Содержание статьи

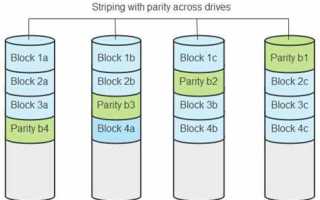
Сбой одного диска в массиве RAID 5 не приводит к немедленной потере данных, но переводит систему в деградированное состояние. В этот момент нагрузка на оставшиеся накопители возрастает, а риск второго отказа становится выше. Любые действия без понимания текущего состояния массива могут привести к необратимым последствиям, включая потерю файловой структуры и служебных метаданных.
Процесс восстановления RAID 5 зависит от типа реализации – аппаратный контроллер, программный RAID в Linux или встроенные решения NAS. Ошибки часто возникают из-за поспешной замены диска, некорректного порядка операций или автоматического запуска ребилда при наличии скрытых проблем с другими накопителями. Перед началом работ требуется точно определить, какой диск вышел из строя, и зафиксировать текущее состояние массива.
Важно учитывать параметры исходного массива: порядок дисков, размер блока, уровень четности, версию контроллера или драйвера. Потеря этих данных усложняет восстановление и может потребовать ручной сборки массива. Любая операция записи до завершения диагностики увеличивает риск повреждения данных, поэтому первоочередная задача – минимизировать изменения на уровне дисков.
В статье разобраны практические шаги восстановления RAID 5 после отказа одного диска: от проверки состояния массива до контроля ребилда и проверки целостности данных. Описываются типовые ошибки, с которыми сталкиваются администраторы, и способы их предотвращения без остановки всей системы.
Признаки отказа диска и подтверждение деградации RAID 5

Аппаратные массивы фиксируют ошибки в журнале контроллера, включая номер порта, слот и серийный номер диска. Частые записи о тайм-аутах, сбоях канала или medium error указывают на физический дефект. Световая индикация на корзине помогает локализовать проблемный диск, но не является достаточным подтверждением отказа.
SMART-показатели диска дают дополнительную диагностику. К критическим признакам относятся увеличение числа переназначенных секторов, необрабатываемые ошибки чтения и рост параметра Current Pending Sector. Попытки повторного подключения такого диска в массив недопустимы, так как это может привести к повреждению данных.
Окончательное подтверждение деградации RAID 5 выполняется после сопоставления информации контроллера, системных логов и SMART. Зафиксированные серийные номера и статус массива позволяют безопасно планировать замену диска и минимизировать риск потери информации.
Проверка состояния массива через контроллер или программный RAID
Для аппаратных RAID проверка состояния начинается с доступа к интерфейсу контроллера. Необходимо просмотреть журнал событий, определить статус каждого диска, наличие ошибок чтения и записи, а также убедиться, что массив не имеет пропущенных блоков или расхождений четности. Любые изменения конфигурации перед диагностикой запрещены, чтобы избежать повреждения данных.
Программные RAID в Linux или Windows предоставляют команды и утилиты для анализа состояния. В Linux ключевым инструментом является mdadm —detail /dev/mdX, который показывает статус массива, число активных и исключённых дисков, индекс проблемного устройства и прогресс возможного ребилда. В Windows Storage Spaces или других программных решениях используются аналогичные средства с отчетами о состоянии дисков и целостности данных.
Важно дополнительно сверить результаты SMART каждого диска с данными массива. Наличие нестабильных секторов, растущего количества переназначенных блоков или ошибок коррекции указывает на скрытые проблемы, которые контроллер может не отразить напрямую. Игнорирование этих признаков увеличивает риск повреждения массива при восстановлении.
Для подтверждения точного состояния следует провести контроль чтения и записи небольших блоков данных на каждом диске без изменения содержимого. Этот шаг позволяет выявить медленные или нестабильные устройства до начала процедуры ребилда и минимизирует вероятность дальнейшей деградации массива.
Выбор и замена неисправного диска без остановки системы
Для замены диска в RAID 5 без остановки важно точно определить проблемный накопитель. Используются журналы контроллера, состояние массива и SMART-показатели. После идентификации диска фиксируются его серийный номер, слот и порт подключения, чтобы исключить ошибочную замену.
При выборе нового диска учитываются следующие параметры: емкость, скорость вращения шпинделя, интерфейс и кэш. Несоответствие этих характеристик может замедлить процесс ребилда или вызвать нестабильность массива.
| Параметр | Рекомендация |
|---|---|
| Емкость | Не меньше минимального диска в массиве, лучше на 1-2% больше |
| Интерфейс | Совпадение с существующими дисками: SATA, SAS |
| Скорость вращения | Идентична рабочим дискам для равномерной нагрузки |
| Кэш | Равный или больше текущего для предотвращения узких мест при ребилде |
Замена выполняется через горячую корзину, если контроллер поддерживает hot-swap. Диск извлекается осторожно, без воздействия на остальные накопители, и устанавливается новый. Контроллер автоматически начинает процедуру ребилда, которую необходимо мониторить через журнал событий и показатели прогресса, чтобы убедиться в корректности восстановления данных.
Запуск процедуры ребилда и контроль процесса восстановления
Процедура ребилда начинается после установки нового диска или подключения восстановленного. В аппаратных RAID контроллер автоматически инициирует восстановление данных из четности. В программных массивах запуск может требовать команды, например, mdadm —add /dev/mdX /dev/sdY в Linux.
Для контроля процесса рекомендуется выполнять следующие действия:
- Мониторинг прогресса ребилда через интерфейс контроллера или утилиты программного RAID.
- Регулярная проверка логов на ошибки чтения/записи или тайм-ауты.
- Отслеживание температуры и состояния оставшихся дисков, чтобы предотвратить перегрузку и вторичный отказ.
- Проверка производительности системы, чтобы убедиться, что нагрузка не превышает допустимые значения для текущего этапа восстановления.
Во время ребилда рекомендуется ограничивать интенсивные операции записи и чтения, чтобы ускорить восстановление и снизить риск дополнительных ошибок. В случае обнаружения нестабильных секторов или повторяющихся ошибок чтения необходимо приостановить процесс и провести диагностику проблемного диска.
После завершения ребилда следует выполнить контроль целостности данных:
- Сравнение контрольных сумм критических файлов и баз данных.
- Проверка журналов на наличие пропущенных или поврежденных блоков.
- Тестирование работы приложений и сервисов, использующих массив.
Только после подтверждения корректности всех данных можно считать восстановление RAID 5 завершенным.
Типовые ошибки при восстановлении RAID 5 и способы их избежать

Частая ошибка – неправильная идентификация сбойного диска. Замена рабочего накопителя разрушает массив. Перед установкой нового диска фиксируют серийный номер, слот и порт устройства.
Запуск ребилда без проверки состояния остальных дисков повышает риск потери данных. Даже если массив функционирует, скрытые ошибки на оставшихся дисках могут вызвать сбой во время восстановления. Рекомендуется проверять SMART и журналы контроллера.
Попытка собрать массив с дисками, которые имеют разные размеры, параметры блока или алгоритм четности, приводит к невозможности восстановления данных. Используются только оригинальные диски или идентичные по характеристикам.
Игнорирование прогресса ребилда и возникающих ошибок чтения или тайм-аутов может привести к вторичному отказу. Необходимо постоянно отслеживать процесс и при обнаружении проблем приостанавливать восстановление для диагностики.
Высокая нагрузка на массив во время ребилда замедляет процесс и увеличивает риск ошибок. Для снижения нагрузки операции записи и чтения с массива минимизируются до завершения восстановления.
Соблюдение этих рекомендаций позволяет безопасно восстановить RAID 5 и снизить вероятность повреждения данных.
Проверка целостности данных после завершения восстановления

После завершения ребилда RAID 5 необходимо убедиться в полной целостности данных, чтобы исключить скрытые ошибки и поврежденные блоки. Контроль проводится по следующим этапам:
- Сравнение контрольных сумм критических файлов и баз данных с резервными копиями.
- Использование утилит проверки файловой системы, таких как fsck в Linux или chkdsk в Windows, для обнаружения и исправления ошибок.
- Тестирование приложений и сервисов, работающих с массивом, чтобы убедиться в корректной работе и доступности данных.
- Сканирование всего объема массива на наличие битых секторов или нестабильных блоков с помощью SMART и специализированных инструментов.
Рекомендуется документировать результаты проверки для последующего анализа и обеспечения прозрачности действий по восстановлению.
При выявлении несоответствий необходимо:
- Повторно проверить проблемные участки на исходных дисках.
- Использовать резервные копии для восстановления поврежденных данных.
- Выполнить повторный ребилд или пересборку массива при обнаружении структурных ошибок.
Только после подтверждения корректности всех данных массив можно считать полностью восстановленным.
Вопрос-ответ:
Как определить, какой диск вышел из строя в RAID 5?
Определение неисправного диска начинается с анализа состояния массива через контроллер или программные утилиты. В аппаратных решениях контроллер отображает слот, порт и серийный номер проблемного диска, а также фиксирует ошибки чтения/записи в журнале событий. В программных RAID под Linux используется команда mdadm —detail /dev/mdX, которая показывает активные и исключённые диски, их статус и прогресс восстановления. Дополнительно рекомендуется проверить SMART каждого накопителя, чтобы выявить скрытые дефекты.
Можно ли заменить диск в RAID 5 без остановки системы?
Да, если контроллер или программное решение поддерживает горячую замену (hot-swap). Перед установкой нового диска фиксируют серийный номер и слот проблемного накопителя. Новый диск устанавливают в соответствующий слот, после чего контроллер автоматически запускает ребилд. Важно наблюдать за журналом событий и прогрессом восстановления, чтобы убедиться, что процесс идёт корректно и не создаёт дополнительной нагрузки на оставшиеся диски.
Какие ошибки чаще всего возникают при восстановлении RAID 5?
Наиболее распространённые ошибки включают: 1) неправильная идентификация неисправного диска и замена рабочего накопителя; 2) запуск ребилда без проверки состояния остальных дисков, что может вызвать вторичный сбой; 3) использование дисков с разными характеристиками, несовместимыми с исходным массивом; 4) игнорирование ошибок чтения и тайм-аутов во время ребилда; 5) высокая нагрузка на массив в процессе восстановления. Все эти ошибки увеличивают риск повреждения данных и замедляют восстановление.
Как контролировать процесс ребилда RAID 5?
Процесс ребилда контролируется через интерфейс контроллера или программные утилиты. Необходимо наблюдать за прогрессом восстановления, проверять журналы на ошибки чтения/записи, отслеживать температуру и состояние оставшихся дисков. При появлении нестабильных секторов или тайм-аутов процесс рекомендуется приостановить для диагностики. Для ускорения ребилда рекомендуется ограничить интенсивные операции с массивом и минимизировать нагрузку на диски.
Как проверить целостность данных после завершения восстановления RAID 5?
Проверка целостности включает несколько шагов: сравнение контрольных сумм критических файлов с резервными копиями, использование утилит проверки файловой системы (fsck или chkdsk), сканирование массива на битые сектора и тестирование работы приложений, использующих массив. При обнаружении несоответствий выполняется восстановление данных из резервных копий или повторный ребилд проблемных сегментов. Только после подтверждения корректности всех данных массив можно считать восстановленным.