Содержание статьи

Скрытые символы в тексте – это невидимые или нестандартные символы, которые могут нарушать структуру документа, мешать поисковой оптимизации и вызывать ошибки при обработке данных. К числу наиболее распространённых относятся неразрывные пробелы, символы табуляции, скрытые переносы строк и невидимые Юникод-символы, такие как ZERO WIDTH SPACE (U+200B) или LEFT-TO-RIGHT MARK (U+200E).
Игнорирование этих символов может приводить к некорректному отображению текста на веб-страницах, сбоям при импорте данных в базы и ошибкам при проверке орфографии. Для выявления скрытых символов рекомендуется использовать текстовые редакторы с поддержкой отображения невидимых символов, а также специализированные утилиты, например, онлайн-валидаторы Юникода или скрипты на Python с регулярными выражениями.
Проверка текста на ошибки должна включать несколько этапов: автоматическую проверку орфографии и пунктуации, выявление нестандартных пробелов и символов, а также анализ структуры строк и кодировки файла. Важно сохранять текст в единой кодировке UTF-8 без BOM, чтобы исключить появление скрытых управляющих символов при переносе текста между системами.
Регулярное проведение таких проверок позволяет обеспечить корректную обработку текстовой информации в приложениях, веб-сервисах и базах данных, а также повышает точность поиска и качество публикаций. Рекомендуется интегрировать проверку на скрытые символы в стандартный процесс редактирования и публикации материалов для предотвращения ошибок на ранних стадиях.
Как обнаружить невидимые пробелы и спецсимволы
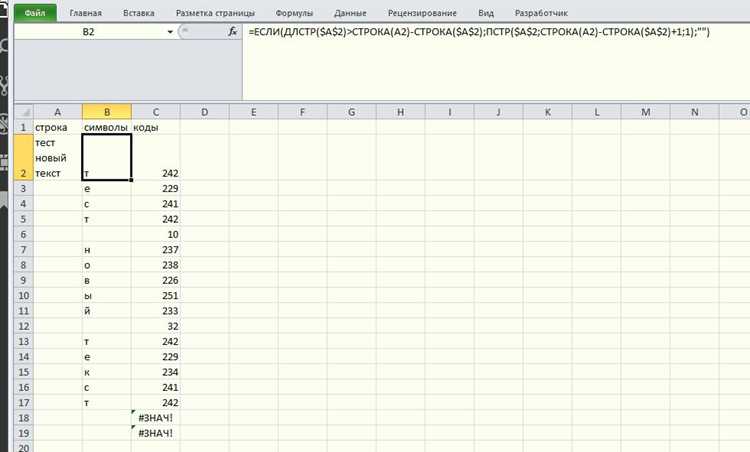
Невидимые символы включают пробелы разной ширины (например, non-breaking space, U+00A0), табуляции, нулевые символы (NULL, U+0000) и управляющие коды (U+0001–U+001F). Они могут нарушать обработку текста, вызывать ошибки в базах данных и сбои при копировании.
Для обнаружения невидимых пробелов эффективен поиск по Unicode-кодам. В текстовых редакторах, поддерживающих регулярные выражения, можно использовать шаблон [\u2000-\u200B\u00A0] для всех нестандартных пробелов.
Табуляции и переходы строк различаются по платформе: LF (U+000A), CR (U+000D), CRLF. Их легко выявить через функции «Показать непечатаемые символы» в редакторах, таких как Notepad++, Sublime Text или Visual Studio Code.
Скрытые символы часто появляются при копировании из веб-страниц или PDF. Для их выявления полезно:
- Вставлять текст в редактор с подсветкой Unicode;
- Использовать онлайн-инструменты, показывающие коды символов;
- Прогонять текст через скрипт на Python:
[ord(c) for c in text]для анализа кодов.
Для массовой очистки можно применять замену по регулярным выражениям. Например, [\u2000-\u206F\u2E00-\u2E7F]+ удаляет большинство скрытых пробелов и знаков пунктуации, которые не видны визуально.
Важно учитывать, что символы Zero Width Space (U+200B) и другие невидимые маркеры могут влиять на сравнение строк и хэширование. Их стоит удалять перед обработкой данных в базах или перед публикацией.
Регулярная проверка текстов с помощью редакторов, скриптов и онлайн-анализаторов снижает вероятность ошибок в коде, неправильной верстке и сбоях при импорте данных. Стратегия должна включать выявление, маркировку и автоматическую очистку скрытых символов.
Методы проверки текста на невидимые переносы строк

Для выявления таких переносов удобно использовать текстовые редакторы с поддержкой отображения скрытых символов. В Notepad++ включение опции Show All Characters визуализирует символы CR, LF и невидимые разделители.
В среде Microsoft Word проверка проводится через меню «Показать/Скрыть ¶». Хотя Word отображает стандартные переносы абзацев, специальные Unicode-разделители могут остаться невидимыми, поэтому дополнительно рекомендуется использовать функцию «Найти» с регулярным выражением [\u2028\u2029].
Автоматизированные методы включают сканирование текста с помощью скриптов на Python или JavaScript. Для Python используется функция re.findall(r'[\u2028\u2029]’, text), которая возвращает все позиции невидимых переносов. Такой подход позволяет быстро очистить большие массивы данных.
В случае веб-контента можно применять инспекторы браузеров. В Chrome DevTools символы переноса строки в элементах <pre> и <textarea> выявляются через вкладку «Elements», где невидимые символы отображаются как пустые, но с позицией курсора.
Для массовой очистки текста рекомендуется использовать регулярные выражения в редакторах с поддержкой RegEx. Например, замена [\u2028\u2029] на пробел или обычный перенос строки обеспечивает совместимость с большинством систем обработки.
Контроль качества текстового контента включает периодические проверки скриптами и визуальный аудит. Совмещение методов: инспектор, редактор с отображением скрытых символов и автоматизированные сканеры, позволяет полностью исключить ошибки, вызванные невидимыми переносами строк.
Использование онлайн-инструментов для поиска ошибок в тексте

Современные онлайн-сервисы для проверки текста позволяют выявлять орфографические, грамматические и пунктуационные ошибки за считанные секунды. Среди них выделяются такие платформы, как «Орфограммка», «Text.ru» и «LanguageTool», которые поддерживают как русский, так и английский языки.
При работе с текстом важно учитывать, что многие сервисы могут обнаруживать не только классические ошибки, но и скрытые символы, например, невидимые пробелы или нестандартные переносы строк. Это особенно актуально для копипасты из PDF или веб-страниц.
Рекомендуется использовать комплексный подход: сначала проверять текст на орфографию, затем на стилистические и логические ошибки. LanguageTool, например, выделяет повторяющиеся слова, неправильное согласование падежей и даже частые типографические ошибки.
- Загрузка текста через буфер обмена или файл формата .docx, .txt.
- Автоматическая подсветка ошибок с предложением вариантов исправления.
- Отчет о повторениях, сложных предложениях и длинных абзацах для улучшения читаемости.
Для сайтов и блогов полезны онлайн-инструменты с API-интеграцией. Например, Text.ru предоставляет возможность подключить проверку текста прямо в CMS, что сокращает время редактирования и повышает качество публикаций.
Важный аспект – регулярное обновление словарей и правил сервиса. Некоторые платформы позволяют добавлять пользовательские словари, что актуально для профессиональной терминологии или имен собственных.
Резюмируя, использование онлайн-инструментов повышает точность и скорость корректировки текста. Оптимальная стратегия – сочетать несколько сервисов, контролировать скрытые символы и периодически проверять результат вручную для предотвращения автоматических ложных срабатываний.
Как выявлять скрытые символы в копированном контенте

Для точного обнаружения скрытых символов используйте текстовые редакторы с функцией отображения непечатаемых символов, такие как Notepad++ или Sublime Text. Обращайте внимание на неразрывные пробелы (U+00A0), нулевые символы (U+0000) и символы направления текста (U+200E, U+200F), которые часто внедряются при копировании из PDF или веб-страниц. Регулярные выражения помогут быстро идентифицировать нестандартные коды: например, паттерн [\u0000-\u001F\u200B-\u200F\uFEFF] ищет управляющие и невидимые пробелы.
Дополнительно рекомендуется использовать онлайн-инструменты анализа текста, которые подсвечивают невидимые символы и дубли пробелов. При массовой проверке контента эффективен экспорт текста в формат UTF-8 и последующая фильтрация с помощью скриптов Python или JavaScript, удаляющих символы с кодами выше 127 и управляющие последовательности. Такой подход минимизирует ошибки при публикации и обеспечивает корректное отображение текста во всех браузерах и редакторах.
Проверка кодировки текста для исключения скрытых символов
Скрытые символы часто возникают при конвертации документов между разными кодировками, например, из Windows-1251 в UTF-8. Даже невидимые символы, такие как нулевой байт, BOM или неразрывные пробелы, могут нарушить работу парсеров и скриптов. Для их выявления рекомендуется использовать утилиты `iconv` или `chardet`, которые определяют фактическую кодировку файла и отмечают несовпадения с ожидаемой.
После определения кодировки текст следует нормализовать. В UTF-8 рекомендуется применять NFC или NFKC нормализацию, которая объединяет разрозненные символы с диакритикой и убирает избыточные байты. Для скриптов на Python эффективным методом является чтение через `open(filename, encoding=’utf-8-sig’)` с последующим фильтром `str.isprintable()`, чтобы автоматически исключить управляющие и невидимые символы, не влияющие на визуальное отображение текста.
При массовой обработке документов полезно интегрировать проверку в CI/CD или ETL-процессы. Скрипт должен сначала детектировать кодировку, затем применять нормализацию и сохранять результат с явным указанием UTF-8 без BOM. Это предотвращает скрытые ошибки при передаче данных между системами и обеспечивает корректное отображение символов во всех приложениях, включая веб-интерфейсы и базы данных, где некорректные байты могут вызывать падения или некорректную индексацию.
Автоматическая очистка текста от непечатаемых символов

Непечатаемые символы, такие как нулевой байт, управляющие символы Unicode и невидимые пробелы (U+200B, U+FEFF), часто проникают в текст через копирование из веб-страниц или документов. Их наличие нарушает обработку данных и форматирование. Автоматическая очистка текста позволяет системно удалять эти элементы без ручной проверки каждого фрагмента.
Современные алгоритмы очистки используют регулярные выражения для идентификации непечатаемых символов. Например, шаблон [\x00-\x1F\x7F\u200B\uFEFF] охватывает большинство скрытых управляющих символов ASCII и Unicode. Интеграция такого подхода в конвейеры обработки данных снижает вероятность ошибок при экспорте в CSV, XML или JSON.
Эффективная автоматическая очистка предусматривает этап предварительной нормализации текста. Рекомендуется применять Unicode Normalization Form C (NFC) для объединения составных символов и исключения скрытых вариаций. Это особенно важно при работе с многоязычными документами и текстом из PDF, где визуально идентичные символы могут иметь разный код.
Для оценки эффективности очистки полезно вести статистику удаления символов. Пример таблицы мониторинга:
| Тип символа | Количество найдено | Удалено автоматически |
|---|---|---|
| Нулевой байт (U+0000) | 45 | 45 |
| Невидимый пробел (U+200B) | 120 | 120 |
| Форматирующие символы (U+202A–U+202E) | 17 | 17 |
| Непечатаемые ASCII (0x01–0x1F) | 89 | 89 |
При автоматической очистке стоит учитывать сохранение структурных символов, например, табуляций (U+0009) и символов перевода строки (U+000A, U+000D), если они необходимы для форматирования. Их удаление может разрушить таблицы или списки в исходном тексте, поэтому фильтры должны быть селективными.
Интеграция автоматической очистки в текстовые редакторы, системы управления контентом и API обработки данных повышает стабильность и предсказуемость обработки текста. Регулярная проверка и обновление правил удаления непечатаемых символов позволяет предотвращать накопление скрытых ошибок, минимизируя потребность в ручной коррекции данных.
Вопрос-ответ:
Как определить наличие скрытых символов в документе?
Скрытые символы могут быть незаметны визуально, но влиять на форматирование или работу текста. Чтобы их выявить, можно включить отображение непечатаемых символов в текстовом редакторе или использовать специализированные утилиты для анализа файла. Часто такие символы появляются при копировании текста из разных источников или при работе с разными кодировками.
Почему в тексте появляются странные пробелы или переносы?
Странные пробелы и переносы обычно связаны с различиями кодировок или с тем, что в тексте присутствуют невидимые символы, такие как неразрывные пробелы, табуляции или символы переноса строки. Их можно обнаружить, включая отображение всех символов в редакторе или проверяя текст через онлайн-сервисы, которые показывают скрытые знаки.
Можно ли автоматически исправить ошибки, связанные с невидимыми символами?
Да, некоторые программы и онлайн-сервисы умеют автоматически удалять или заменять скрытые символы, приводя текст к «чистому» виду. Однако важно проверять результат, так как иногда автоматическая замена может изменить структуру форматирования, особенно в сложных документах с таблицами или списками.
Как скрытые символы влияют на работу программ, обрабатывающих текст?
Невидимые символы могут вызывать ошибки при копировании текста в базы данных, при проверке орфографии, при создании PDF-файлов или при публикации на сайтах. Например, лишние символы переноса строки могут ломать верстку, а невидимые пробелы — мешать корректной сортировке или поиску слов в документе.
Какие инструменты помогают выявлять ошибки в тексте и скрытые символы?
Существуют текстовые редакторы с функцией отображения всех символов, специальные утилиты для анализа документов, а также онлайн-сервисы, показывающие невидимые знаки. Также можно использовать скрипты для поиска необычных кодов символов или конвертации текста в стандартную кодировку, чтобы избавиться от посторонних элементов.