQL-логином. Необходимо задать надежный пароль для учетной записи sa и добавить текущего пользователя Windows в администраторы SQL Server.
После установки стоит открыть SQL Server Configuration Manager и убедиться, что службы SQL Server и SQL Server Browser запущены. Для удаленных подключений нужно включить TCP/IP и при необходимости изменить порт на нестандартный, если стандартный уже используется.
Для работы с базами данных потребуется SQL Server Management Studio (SSMS). После установки SSMS подключитесь к серверу через localhost или имя компьютера, используя выбранный режим аутентификации. Это позволит создавать базы, управлять таблицами и выполнять первые запросы.
Создание и управление базами данных
Создание базы данных в SQL Server выполняется через SSMS или с помощью T-SQL. Для SSMS выберите Databases → New Database, укажите имя базы и путь хранения файлов данных (.mdf) и журналов транзакций (.ldf). Для T-SQL используется команда CREATE DATABASE имя_базы, после чего сервер автоматически создаст файлы по умолчанию.
Важно заранее определить размер и параметры автозаполнения файлов данных. Для небольших тестовых баз можно оставить значения по умолчанию, для крупных проектов рекомендуется задавать начальный размер и шаг роста, чтобы избежать фрагментации и замедления работы.
Управление базами включает изменение свойств, резервное копирование и восстановление. В SSMS это выполняется через Properties и Tasks. В T-SQL резервное копирование осуществляется командой BACKUP DATABASE имя_базы TO DISK = ‘путь_к_файлу.bak’, восстановление – RESTORE DATABASE имя_базы FROM DISK = ‘путь_к_файлу.bak’.
Для контроля использования ресурсов и производительности следует регулярно проверять размер базы, количество файлов, состояние транзакционного журнала и активные соединения. Настройка автоматических отчетов и мониторинг через SQL Server Agent позволяет оперативно реагировать на переполнение или сбои.
Создание таблиц и определение типов данных
Создание таблицы в SQL Server начинается с выбора структуры данных и типов столбцов. В SSMS используйте Databases → New Table или команду T-SQL CREATE TABLE имя_таблицы с перечислением столбцов и типов.
Основные типы данных и рекомендации по их использованию:
- INT – для целых чисел, оптимален для идентификаторов и счетчиков.
- BIGINT – для больших чисел свыше 2,1 млрд.
- VARCHAR(n) – для строк переменной длины, указывайте максимально допустимое количество символов.
- CHAR(n) – для фиксированной длины строк, полезно при одинаковой длине значений.
- DATETIME – для хранения даты и времени, поддерживает вычисления и сортировку.
- DECIMAL(p, s) – для чисел с фиксированной точкой, p – общая длина, s – количество знаков после запятой.
При проектировании таблиц важно:
- Определять первичный ключ через PRIMARY KEY для уникальной идентификации записей.
- Использовать NOT NULL для столбцов, где данные обязательны.
- Предусматривать внешние ключи FOREIGN KEY для связей между таблицами.
- Учитывать предполагаемый размер данных и задавать соответствующий тип для экономии ресурсов.
- Сразу планировать индексы на столбцах, по которым будут частые выборки.
После создания таблицы рекомендуется вставить несколько тестовых записей и проверить корректность типов данных, ограничений и связи с другими таблицами.
Добавление, обновление и удаление записей
Для вставки данных в таблицу используется команда INSERT INTO. Пример синтаксиса:
INSERT INTO имя_таблицы (столбец1, столбец2) VALUES (значение1, значение2);
Для массовой вставки можно перечислять несколько наборов значений через запятую. Важно проверять соответствие типов данных и наличие обязательных столбцов с NOT NULL.
Обновление существующих записей выполняется командой UPDATE. Пример:
UPDATE имя_таблицы SET столбец1 = новое_значение WHERE условие;
Без условия WHERE изменения затронут все строки, поэтому всегда проверяйте фильтр. Для изменения нескольких столбцов используйте запятую между присваиваниями.
Удаление записей происходит через DELETE FROM. Пример:
DELETE FROM имя_таблицы WHERE условие;
Опасно выполнять без WHERE, так как удалятся все строки. Для безопасной работы полезно сначала выполнить SELECT с тем же условием, чтобы убедиться, что удаляются только нужные записи.
Для контроля изменений рекомендуется использовать транзакции с BEGIN TRANSACTION и COMMIT/ROLLBACK, чтобы можно было отменить случайные операции и сохранить только корректные данные.
Использование операторов SELECT для выборки данных
Команда SELECT используется для извлечения данных из таблиц. Базовый синтаксис выглядит так:
SELECT столбец1, столбец2 FROM имя_таблицы;
Для выбора всех столбцов применяется символ *: SELECT * FROM имя_таблицы;. При работе с большими таблицами рекомендуется указывать конкретные столбцы для снижения нагрузки на сервер.
Можно применять вычисляемые поля, например: SELECT столбец1, столбец2 * 1.2 AS итог FROM имя_таблицы;, что позволяет сразу получать рассчитанные значения.
Для объединения данных из нескольких таблиц используется JOIN:
- INNER JOIN – возвращает строки, где совпадают значения ключей.
- LEFT JOIN – возвращает все строки из левой таблицы и совпадающие из правой.
- RIGHT JOIN – аналогично, но для правой таблицы.
Для ограничения количества возвращаемых строк используется TOP: SELECT TOP 10 * FROM имя_таблицы;. Это полезно для проверки данных или тестовых выборок без полной загрузки таблицы.
Фильтрация данных с помощью WHERE и условий

Для ограничения выборки используется оператор WHERE. Пример синтаксиса:
SELECT столбец1, столбец2 FROM имя_таблицы WHERE столбец1 = значение;
Можно применять различные сравнения: =, <>, >, <, >=, <=. Для диапазонов удобно использовать BETWEEN: WHERE дата BETWEEN ‘2025-01-01’ AND ‘2025-12-31’.
Для проверки принадлежности к набору значений используется IN: WHERE категория IN (‘A’, ‘B’, ‘C’). Для поиска по шаблону применяется LIKE с символами подстановки % и _: WHERE имя LIKE ‘Иван%’.
Объединение условий осуществляется через AND и OR. Скобки помогают управлять приоритетом: WHERE (столбец1 = 1 OR столбец2 = 2) AND столбец3 > 10.
Для работы с NULL используется IS NULL или IS NOT NULL: WHERE столбец4 IS NOT NULL. Это важно для корректной фильтрации незаполненных полей.
Сортировка и группировка данных в запросах
Для упорядочивания результатов используется оператор ORDER BY. Синтаксис:
SELECT столбец1, столбец2 FROM имя_таблицы ORDER BY столбец1 ASC, столбец2 DESC;
По умолчанию сортировка выполняется по возрастанию (ASC). Для убывающего порядка используется DESC. Можно сортировать сразу по нескольким столбцам, задавая приоритет через порядок перечисления.
Группировка данных позволяет агрегировать значения с помощью GROUP BY. Пример:
SELECT категория, COUNT(*) AS количество FROM имя_таблицы GROUP BY категория;
Часто применяются агрегатные функции:
- COUNT() – подсчет количества записей.
- SUM() – сумма числовых значений.
- AVG() – среднее значение.
- MIN() и MAX() – минимальные и максимальные значения.
Для фильтрации агрегированных данных используется HAVING вместо WHERE. Пример:
SELECT категория, SUM(продажи) AS сумма_продаж FROM таблица GROUP BY категория HAVING SUM(продажи) > 1000;
Комбинирование GROUP BY с ORDER BY позволяет сначала сгруппировать данные, затем отсортировать агрегированные результаты для наглядной аналитики.
Создание простых связей между таблицами
Связи между таблицами обеспечивают целостность данных и позволяют объединять информацию из разных источников. На практике используются первичные ключи и внешние ключи.
Пример создания двух таблиц с простой связью:
| Таблица Customers | Таблица Orders |
|---|---|
|
CustomerID INT PRIMARY KEY, Name VARCHAR(50), Email VARCHAR(50) |
OrderID INT PRIMARY KEY, CustomerID INT FOREIGN KEY REFERENCES Customers(CustomerID), OrderDate DATETIME |
В этом примере столбец CustomerID в таблице Orders ссылается на первичный ключ таблицы Customers. Это гарантирует, что каждая запись заказа принадлежит существующему клиенту.
Для вставки данных сначала добавляют записи в таблицу Customers, затем в таблицу Orders. При удалении клиента с существующими заказами рекомендуется использовать ON DELETE CASCADE или проверять наличие связанных записей, чтобы избежать нарушения ссылочной целостности.
Для отображения связанных данных применяется INNER JOIN:
SELECT c.Name, o.OrderID, o.OrderDate FROM Customers c INNER JOIN Orders o ON c.CustomerID = o.CustomerID;
Это позволяет получать список заказов с информацией о клиентах без дублирования данных.
Вопрос-ответ:
Как установить SQL Server на Windows и подключиться к нему?
Сначала скачайте версию SQL Server Express или Developer с официального сайта Microsoft. Запустите установщик и выберите тип установки: Basic для быстрого развертывания или Custom для настройки пути установки и компонентов. Рекомендуется включить Mixed Mode для возможности подключения через учетную запись Windows и SQL-логин. После установки откройте SQL Server Management Studio и подключитесь к серверу через localhost или имя компьютера, используя выбранный режим аутентификации.
Как правильно создать таблицу и выбрать типы данных для столбцов?
При создании таблицы определите для каждого столбца подходящий тип данных: INT для чисел, BIGINT для больших чисел, VARCHAR(n) для строк переменной длины, CHAR(n) для фиксированной длины, DATETIME для даты и времени, DECIMAL(p, s) для чисел с фиксированной точкой. Обязательно задайте первичный ключ через PRIMARY KEY и используйте NOT NULL для обязательных полей. Если таблица будет связана с другой, добавьте внешний ключ через FOREIGN KEY.
Какие операторы использовать для выборки данных и фильтрации?
Для выборки данных применяется оператор SELECT, с указанием конкретных столбцов или * для всех. Для фильтрации используется WHERE с условиями сравнения (=, >, < и др.), BETWEEN для диапазонов, IN для набора значений, LIKE для поиска по шаблону и IS NULL/IS NOT NULL для пустых полей. Условия можно объединять через AND и OR, скобки задают приоритет выполнения.
Как создать связь между двумя таблицами и использовать ее в запросах?
Создайте первичный ключ в первой таблице, например CustomerID в Customers. В таблице Orders добавьте столбец CustomerID с внешним ключом, ссылающимся на первичный ключ: FOREIGN KEY REFERENCES Customers(CustomerID). Для выборки связанных данных используйте INNER JOIN: SELECT c.Name, o.OrderID, o.OrderDate FROM Customers c INNER JOIN Orders o ON c.CustomerID = o.CustomerID; Это позволяет получить список заказов с данными клиентов без дублирования информации.