Содержание статьи

Ввод данных в базу данных – это не абстрактный процесс, а конкретный набор операций, от которых зависит корректность запросов, отчётов и бизнес-логики. Ошибки на этом этапе приводят к дублированию записей, нарушению связей между таблицами и некорректной аналитике. Поэтому важно понимать, каким способом данные попадают в базу и какие ограничения нужно учитывать заранее.
На практике данные поступают из разных источников: ручной ввод через SQL-запросы, загрузка файлов формата CSV или XLSX, отправка значений из веб-форм, синхронизация с API сторонних сервисов. Каждый способ требует своей подготовки: настройки типов полей, проверки кодировок, обработки пустых значений и приведения форматов дат и чисел.
Отдельного внимания заслуживает массовый ввод данных. При работе с тысячами и миллионами строк стандартные INSERT-запросы создают избыточную нагрузку на сервер. Для таких задач применяются специальные механизмы импорта, которые работают напрямую с файловой системой и журналами транзакций, но при этом требуют строгого соответствия структуры файла схеме таблицы.
Независимо от выбранного способа, ввод данных всегда сопровождается проверками: уникальность значений, соответствие внешним ключам, допустимые диапазоны чисел. Грамотно выстроенный процесс ввода снижает количество ошибок на следующих этапах и упрощает поддержку базы данных при росте объёма информации.
Ввод данных в базу данных: примеры и способы
Способ ввода данных в базу данных напрямую зависит от источника информации и объёма записей. Для единичных операций чаще применяются SQL-запросы, для потоковых и массовых – механизмы импорта или автоматическая передача данных между системами. Выбор метода влияет на нагрузку на сервер, требования к валидации и сложность обработки ошибок.
Ручной ввод выполняется с помощью операторов INSERT или INSERT INTO … VALUES. Такой подход подходит для тестирования, администрирования и добавления небольшого количества строк. На этом этапе часто возникают ошибки несоответствия типов данных, нарушения ограничений NOT NULL и конфликтов уникальных индексов.
Для загрузки данных из файлов применяются форматы CSV и XLSX. Перед импортом требуется проверить порядок столбцов, кодировку и разделители. При наличии заголовков строка с названиями полей либо удаляется, либо пропускается настройками импорта. Неподготовленные файлы приводят к смещению данных по колонкам и ошибкам преобразования.
В веб-приложениях данные поступают через формы и передаются на сервер по HTTP. Здесь ввод сопровождается серверной проверкой: фильтрацией пользовательского ввода, приведением типов и защитой от SQL-инъекций. Значения из формы редко записываются напрямую – чаще они проходят через слой обработки и только затем сохраняются в таблицах.
Интеграция с внешними сервисами строится через API. Данные поступают в формате JSON или XML и преобразуются в структуру базы данных. При таком способе необходимо учитывать частоту запросов, дублирование записей и синхронизацию изменений, особенно при обновлении существующих строк.
| Способ ввода | Источник данных | Типичные задачи | Особенности |
|---|---|---|---|
| SQL INSERT | Администратор, разработчик | Добавление отдельных записей | Подходит для малых объёмов, требует ручной проверки |
| Импорт CSV/XLSX | Файлы | Перенос данных из таблиц и отчётов | Нужна проверка структуры и кодировки |
| Веб-формы | Пользовательский ввод | Регистрация, заказы, анкеты | Обязательна серверная фильтрация данных |
| API | Сторонние сервисы | Синхронизация и обмен данными | Требует обработки ошибок и дубликатов |
Практика показывает, что стабильная работа базы данных достигается не выбором одного способа, а сочетанием нескольких подходов с учётом объёма, источника и частоты поступления данных.
Ручной ввод записей через SQL INSERT с разбором типовых ошибок
Ручной ввод через INSERT применяется для точечного добавления строк при администрировании и проверке логики таблиц. Запрос должен строго соответствовать схеме: порядок столбцов, допустимые значения и ограничения проверяются СУБД до фактической записи.
Рекомендуется всегда указывать список полей, даже если вставляются значения во все колонки. Это упрощает контроль запроса и предотвращает ошибки после изменения структуры таблицы.
- пропуск обязательного поля с ограничением NOT NULL;
- вставка строки в числовой столбец без приведения типа;
- дублирование значения в поле с уникальным индексом;
- некорректный формат даты или времени;
- попытка вставки внешнего ключа без связанной записи.
Ошибки форматов часто возникают при работе с датами. Для большинства СУБД используется формат YYYY-MM-DD, а при работе с временем требуется учитывать часовой пояс и тип поля – DATE, TIME или TIMESTAMP.
При наличии уникальных индексов перед вставкой целесообразно выполнять проверочный запрос. Это снижает риск отката транзакции и упрощает поиск причины сбоя.
- Проверить описание таблицы через команду просмотра схемы.
- Убедиться, что все обязательные поля получают значения.
- Сравнить типы данных полей и передаваемых значений.
- Проверить наличие родительских записей для внешних ключей.
- Выполнять INSERT внутри транзакции при работе с зависимыми таблицами.
При последовательной вставке связанных записей важно соблюдать порядок: сначала данные в родительских таблицах, затем в дочерних. Нарушение этого правила приводит к отказу записи и ошибке ссылочной целостности.
Контроль структуры запроса и предварительная проверка данных делают ручной ввод через INSERT предсказуемым и безопасным при работе с отдельными записями.
Загрузка данных из CSV и Excel файлов в таблицы базы данных
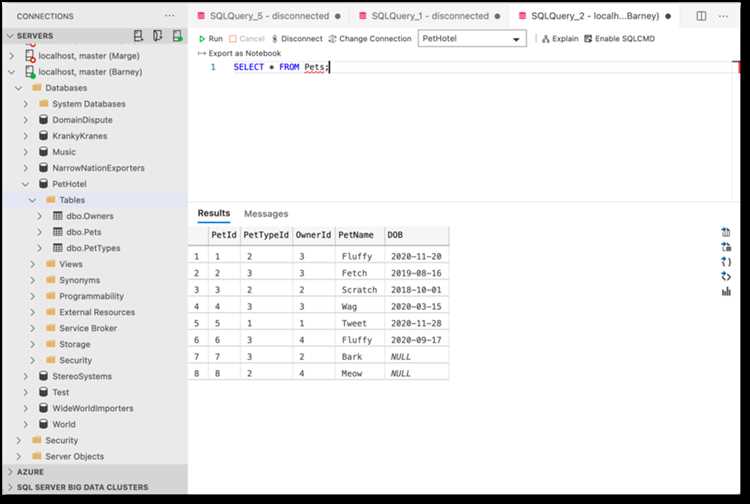
Импорт данных из CSV и Excel файлов позволяет быстро заполнить таблицы значительным объёмом информации без ручного ввода. Перед загрузкой важно проверить структуру файла: количество столбцов, их порядок и соответствие типам данных в таблице.
Для CSV-файлов следует убедиться, что разделитель соответствует настройкам СУБД – чаще всего это запятая или точка с запятой. Строки с заголовками обычно пропускаются или обрабатываются отдельным параметром при импорте. Кодировка файла должна соответствовать системной, чтобы избежать ошибок чтения специальных символов и кириллицы.
Excel файлы (.xlsx, .xls) требуют дополнительной конвертации или использования встроенных инструментов СУБД. При этом важно учитывать типы ячеек: текст, число, дата. Несоответствие приводит к автоматическому преобразованию или ошибке загрузки.
Перед массовой загрузкой данных рекомендуется:
- проверить пустые строки и дубли;
- удалить лишние пробелы и нестандартные символы;
- привести даты к единому формату YYYY-MM-DD;
- сверить уникальные поля с уже существующими записями;
- создать резервную копию таблицы на случай неудачного импорта.
В СУБД, поддерживающих команды BULK INSERT или COPY, импорт можно выполнять напрямую с сервера, минуя приложение. Это ускоряет обработку больших файлов и снижает нагрузку на клиентскую машину.
После загрузки необходимо проверить количество записей, корректность типов данных и соблюдение ограничений таблицы. Автоматическая проверка форматов и соответствия внешним ключам снижает вероятность ошибок при последующем использовании данных.
Ввод данных через веб-формы и обработка на стороне сервера

Веб-формы обеспечивают ввод данных пользователями напрямую в базу данных через серверное приложение. Для корректной работы формы необходимо настроить соответствие полей HTML с типами столбцов в таблице и предусмотреть валидацию на стороне сервера.
Серверная обработка выполняет несколько задач:
- проверка обязательных полей и допустимых значений;
- фильтрация и экранирование специальных символов для защиты от SQL-инъекций;
- приведение типов данных (строки, числа, даты) к формату базы;
- логирование ошибок и контроль успешной записи;
- обработка связей с внешними ключами и зависимыми таблицами.
Рекомендуется использовать транзакции при записи нескольких связанных таблиц. Это предотвращает частичное сохранение данных при сбое и сохраняет целостность базы.
Практические приёмы снижения ошибок при вводе через формы:
- Сверять данные на клиенте с помощью HTML-валидации (type, pattern) перед отправкой на сервер.
- На сервере повторно проверять все значения и преобразовывать их в нужные типы.
- Использовать подготовленные запросы или ORM для вставки данных.
- Отслеживать дубли и уникальные ограничения перед записи.
- Логировать успешные и неудачные попытки для последующего анализа.
При правильной конфигурации веб-форм и серверной обработки ввод данных становится управляемым и безопасным, снижая количество ошибок и сохраняя целостность информации в базе.
Импорт данных из внешних API и сторонних сервисов
Импорт данных через API позволяет автоматически получать информацию из сторонних систем и записывать её в базу данных. Данные чаще всего приходят в формате JSON или XML и требуют предварительного преобразования под структуру таблиц.
Перед импортом необходимо определить:
- поля источника и соответствующие столбцы в таблице базы;
- тип данных и формат для каждого поля;
- частоту запросов и допустимый объём данных для обработки;
- способы обработки дубликатов и уже существующих записей;
- методы логирования ошибок при некорректных ответах API.
При обработке JSON важно правильно работать с вложенными структурами и массивами, преобразуя их в нормализованную таблицу. Для XML требуется парсинг тегов и атрибутов с последующим сопоставлением с колонками базы.
Практические рекомендации при интеграции API:
- использовать batch-запросы для уменьшения количества HTTP-вызовов;
- выполнять проверку уникальности и ссылочной целостности перед вставкой;
- обрабатывать исключения и таймауты сетевых запросов;
- создавать резервные копии таблиц перед массовым импортом;
- автоматизировать повторный импорт только новых или изменённых записей.
Соблюдение этих правил позволяет интегрировать внешние источники с минимальными ошибками и сохранять консистентность базы данных при регулярном обновлении данных.
Массовый ввод данных с использованием BULK INSERT и COPY
Команды BULK INSERT (SQL Server) и COPY (PostgreSQL) предназначены для загрузки больших объёмов данных напрямую из файлов в таблицы базы данных. Эти методы обрабатывают тысячи и миллионы строк быстрее стандартных INSERT-запросов.
Файлы для массового импорта обычно имеют формат CSV или TSV. Перед загрузкой требуется:
- проверить совпадение структуры файла с колонками таблицы;
- удалить пустые строки и лишние пробелы;
- привести даты и числовые значения к формату базы данных;
- обеспечить корректную кодировку файла (UTF-8 или Windows-1251).
При выполнении BULK INSERT или COPY важно учитывать ограничения таблицы:
- уникальные индексы могут вызвать откат загрузки при дубликатах;
- внешние ключи требуют существования связанных записей;
- NOT NULL поля должны содержать значения в каждой строке файла.
Рекомендации при массовом вводе:
- использовать batch-пакеты для разделения больших файлов на несколько частей;
- включать проверку количества загруженных строк;
- создавать резервную копию таблицы перед загрузкой;
- логировать ошибки импорта в отдельный файл для анализа;
- при необходимости временно отключать индексы для ускорения записи и восстанавливать их после завершения.
Правильная подготовка файлов и соблюдение ограничений таблицы позволяют использовать BULK INSERT и COPY для быстрой и безопасной загрузки больших массивов данных без перегрузки сервера.
Проверка и очистка данных перед сохранением в базе данных

Перед записью в базу данных важно убедиться в корректности и консистентности данных. Это снижает количество ошибок и предотвращает нарушения целостности таблиц.
Основные этапы проверки и очистки:
- Проверка типов данных: строки, числа, даты должны соответствовать колонкам таблицы.
- Очистка строк от лишних пробелов, специальных символов и невидимых символов.
- Удаление дубликатов в пределах текущего импорта и сравнение с существующими уникальными ключами.
- Приведение форматов дат и чисел к единому стандарту, принятому в базе данных.
- Проверка внешних ключей: запись не должна ссылаться на несуществующую строку родительской таблицы.
Дополнительные рекомендации:
- Использовать регулярные выражения для проверки формата электронных адресов, телефонов и идентификаторов.
- Разделять обработку данных на этапы: первичная очистка, проверка ограничений, логирование ошибок.
- Автоматизировать процесс с помощью скриптов или встроенных функций СУБД.
- Сохранять результаты проверки в отдельный лог для анализа и исправления некорректных записей.
- При массовом импорте использовать временные таблицы для проверки перед окончательной записью в основную таблицу.
Тщательная проверка и очистка данных гарантирует, что база останется консистентной, а дальнейшие операции с таблицами выполняются без ошибок и потери информации.
Вопрос-ответ:
В чем разница между ручным вводом данных через SQL INSERT и загрузкой из CSV?
Ручной ввод через SQL INSERT подходит для добавления отдельных записей, когда нужно внести точечные изменения или проверить структуру таблицы. Загрузка из CSV позволяет одновременно импортировать большое количество строк из файла, что экономит время при переносе данных из отчётов или других систем. CSV требует проверки формата данных, кодировки и соответствия столбцов таблицы, а INSERT — внимательного указания типов и обязательных полей.
Какие ошибки чаще всего возникают при импорте данных через веб-формы?
Частые ошибки связаны с некорректным форматом данных, пропуском обязательных полей, превышением допустимой длины текста и несоответствием типов данных. Также возможны дубли записей, если форма не проверяет уникальные поля. Чтобы минимизировать ошибки, ввод должен проходить клиентскую проверку и дополнительную обработку на сервере, включая приведение типов и фильтрацию специальных символов.
Как правильно организовать массовый ввод данных с помощью BULK INSERT или COPY?
Массовый ввод требует подготовки файла с данными, проверенного на пустые строки, лишние символы и формат столбцов. Следует учитывать ограничения таблицы: уникальные индексы, NOT NULL поля и внешние ключи. Рекомендуется разбивать большие файлы на пакеты, использовать транзакции для сохранения целостности и вести лог ошибок. После загрузки важно сверить количество записей и проверить соответствие типов.
Зачем проверять и очищать данные перед записью в базу данных?
Проверка и очистка предотвращает запись некорректных или дублирующихся данных, которые могут нарушить целостность таблиц. Сюда входит проверка типов, приведение форматов дат и чисел, удаление лишних пробелов и символов, проверка внешних ключей. Такие действия снижают количество ошибок при последующем использовании данных и облегчают анализ информации.