Содержание статьи

При проектировании таблиц реляционных баз данных часто возникает задача автоматического формирования уникальных числовых идентификаторов. В SQL Server для этого используется свойство IDENTITY, которое позволяет базе данных самостоятельно увеличивать значение столбца при каждой вставке строки. Такой подход снижает риск дублирования ключей и упрощает работу с первичными ключами без дополнительной логики на стороне приложения.
Свойство IDENTITY задаётся на этапе создания таблицы и работает на уровне движка базы данных. Оно опирается на два параметра – начальное значение и шаг приращения, которые напрямую влияют на последовательность генерируемых чисел. Понимание этих параметров важно при переносе данных, восстановлении после сбоев и синхронизации таблиц между средами.
На практике IDENTITY затрагивает не только операции INSERT, но и транзакции, откаты, репликацию, а также сценарии ручной вставки значений. Ошибочное представление о его работе часто приводит к «пропускам» в нумерации, неожиданным конфликтам или некорректному получению последнего добавленного идентификатора. Эти моменты требуют чёткого понимания внутренних правил генерации значений.
В статье подробно рассматривается назначение IDENTITY, порядок его настройки, особенности поведения при различных типах операций и ограничения, о которых важно знать при разработке и администрировании баз данных SQL Server. Материал ориентирован на практические вопросы, с которыми сталкиваются разработчики и администраторы при работе с автоинкрементными столбцами.
IDENTITY в SQL: назначение и принцип работы
Свойство IDENTITY используется в SQL Server для автоматического присвоения числовых значений столбцу при добавлении строк. Сервер сам вычисляет очередное число, исключая необходимость ручного контроля уникальности. Чаще всего такой столбец назначается первичным ключом, так как он гарантирует уникальность в пределах таблицы.
Механизм IDENTITY основан на внутреннем счётчике, который увеличивается при каждой операции INSERT. Значение формируется до завершения транзакции и фиксируется независимо от того, будет ли вставка подтверждена. Откат транзакции не возвращает число обратно, поэтому пропуски в последовательности считаются допустимыми и не влияют на корректность данных.
Параметры seed и increment задают начальное значение и шаг увеличения. Например, IDENTITY(1000,10) создаёт последовательность 1000, 1010, 1020 и так далее. Такой вариант применяется, когда требуется зарезервировать диапазоны значений или визуально отделить записи одной таблицы от другой.
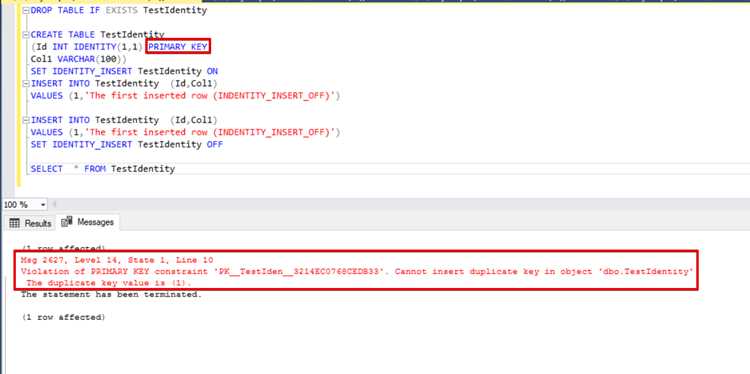
При стандартной работе столбец с IDENTITY исключается из списка вставляемых полей. Если необходимо загрузить данные с сохранением исходных идентификаторов, используется режим SET IDENTITY_INSERT ON. Он разрешает явное указание значений, но может быть активен только для одной таблицы в рамках сессии.
IDENTITY не предназначен для логики предметной области. Его значения могут изменяться при пересоздании таблиц, импорте данных или ручной корректировке счётчика через DBCC CHECKIDENT. Поэтому такие столбцы следует рассматривать как технические идентификаторы, а не как устойчивые бизнес-номера.
Что такое IDENTITY и зачем он применяется в таблицах SQL
Основная задача IDENTITY – создание уникального идентификатора строки, пригодного для использования в первичном ключе. Это упрощает структуру таблиц, так как исключает необходимость самостоятельно вычислять значения и проверять их на уникальность в прикладном коде или триггерах.
IDENTITY применяется в таблицах, где требуется стабильный технический идентификатор для связей между данными. Внешние ключи, журналы операций, истории изменений и служебные таблицы опираются именно на такие значения, так как они формируются централизованно и не зависят от источника данных.
Использование IDENTITY снижает риск конфликтов при параллельных вставках. Несколько пользователей или сервисов могут одновременно добавлять записи, и сервер корректно распределит значения без блокировок на уровне приложения.
IDENTITY не предназначен для хранения смысловых номеров, таких как коды заказов или номера документов. Его применяют там, где требуется только уникальность и ссылка на строку, а не логическая последовательность без пропусков.
Как задаётся IDENTITY при создании таблицы: seed и increment
Свойство IDENTITY указывается непосредственно в определении столбца при создании таблицы. Оно принимает два числовых параметра: начальное значение (seed) и шаг приращения (increment). Формат записи выглядит как IDENTITY(seed, increment) и поддерживается для целочисленных типов данных.
Параметр seed определяет, с какого числа начнётся нумерация первой вставленной строки. Если таблица создаётся пустой, именно это значение будет присвоено первой записи. При повторном заполнении таблицы или восстановлении данных начальное значение влияет на дальнейшую генерацию идентификаторов.
Параметр increment задаёт, на сколько будет увеличиваться значение счётчика при каждой операции INSERT. Чаще всего используется шаг 1, но допускаются и другие варианты, включая отрицательные значения для обратной нумерации.
При выборе значений seed и increment следует учитывать практические сценарии:
- Для стандартных первичных ключей обычно применяется IDENTITY(1,1).
- Для разделения диапазонов между системами или средами используют нестандартный seed, например IDENTITY(100000,1).
- При необходимости визуального разграничения записей допускается шаг больше единицы, например IDENTITY(10,10).
Значения seed и increment фиксируются в момент создания таблицы и не могут быть изменены через ALTER COLUMN. Для корректировки последовательности используется сброс счётчика командой DBCC CHECKIDENT или пересоздание таблицы с нужными параметрами.
Как работает автоувеличение значения IDENTITY при INSERT

При выполнении операции INSERT в таблицу с столбцом IDENTITY SQL Server автоматически вычисляет значение для этого столбца. Сервер использует внутренний счётчик, который хранит текущее значение и при каждом добавлении строки увеличивает его на величину increment, заданную при создании таблицы.
Процесс присвоения значения происходит до фиксации транзакции. Если вставка завершится успешно, новое значение сохраняется. В случае отката транзакции использованное число не возвращается в счётчик, что приводит к возможным пропускам в последовательности.
Автоувеличение срабатывает независимо от других полей и не требует указания столбца IDENTITY в списке вставляемых значений. Попытка явного указания значения без включения режима SET IDENTITY_INSERT ON приведёт к ошибке.
SQL Server гарантирует уникальность значений IDENTITY в рамках одной таблицы, даже при параллельных вставках с разных соединений. Система блокирует счётчик на уровне ядра движка, обеспечивая корректную генерацию чисел без конфликтов.
Для контроля текущего состояния счётчика используют функции и команды:
- SCOPE_IDENTITY() – возвращает последнее значение IDENTITY в текущей сессии и текущем объекте.
- @@IDENTITY – возвращает последнее значение IDENTITY, присвоенное в любой таблице в текущей сессии, включая триггеры.
- IDENT_CURRENT(‘TableName’) – возвращает текущее значение счётчика для указанной таблицы независимо от сессии.
Получение последнего значения IDENTITY: SCOPE_IDENTITY, @@IDENTITY, IDENT_CURRENT
После вставки строки в таблицу с IDENTITY часто требуется узнать присвоенное значение. SQL Server предоставляет три способа получения последнего идентификатора, каждый из которых имеет свои особенности и область применения.
SCOPE_IDENTITY() возвращает значение IDENTITY, созданное в текущем сеансе и текущем диапазоне выполнения (scope). Это исключает значения, добавленные в триггерах или других объектах, вызываемых текущим запросом. Рекомендуется использовать для получения идентификаторов сразу после INSERT, чтобы избежать конфликтов.
@@IDENTITY возвращает последнее значение IDENTITY в текущем сеансе, включая вставки, выполненные триггерами. Этот метод полезен, когда необходимо отследить все изменения идентификаторов в рамках сессии, но может вернуть неожиданное значение при наличии триггеров.
IDENT_CURRENT(‘TableName’) возвращает текущее значение счётчика IDENTITY указанной таблицы независимо от сеанса и scope. Подходит для анализа состояния таблицы или проверки последнего присвоенного числа, но не гарантирует корректность при одновременных вставках из разных сессий.
При выборе метода следует ориентироваться на контекст:
- Для безопасного получения IDENTITY после вставки в своей сессии – SCOPE_IDENTITY().
- Для учета всех вставок в текущей сессии, включая триггеры – @@IDENTITY.
- Для проверки последнего значения таблицы независимо от пользователя – IDENT_CURRENT.
Поведение IDENTITY при ошибках вставки и откате транзакций
При использовании столбца IDENTITY значение присваивается автоматически на момент выполнения INSERT. Если вставка завершилась с ошибкой или транзакция откатилась, присвоенное число не возвращается обратно в счётчик. В результате возможны пропуски в последовательности значений.
Рассмотрим ключевые моменты работы IDENTITY при сбоях:
- Если одна из строк в пакетной вставке вызывает ошибку, успешно добавленные строки сохраняют свои идентификаторы, а счётчик увеличивается на количество попыток вставки.
- Откат всей транзакции не восстанавливает ранее использованные значения IDENTITY. Последующее добавление строк продолжит последовательность от последнего присвоенного числа.
- Ошибки, вызванные ограничениями целостности, триггерами или нарушением типов данных, не влияют на корректность работы счётчика – SQL Server просто пропускает «использованные» значения.
Для восстановления последовательности или исправления пропусков используется команда DBCC CHECKIDENT с указанием нового текущего значения. Это важно при миграциях данных или тестировании, когда требуется строгая непрерывность нумерации.
Практическая рекомендация: не полагаться на IDENTITY как на непрерывную последовательность для бизнес-логики. Используйте его исключительно для технических идентификаторов строк, а для нумерации документов или заказов применяйте отдельные механизмы формирования последовательных номеров.
Сброс и изменение счётчика IDENTITY с помощью DBCC CHECKIDENT
Команда DBCC CHECKIDENT позволяет просматривать текущее значение счётчика IDENTITY и при необходимости изменять его для таблицы. Это важно при миграции данных, восстановлении после удаления записей или корректировке пропусков в последовательности.
Синтаксис основных операций:
| Команда | Описание |
|---|---|
| DBCC CHECKIDENT(‘TableName’) | |
| DBCC CHECKIDENT(‘TableName’, RESEED, NewValue) | Устанавливает текущее значение счётчика на NewValue. Следующая вставка получит значение NewValue + increment. |
Примеры применения:
- После удаления всех строк в таблице можно сбросить счётчик на 0: DBCC CHECKIDENT(‘Orders’, RESEED, 0).
- Если требуется продолжить последовательность с определённого номера, указываем нужное значение NewValue, равное последнему присвоенному идентификатору.
Важно учитывать:
- DBCC CHECKIDENT изменяет только внутренний счётчик, данные в таблице не затрагиваются.
- Следующая вставка всегда увеличивает значение на increment, заданный при создании столбца IDENTITY.
- Команда может использоваться как для технической корректировки, так и для подготовки таблицы к тестированию или миграции.
Ограничения и типичные проблемы использования IDENTITY
IDENITY в SQL Server имеет несколько ограничений, которые необходимо учитывать при проектировании таблиц:
- Столбец с IDENTITY может быть только одного числового типа, чаще INT, BIGINT, SMALLINT или TINYINT. Другие типы данных, включая DECIMAL и CHAR, не поддерживаются.
- Нельзя изменить параметры seed и increment через ALTER COLUMN. Любые корректировки требуют использования DBCC CHECKIDENT или пересоздания столбца.
- IDENITY не гарантирует непрерывную последовательность. Пропуски возможны при откате транзакций, ошибках вставки или параллельных операциях.
- Автоувеличение не защищает от переполнения типа данных. Например, INT переполнится после 2 147 483 647 вставок, что приведёт к ошибкам при дальнейших вставках.
Типичные проблемы при использовании IDENTITY:
- Конфликты при явной вставке значений без SET IDENTITY_INSERT ON.
- Неожиданные пропуски в последовательности при работе с триггерами или пакетными вставками.
- Сложности при репликации или миграции данных, если счётчик не синхронизирован между средами.
- Использование IDENTITY для бизнес-логики, где требуется непрерывная нумерация документов или заказов, приводит к ошибкам и необходимости дополнительных механизмов контроля.
Рекомендация: рассматривать IDENTITY исключительно как технический идентификатор строки, а для других задач применять отдельные генераторы последовательностей или логические счётчики.
Отличия IDENTITY от SEQUENCE и когда выбирать каждый вариант

IDENITY и SEQUENCE оба служат для генерации уникальных числовых значений, но реализуются по-разному и имеют разные сценарии применения.
IDENTITY привязан к конкретному столбцу таблицы. Значение генерируется автоматически при INSERT и хранится внутри таблицы. SEQUENCE – это отдельный объект базы данных, независимый от таблиц. Он создаётся через CREATE SEQUENCE и может использоваться в нескольких таблицах или для различных столбцов.
Ключевые отличия:
- Привязка: IDENTITY – только один столбец таблицы; SEQUENCE – отдельный объект, доступный из любых таблиц.
- Гибкость: SEQUENCE позволяет задавать более сложные правила генерации: диапазоны, циклы, шаги, начальные значения, увеличение на произвольное число.
- Управление: IDENTITY управляется через DBCC CHECKIDENT; SEQUENCE управляется командой ALTER SEQUENCE, что позволяет динамически изменять свойства без пересоздания таблицы.
- Использование в транзакциях: SEQUENCE может выдавать значения до вставки и использоваться для предварительного резервирования идентификаторов; IDENTITY присваивает значение только при INSERT.
Рекомендации по выбору:
- Использовать IDENTITY для простых первичных ключей одной таблицы, где требуется уникальный идентификатор без сложной логики.
- Использовать SEQUENCE, если требуется генерация значений для нескольких таблиц, нестандартные шаги, циклическая последовательность или контроль за диапазонами идентификаторов.
Вопрос-ответ:
Что такое столбец IDENTITY и зачем он нужен в таблицах SQL?
Столбец IDENTITY автоматически присваивает числовое значение каждой новой строке при вставке. Он используется для создания уникального идентификатора записи, обычно в качестве первичного ключа, без необходимости вручную генерировать или проверять уникальность значения.
Как задать начальное значение и шаг для IDENTITY при создании таблицы?
При объявлении столбца IDENTITY указываются два параметра: seed (начальное значение) и increment (шаг). Например, IDENTITY(1,1) означает, что первая запись получит значение 1, а каждая последующая будет увеличена на 1. Эти параметры фиксируются при создании таблицы и влияют на всю последовательность.
Как получить последнее присвоенное значение IDENTITY после вставки строки?
Для этого используются три основных метода: SCOPE_IDENTITY() возвращает значение в текущем сеансе и текущем диапазоне выполнения, @@IDENTITY учитывает все вставки в текущей сессии, включая триггеры, а IDENT_CURRENT(‘TableName’) показывает текущее значение IDENTITY конкретной таблицы независимо от сессии. Для обычных вставок безопаснее использовать SCOPE_IDENTITY().
Почему при откате транзакции или ошибке вставки появляются пропуски в последовательности IDENTITY?
Значение IDENTITY присваивается на момент выполнения INSERT, до фиксации транзакции. Если операция откатывается из-за ошибки или отмены транзакции, присвоенное число не возвращается в счётчик, что приводит к пропускам. Это нормальное поведение движка SQL Server.
Когда лучше использовать IDENTITY, а когда SEQUENCE для генерации идентификаторов?
IDENTITY подходит для простых таблиц с одним столбцом, где требуется уникальный идентификатор автоматически при вставке. SEQUENCE используют, если необходимо применять одну последовательность к нескольким таблицам, задавать нестандартные шаги, циклические значения или управлять диапазонами. SEQUENCE создаётся отдельно и может использоваться в разных контекстах.
Как IDENTITY влияет на уникальность строк в таблице?
Столбец с IDENTITY гарантирует уникальные числовые значения для каждой строки в таблице. При вставке SQL Server автоматически увеличивает счётчик и присваивает следующее значение, что позволяет использовать этот столбец как первичный ключ без ручного контроля уникальности.
Можно ли изменить последовательность IDENTITY после создания таблицы?
Непосредственно изменить параметры seed и increment нельзя. Для корректировки текущего значения счётчика используют команду DBCC CHECKIDENT, которая позволяет установить новое значение, от которого будет продолжена генерация. Такой подход используется при миграции данных, восстановлении таблицы или исправлении пропусков в последовательности.