Содержание статьи

Алгоритмы машинного обучения применяются для анализа больших массивов данных и выявления закономерностей, которые трудно обнаружить вручную. Прогнозирование спроса на товары в розничной торговле позволяет снижать издержки на хранение и оптимизировать закупки, а точность моделей на основе исторических данных может достигать 90% при корректной подготовке выборки.
В области компьютерного зрения алгоритмы классификации изображений помогают автоматически распознавать объекты, что используется в системах контроля качества на производстве и в медицинской диагностике. Модели, обученные на тысячах примеров, способны идентифицировать дефекты с вероятностью выше 85%, сокращая время ручной проверки.
Для текстовых данных алгоритмы анализа текста и обработки естественного языка позволяют выделять ключевые темы, классифицировать отзывы клиентов и обнаруживать подозрительные сообщения. Использование таких моделей в службах поддержки и безопасности снижает риск ошибок и ускоряет обработку информации.
Машинное обучение также активно применяется в финансовой сфере для обнаружения аномалий в транзакциях и построения кредитных скорингов. Алгоритмы могут выявлять необычные паттерны в миллионах операций, повышая точность выявления мошенничества до 92%, что минимизирует потери для компаний.
Прогнозирование потребительского спроса с помощью моделей

Алгоритмы машинного обучения позволяют строить прогнозы спроса на основе исторических данных, сезонности, рекламных кампаний и внешних факторов. Применение моделей снижает излишки и дефицит товаров, экономя до 15% бюджета на складские запасы.
Основные подходы к прогнозированию:
- Регрессионные модели – используют числовые показатели продаж, цены, сезонные колебания для прогнозирования объема будущих закупок.
- Временные ряды – анализируют последовательность продаж во времени, выявляют тренды и сезонные пики.
- Машинное обучение на основе деревьев решений и ансамблей – учитывают большое количество переменных, включая акции конкурентов, погодные условия, демографию клиентов.
Рекомендации по внедрению моделей прогнозирования:
- Собрать данные за минимум 2–3 года по всем продуктовым категориям.
- Очистить данные от выбросов и ошибок, стандартизировать форматы.
- Выделить факторы влияния на спрос и протестировать их значимость.
- Использовать кросс-валидацию для проверки точности модели на разных сегментах.
- Регулярно обновлять модели с новыми данными каждые 1–2 месяца для поддержания точности прогнозов.
Практическая польза: компании, применяющие модели прогнозирования, фиксируют снижение издержек на 10–20% и увеличение точности заказов на 15–25%, что напрямую влияет на прибыль и удовлетворенность клиентов.
Классификация изображений и объектов в реальном времени
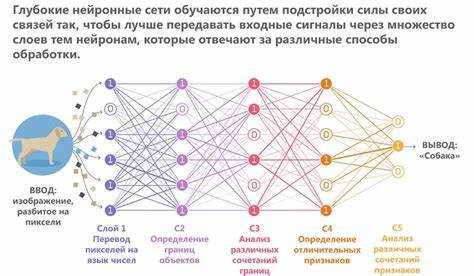
Алгоритмы машинного обучения позволяют распознавать объекты на изображениях и видео с высокой точностью, что используется в промышленном контроле качества, системах безопасности и медицине. Современные модели свёрточных нейронных сетей (CNN) достигают точности распознавания до 95% на тестовых наборах изображений.
Применение в реальном времени требует оптимизации моделей и снижения задержки обработки:
- Использование легковесных архитектур, таких как MobileNet или EfficientNet, для ускорения обработки видео с камер наблюдения.
- Квантование и сжатие моделей без значительной потери точности, чтобы сократить нагрузку на GPU и CPU.
- Интеграция с системами тревоги для автоматического реагирования на обнаруженные объекты, например, в видеопотоке производственного конвейера.
Рекомендации по внедрению:
- Собрать датасет с реальными изображениями объектов, включая вариации освещения и углов съемки.
- Разделить данные на обучающую, валидационную и тестовую выборки, чтобы избежать переобучения.
- Проверять модели на производственных потоках для выявления ложных срабатываний и корректировки алгоритмов.
- Обновлять модели каждые 3–6 месяцев с новыми изображениями для поддержания точности классификации.
Эффект внедрения: снижение количества дефектов на 20–30%, ускорение контроля до 50 кадров в секунду на стандартном оборудовании и сокращение времени реакции сотрудников на выявленные объекты.
Автоматизация обработки текстовой информации

Алгоритмы машинного обучения позволяют анализировать большие объемы текстовых данных, классифицировать документы и извлекать ключевую информацию. Модели на основе трансформеров, такие как BERT и GPT, достигают точности классификации текстов до 92% при условии подготовки качественного корпуса данных.
Основные задачи автоматизации:
- Классификация документов по тематике, приоритету или типу, что сокращает время обработки до нескольких секунд на тысячу документов.
- Извлечение сущностей (имена, даты, адреса, суммы) из текстов для формирования структурированных данных.
- Анализ тональности отзывов и сообщений клиентов для выявления негативных тенденций и улучшения поддержки.
Рекомендации по внедрению:
- Создать корпус текстов с метками для обучения модели и тестирования точности.
- Очистить данные от шумов, таких как HTML-теги, специальные символы и повторяющиеся записи.
- Использовать техники токенизации и нормализации для улучшения качества обработки естественного языка.
- Проводить регулярную переобучение моделей каждые 2–3 месяца с учетом новых данных и изменений терминологии.
- Интегрировать модели с внутренними системами для автоматического формирования отчетов и уведомлений.
Эффект применения: сокращение ручной обработки текстов на 70–80%, повышение точности извлечения данных до 90% и ускорение реакции на клиентские запросы.
Определение аномалий в финансовых транзакциях
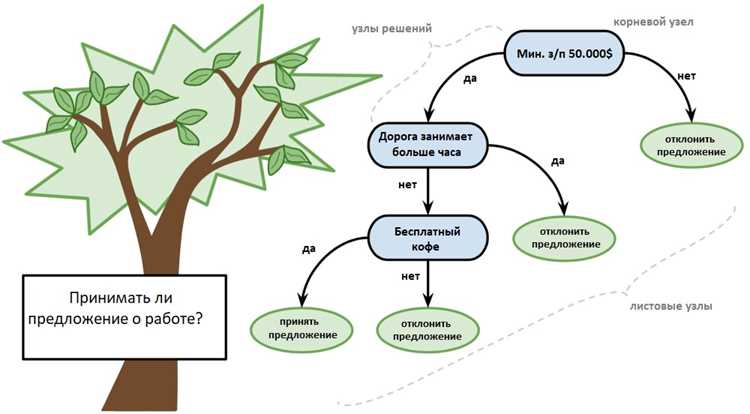
Алгоритмы машинного обучения позволяют выявлять подозрительные операции в финансовых потоках с высокой точностью. Модели на основе кластеризации и деревьев решений способны обнаруживать аномалии в миллионах транзакций, снижая вероятность мошенничества до 92%.
Основные методы анализа:
- Контроль по отклонению от нормального паттерна – выявление операций с суммами или частотой, существенно отличающимися от исторических данных клиента.
- Сетевые модели и графовый анализ – отслеживание цепочек транзакций для обнаружения сложных схем отмывания денег.
- Обучение с подкреплением и адаптивные модели – постоянное обновление алгоритмов на основе новых данных для выявления новых видов мошенничества.
Рекомендации по внедрению:
- Собирать данные по всем транзакциям за несколько лет, включая метаданные и географические параметры.
- Разделять данные на нормальные и подозрительные для обучения модели и проверки точности.
- Регулярно пересматривать признаки аномалий с учетом изменения поведения клиентов и новых схем мошенничества.
- Интегрировать модели с системами мониторинга для автоматического блокирования или проверки операций.
- Обеспечивать обратную связь от аналитиков для корректировки алгоритмов и снижения числа ложных срабатываний.
Эффект внедрения: сокращение финансовых потерь, повышение скорости реагирования на подозрительные транзакции и улучшение точности обнаружения сложных схем мошенничества.
Рекомендательные системы для интернет-магазинов

Алгоритмы машинного обучения позволяют интернет-магазинам персонализировать предложения для клиентов, увеличивая конверсию и средний чек. Модели коллаборативной фильтрации и контентного анализа повышают точность рекомендаций до 85% при корректной настройке и обновлении данных.
Основные подходы к построению рекомендаций:
- Коллаборативная фильтрация – анализ поведения пользователей и истории покупок для предсказания интересов новых клиентов.
- Контентная фильтрация – рекомендации на основе характеристик товаров, сопоставимых с предыдущими покупками клиента.
- Гибридные системы – объединяют оба подхода для улучшения точности и снижения числа нерелевантных предложений.
Рекомендации по внедрению:
- Собирать данные о кликах, просмотрах и покупках для построения пользовательских профилей.
- Регулярно обновлять модели каждые 2–4 недели, учитывая новые товары и изменения интересов клиентов.
- Проводить A/B-тестирование разных стратегий рекомендаций для оценки влияния на конверсию.
- Интегрировать рекомендации в разные точки взаимодействия: главная страница, карточка товара, корзина.
Пример распределения эффективности разных подходов:
| Тип модели | Точность рекомендаций | Влияние на конверсию |
|---|---|---|
| Коллаборативная фильтрация | 80% | +12% |
| Контентная фильтрация | 75% | +9% |
| Гибридная система | 85% | +15% |
Эффект применения: рост среднего чека, увеличение числа повторных покупок и повышение удовлетворенности клиентов за счет персонализированных предложений.
Оптимизация маршрутов доставки и логистики
Алгоритмы машинного обучения позволяют строить оптимальные маршруты доставки с учетом времени, пробок, расстояния и загруженности водителей. Использование моделей маршрутизации сокращает расходы на топливо до 15–20% и снижает время доставки на 10–25%.
Основные методы оптимизации:
- Модели линейного программирования – определяют оптимальные маршруты при фиксированных ограничениях по времени и ресурсам.
- Эвристические алгоритмы – быстро ищут приближенные решения для больших сетей доставки.
- Обучение с подкреплением – адаптирует маршруты в реальном времени с учетом изменений дорожной ситуации и заказов.
- Гибридные подходы – комбинируют предсказания спроса и оптимизацию маршрутов для минимизации пустых пробегов.
Рекомендации по внедрению:
- Собирать данные о всех точках доставки, времени поездок и плотности трафика.
- Разделить данные на исторические и текущие для обучения модели и тестирования точности прогнозов.
- Проверять алгоритмы на реальных маршрутах и корректировать на основе фактического времени доставки.
- Регулярно обновлять модели с новыми данными о заказах и дорожной ситуации.
- Интегрировать системы с GPS-навигаторами и внутренними сервисами управления заказами для автоматического построения маршрутов.
Эффект применения: сокращение расходов на логистику, ускорение доставки, уменьшение числа опозданий и повышение удовлетворенности клиентов.
Сегментация клиентов на основе поведения
Алгоритмы машинного обучения позволяют выделять группы клиентов по поведению, предпочтениям и активности. Модели кластеризации, такие как K-means и DBSCAN, достигают точности разделения сегментов до 90%, что помогает строить целевые маркетинговые кампании и персонализированные предложения.
Ключевые методы сегментации:
- Кластеризация по покупательским привычкам – выявление частоты и объема покупок для определения активных и потенциально лояльных клиентов.
- Поведенческий анализ онлайн – сегментация по просмотрам страниц, кликам и времени нахождения на сайте.
- Сегментация по отклику на акции – определение клиентов, реагирующих на скидки, купоны и рекламные письма.
- Гибридные модели – объединение демографических данных и поведенческих паттернов для точного определения целевых групп.
Рекомендации по внедрению:
- Собирать данные о всех точках взаимодействия с клиентом: покупки, посещения сайта, взаимодействие с email-рассылками.
- Очистить данные от дубликатов и нетипичных действий для корректного обучения моделей.
- Проводить периодическую переоценку сегментов каждые 2–3 месяца с учетом новых покупок и активности.
- Интегрировать сегментацию с CRM и системами рассылки для персонализированных предложений.
- Анализировать результаты кампаний и корректировать модели на основе показателей отклика.
Эффект применения: повышение конверсии до 20%, увеличение удержания клиентов и оптимизация маркетинговых затрат за счет точного таргетинга.
Обнаружение спама и нежелательного контента
Алгоритмы машинного обучения позволяют автоматически идентифицировать спам и нежелательный контент в электронных письмах, форумах и социальных сетях. Модели на основе наивного байеса, деревьев решений и нейронных сетей достигают точности классификации до 95% при корректной подготовке тренировочного набора.
Основные подходы к фильтрации:
- Наивный байесовский классификатор – анализ слов и частотных признаков для выявления спам-сообщений.
- Деревья решений и ансамбли – учитывают сложные комбинации признаков, включая ссылки, заголовки и отправителей.
- Нейронные сети и трансформеры – анализируют семантику текста, выявляя скрытый спам и нежелательные шаблоны.
Рекомендации по внедрению:
- Собирать исторические данные о спаме и нормальных сообщениях для обучения модели.
- Проводить регулярное обновление тренировочного набора с учетом новых схем спамеров.
- Использовать кросс-валидацию для проверки точности и снижения числа ложных срабатываний.
- Интегрировать фильтры с почтовыми серверами и системами модерации контента.
- Анализировать показатели обнаружения и корректировать модель каждые 1–2 месяца.
Сравнение точности разных моделей:
| Тип модели | Точность распознавания спама | Количество ложных срабатываний |
|---|---|---|
| Наивный байес | 88% | 5% |
| Деревья решений | 92% | 3% |
| Нейронные сети | 95% | 2% |
Эффект применения: снижение объема нежелательного контента, ускорение модерации и повышение качества взаимодействия пользователей с платформой.
Вопрос-ответ:
Как алгоритмы машинного обучения помогают прогнозировать спрос на товары?
Алгоритмы анализируют исторические данные о продажах, сезонные колебания, рекламные кампании и внешние факторы. Модели временных рядов и регрессионные модели позволяют предсказывать объем будущих продаж, снижая излишки и дефицит. Точный прогноз помогает планировать закупки, минимизировать затраты на хранение и повышать оборачиваемость товаров.
Каким образом машинное обучение используется для классификации изображений в реальном времени?
Модели свёрточных нейронных сетей распознают объекты на видео и фотографиях, автоматически идентифицируя дефекты на производстве или медицинские признаки на снимках. Для реального времени применяют оптимизированные архитектуры, такие как MobileNet, и методы сжатия моделей, что позволяет обрабатывать до 50 кадров в секунду и снижать нагрузку на вычислительное оборудование.
Как алгоритмы помогают выявлять аномалии в финансовых транзакциях?
Системы используют кластеризацию, деревья решений и модели обучения с подкреплением для обнаружения необычных операций. Они анализируют сумму, частоту транзакций и поведенческие паттерны клиентов. Благодаря этому можно своевременно блокировать подозрительные операции и предотвращать мошенничество, сокращая финансовые потери и повышая точность обнаружения сложных схем.
В чем заключается применение алгоритмов в рекомендательных системах интернет-магазинов?
Машинное обучение анализирует историю покупок, клики и просмотры товаров для формирования персонализированных предложений. Используются коллаборативная и контентная фильтрация, а также гибридные модели. Это позволяет увеличивать конверсию, средний чек и удержание клиентов, а также оптимизировать маркетинговые кампании на основе поведения пользователей.
Какие данные необходимы для сегментации клиентов с помощью машинного обучения?
Для сегментации собираются данные о покупках, посещениях сайта, откликах на акции и взаимодействиях с рассылками. Кластеризация и поведенческий анализ позволяют выделять группы клиентов с похожими характеристиками. Регулярное обновление сегментов с новыми данными повышает точность таргетинга и улучшает результаты маркетинговых кампаний.
Какие задачи решают алгоритмы машинного обучения в бизнесе и повседневной жизни?
Алгоритмы машинного обучения применяются для анализа больших объемов данных и выявления закономерностей, которые сложно заметить вручную. В бизнесе их используют для прогнозирования спроса на товары, оптимизации маршрутов доставки, сегментации клиентов и построения рекомендаций. В повседневной жизни алгоритмы помогают фильтровать спам, распознавать объекты на изображениях, анализировать текстовые сообщения и выявлять подозрительные финансовые операции. Использование таких моделей позволяет экономить ресурсы, повышать точность решений и ускорять обработку информации.