Содержание статьи

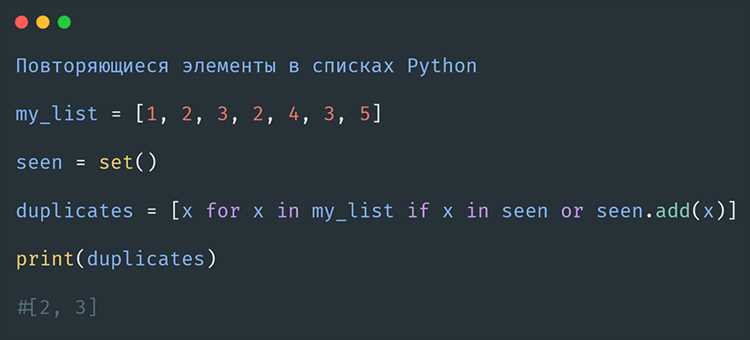
В языках программирования на C массивы представляют собой последовательные блоки памяти, где хранятся однотипные элементы. В больших массивах часто возникает необходимость выявить повторяющиеся значения, чтобы избежать ошибок в вычислениях или подготовить данные для анализа. Простейший способ – это сравнивать каждый элемент с остальными, но при увеличении размера массива такой подход может существенно замедлять выполнение программы.
Для ускорения поиска дубликатов применяются структуры данных, такие как hash table или вспомогательные массивы, которые позволяют проверять наличие элемента за константное время. В C это реализуется через массивы флагов или собственные функции хеширования, что сокращает количество сравнений и снижает нагрузку на процессор при больших объемах данных.
Сортировка массива перед проверкой повторов также облегчает задачу: одинаковые элементы оказываются рядом, и достаточно прохода по массиву с последовательной проверкой соседних значений. В зависимости от размера и структуры данных разработчик может выбрать между вложенными циклами, указателями или использованием сторонних библиотек для управления памятью и оптимизации поиска.
Определение повторяющихся элементов в массиве
Для точного определения повторов важно учитывать следующие аспекты:
- Тип данных массива: целые числа, символы или структуры требуют разных подходов к сравнению.
- Размер массива: чем больше элементов, тем выше вычислительная нагрузка при стандартном поиске.
- Порядок элементов: сортированный массив позволяет использовать оптимизированные методы поиска дубликатов.
С практической точки зрения, повторяющиеся элементы можно определить с помощью нескольких подходов:
- Сравнение каждого элемента со всеми остальными через вложенные циклы. Метод прост, но требует O(n²) операций.
- Использование вспомогательных структур, например массивов флагов или hash table, для отслеживания уже встреченных значений. Это снижает количество сравнений.
- Сортировка массива и последовательная проверка соседних элементов. Подходит для больших массивов и уменьшает сложность до O(n log n) при сортировке.
При реализации поиска важно корректно обращаться с индексами массива, чтобы избежать ошибок доступа к памяти и корректно фиксировать позиции повторов для дальнейшей обработки.
Использование вложенных циклов для поиска дубликатов
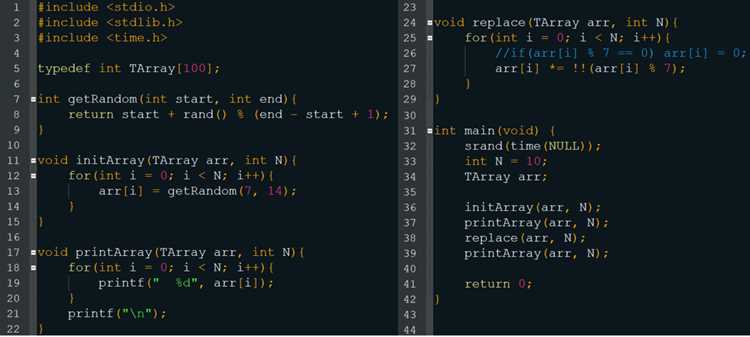
Поиск повторяющихся элементов с помощью вложенных циклов предполагает последовательное сравнение каждого элемента массива со всеми последующими. Этот метод подходит для массивов небольшого размера, где сложность O(n²) не приводит к заметной задержке выполнения программы.
Алгоритм работы выглядит следующим образом:
- Внешний цикл перебирает элементы массива от первого до предпоследнего.
- Внутренний цикл сравнивает текущий элемент внешнего цикла со всеми элементами, расположенными после него.
- Если совпадение найдено, элемент фиксируется как дубликат, и при необходимости сохраняется его индекс.
Рекомендации при использовании метода вложенных циклов:
- Для массивов с большим количеством элементов использовать дополнительные структуры данных или сортировку для ускорения поиска.
- Не изменять массив во время проверки, чтобы избежать смещения индексов и потери данных.
Этот подход позволяет точно определить все повторяющиеся элементы без использования дополнительных библиотек или сложных структур данных, что делает его удобным для базового анализа данных в C.
Применение структуры данных hash table для проверки повторов
Hash table позволяет проверять наличие элементов в массиве с постоянным временем доступа, что значительно ускоряет поиск дубликатов по сравнению с вложенными циклами. В C hash table реализуется с помощью массивов указателей на структуры, содержащие ключи и, при необходимости, счетчики повторений.
Алгоритм выявления дубликатов через hash table включает несколько шагов:
- Инициализация hash table с заданным размером, учитывая диапазон значений элементов массива.
- Для каждого элемента массива вычисляется hash-значение, определяющее индекс в таблице.
- Если соответствующий слот пуст, элемент добавляется; если слот занят, проверяется совпадение ключей и фиксируется повтор.
- При необходимости используется метод разрешения коллизий, например цепочки или линейное пробирование.
Рекомендации при использовании hash table для поиска повторов:
- Выбирать размер таблицы с запасом, чтобы снизить количество коллизий.
- Использовать простые функции хеширования для целых чисел, например остаток от деления на размер таблицы.
- При работе с символами или строками учитывать их преобразование в числовой формат перед добавлением в таблицу.
Применение hash table особенно эффективно при больших массивах, где вложенные циклы становятся непрактичными. Такая структура позволяет быстро выявлять повторяющиеся элементы и хранить их количество без дополнительного обхода всего массива.
Сортировка массива перед выявлением повторов

Сортировка массива упрощает поиск повторяющихся элементов, так как одинаковые значения оказываются рядом, и для выявления дубликатов достаточно одного прохода по массиву. Это снижает сложность задачи по сравнению с вложенными циклами.

Алгоритм выглядит следующим образом:
- Выбирается подходящий метод сортировки: quicksort, mergesort или встроенная функция qsort() из стандартной библиотеки C.
- После сортировки выполняется линейный обход массива, при котором каждый элемент сравнивается с предыдущим.
- При совпадении элементов фиксируется повтор, при необходимости сохраняются индексы или количество повторений.
Рекомендации при использовании сортировки для поиска повторов:
- Для небольших массивов достаточно qsort(), которая реализует быструю сортировку с временем O(n log n).
- Если важна стабильность сортировки (сохранение порядка элементов с одинаковыми значениями), предпочтительнее mergesort.
- После сортировки важно корректно обрабатывать крайние элементы массива, чтобы не пропустить повтор на границе.
Поиск дубликатов с помощью указателей и массивов

Использование указателей для обхода массива позволяет более гибко управлять памятью и ускоряет доступ к элементам при поиске повторов. Вместо индексного обращения применяется арифметика указателей, что особенно удобно при работе с динамически выделенными массивами.
Пример алгоритма поиска дубликатов с указателями:
- Создается указатель на первый элемент массива.
- С помощью вложенных циклов указатели перемещаются по массиву, сравнивая текущий элемент с последующими.
- При обнаружении совпадения фиксируется дубликат и при необходимости сохраняется адрес элемента для дальнейшей обработки.
Для наглядного представления результатов удобно использовать таблицу:
| Элемент | Адрес в памяти | Количество повторений |
|---|---|---|
| 5 | 0x7ffee1a3b8 | 2 |
| 12 | 0x7ffee1a40c | 3 |
Рекомендации при работе с указателями и массивами:
- Следить за корректностью арифметики указателей, чтобы не выйти за границы массива.
- Использовать динамические массивы, если размер данных заранее неизвестен.
Такой подход объединяет точность поиска с минимальными затратами на индексацию, обеспечивая прямой доступ к каждому элементу и возможность гибкой работы с памятью.
После выявления дубликатов важно корректно отобразить их значения и позиции в массиве. В C для этого чаще всего используют циклы и вспомогательные массивы или структуры, где фиксируются индексы повторяющихся элементов.
- Создается массив или структура для хранения индексов повторяющихся элементов.
- При обнаружении повторного значения добавляется его индекс в список.
Для наглядного представления удобно использовать табличный формат:
| Элемент | Индексы |
|---|---|
| 7 | 2, 5, 8 |
| 12 | 1, 4 |
- Сохранять индексы в порядке их появления для удобного анализа.
- Использовать динамические структуры, если количество повторов заранее неизвестно.
Вопрос-ответ:
Какие методы поиска повторяющихся элементов в массиве на C существуют?
В C есть несколько подходов к поиску дубликатов. Наиболее простым является использование вложенных циклов, где каждый элемент сравнивается со всеми последующими. Более быстрые методы включают сортировку массива с последующей проверкой соседних элементов и применение структур данных, таких как hash table, для фиксации уже встреченных значений. Выбор метода зависит от размера массива и требуемой скорости выполнения.
Как использовать вложенные циклы для поиска повторов в массиве?
Вложенные циклы позволяют проверить каждый элемент массива против всех остальных. Внешний цикл перебирает элементы от первого до предпоследнего, внутренний — от текущего элемента внешнего цикла до конца массива. Если значения совпадают, фиксируется дубликат. Этот метод подходит для небольших массивов, так как количество операций растет квадратично с увеличением размера данных.
Для чего полезна сортировка массива перед поиском повторов?
Сортировка упорядочивает элементы, благодаря чему одинаковые значения оказываются рядом. После сортировки достаточно одного прохода по массиву, чтобы сравнивать соседние элементы и фиксировать повторяющиеся значения. Этот метод сокращает количество сравнений и снижает вычислительную нагрузку при работе с массивами среднего и большого размера.
Как применить hash table для выявления повторяющихся элементов?
Hash table позволяет проверять наличие элемента с постоянным временем доступа. Для каждого элемента массива вычисляется hash-значение, которое определяет позицию в таблице. Если слот пуст, значение добавляется; если занято и совпадает с текущим, фиксируется повтор. Коллизии можно разрешать с помощью цепочек или линейного пробирования. Такой подход ускоряет поиск дубликатов в больших массивах.
Как вывести повторяющиеся элементы и их индексы на экран?
Для вывода дубликатов создают массив или структуру для хранения индексов повторяющихся элементов. При обнаружении совпадения индекс добавляется в список. После обработки всего массива выполняется вывод значения элемента и всех его индексов. Для наглядности можно использовать таблицу, где первая колонка — значение элемента, а вторая — список индексов. При больших массивах результаты можно сохранять в файл.