Содержание статьи

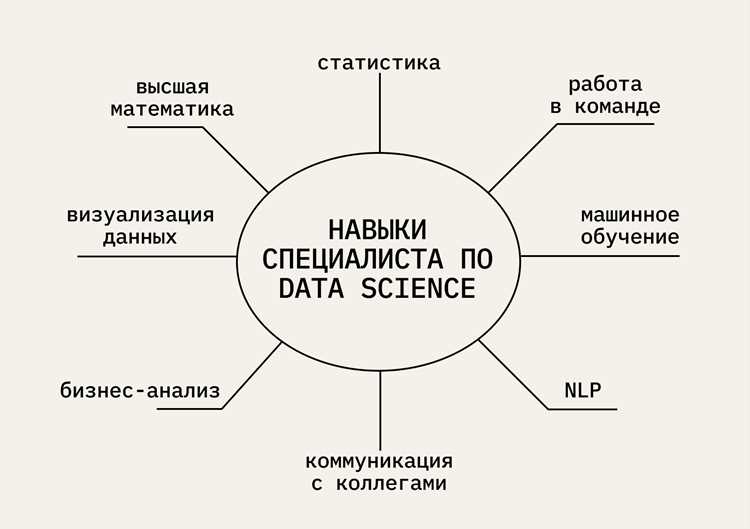
Data Scientist – специалист, который преобразует сырые данные в конкретные решения для бизнеса. В среднем, профессионалы в этой области работают с наборами данных размером от нескольких гигабайт до нескольких терабайт, используя языки программирования Python и R для обработки, очистки и анализа информации.
Основная задача Data Scientist – выявление закономерностей и построение прогнозных моделей. Для этого применяются методы статистики, регрессии, классификации и машинного обучения. Например, прогноз продаж или оттока клиентов может строиться на основе исторических данных с точностью до 85–90% при корректной настройке модели.
Data Scientist также отвечает за визуализацию данных и передачу результатов другим отделам компании. Инструменты, такие как Tableau, Power BI или matplotlib, позволяют создавать наглядные дашборды, которые помогают менеджерам принимать решения на основе цифр, а не интуиции.
В работе важна способность интегрировать данные из разных источников: баз SQL, API, облачных хранилищ и CSV-файлов. Специалист оценивает качество данных, удаляет дубликаты и выбросы, чтобы прогнозы и аналитические отчеты были достоверными и применимыми в бизнес-практике.
Data Scientist участвует в решении конкретных задач: сегментации клиентов, оптимизации маркетинговых кампаний, выявлении мошенничества, прогнозировании спроса. От уровня подготовки и опыта специалиста зависит скорость анализа и точность результатов, что напрямую влияет на экономический эффект для компании.
Какие навыки программирования нужны Data Scientist
Для анализа данных Data Scientist чаще всего использует Python и R. Python применяется для обработки больших массивов данных, работы с библиотеками pandas, NumPy и SciPy, а также для построения моделей машинного обучения с помощью scikit-learn и TensorFlow. R востребован для статистического анализа, визуализации данных через ggplot2 и построения прогнозных моделей.
Знание SQL необходимо для извлечения данных из реляционных баз. Data Scientist должен уметь писать запросы для объединения таблиц, фильтрации данных и агрегации показателей. В проектах с распределёнными системами актуальны навыки работы с Hive и Spark SQL.
Опыт работы с инструментами обработки больших данных, такими как Apache Spark или Hadoop, позволяет специалисту ускорять вычисления и эффективно обрабатывать терабайты информации. Data Scientist использует эти технологии для подготовки данных перед анализом и обучением моделей.
Навыки скриптинга и автоматизации на Bash или Python помогают создавать пайплайны данных, которые ежедневно обновляют отчеты и модели. Понимание принципов объектно-ориентированного программирования и работы с API расширяет возможности интеграции данных из внешних сервисов.
Дополнительным преимуществом является знание языков визуализации, таких как JavaScript с библиотеками D3.js, для создания интерактивных дашбордов, где менеджеры и аналитики могут быстро интерпретировать результаты анализа.
Как Data Scientist работает с большими данными

Работа с большими данными требует использования распределённых систем хранения и вычислений. Data Scientist применяет технологии Hadoop и Apache Spark для обработки терабайтов информации, чтобы ускорить анализ и избежать перегрузки локальных ресурсов.
Процесс работы включает несколько этапов:
- Сбор данных: интеграция информации из баз SQL, NoSQL, облачных хранилищ, API и CSV/JSON-файлов.
- Очистка данных: удаление дубликатов, обработка пропусков, нормализация значений, фильтрация выбросов.
- Трансформация: агрегация, объединение таблиц, создание новых признаков для аналитических моделей.
- Хранение и доступ: оптимизация форматов файлов (Parquet, Avro), настройка индексов и кешей для ускорения запросов.
- Обработка потоков данных: использование Kafka или Spark Streaming для анализа данных в реальном времени.
Для анализа больших данных Data Scientist использует параллельные вычисления, распределённое хранение и оптимизацию кода. В Python применяются Dask и PySpark для ускорения вычислений, в R – пакеты data.table и sparklyr. Такой подход позволяет строить прогнозные модели и отчеты даже при объёмах данных в десятки и сотни гигабайт.
Методы анализа данных в работе Data Scientist

Data Scientist применяет несколько ключевых методов анализа данных, чтобы выявлять закономерности и строить прогнозы. Статистический анализ включает вычисление средних, медиан, дисперсий и корреляций, что позволяет определить зависимость между признаками и отобрать ключевые факторы для модели.
Регрессионный анализ используется для прогнозирования количественных показателей. На практике применяются линейная регрессия для трендовых прогнозов, полиномиальная – для сложных зависимостей, и логистическая регрессия – для классификации событий, например, вероятности оттока клиента.
Методы машинного обучения позволяют строить более сложные модели. Data Scientist использует алгоритмы деревьев решений, случайного леса, градиентного бустинга, кластеризации (K-means, DBSCAN) и нейронные сети для задач классификации, прогнозирования и сегментации данных.
Анализ временных рядов применим к продажам, трафику или показателям сенсоров. Специалист строит модели ARIMA, Prophet или LSTM, чтобы предсказывать будущие значения на основе прошлых наблюдений.
Проверка гипотез помогает оценивать влияние изменений и экспериментов. Data Scientist использует t-тест, ANOVA или χ²-тест, чтобы подтвердить или опровергнуть предположения, влияющие на бизнес-решения.
Выбор метода анализа зависит от типа данных и задачи: для прогнозирования числовых показателей применяются регрессии и временные ряды, для классификации – деревья решений и нейронные сети, для поиска закономерностей – кластеризация и статистические тесты.
Роль статистики и машинного обучения в задачах Data Scientist
Статистика обеспечивает основу для анализа данных, позволяя Data Scientist оценивать распределение признаков, выявлять аномалии и проверять гипотезы. Методы корреляционного анализа и регрессии позволяют определить влияние отдельных факторов на бизнес-показатели, например, как изменение цены продукта влияет на объем продаж.
Машинное обучение используется для построения прогнозных моделей и автоматической классификации данных. Алгоритмы, такие как случайный лес, градиентный бустинг и нейронные сети, позволяют обрабатывать сотни признаков одновременно и повышать точность прогнозов. Например, модель градиентного бустинга может предсказывать вероятность оттока клиента с точностью 87–90% при наличии исторических данных за 2–3 года.
Интеграция статистики и машинного обучения помогает Data Scientist проверять корректность моделей и снижать риск переобучения. Используются методы кросс-валидации, бутстрэппинг и гиперпараметрическая оптимизация, что позволяет создавать более стабильные прогнозы и рекомендации для бизнеса.
Статистика объясняет данные и выявляет закономерности, машинное обучение строит предсказания и автоматизирует обработку информации. Вместе эти инструменты позволяют Data Scientist трансформировать сырые данные в измеримые результаты и управляемые решения.
Инструменты визуализации данных, используемые Data Scientist

Для интерпретации данных и передачи результатов анализа Data Scientist использует как программные библиотеки, так и готовые BI-инструменты. В Python популярны matplotlib и seaborn, которые позволяют строить линейные графики, гистограммы, тепловые карты корреляций и scatter-плоты для изучения зависимостей между признаками.
Plotly и Dash применяются для интерактивной визуализации, где можно динамически фильтровать данные и отслеживать изменения в реальном времени. Это особенно важно для дашбордов с финансовыми показателями или аналитикой пользовательского поведения.
Для корпоративного уровня применяются BI-системы: Tableau и Power BI, где можно объединять данные из разных источников, строить KPI-дашборды и создавать визуальные отчеты для менеджеров. Эти инструменты поддерживают фильтры, drill-down и автоматическое обновление данных.
Выбор инструмента зависит от объема данных, необходимости интерактивности и аудитории: для внутренних аналитических экспериментов используют Python и R, для отчетности и дашбордов – Tableau или Power BI.
Типичные бизнес-задачи, решаемые Data Scientist
Data Scientist решает задачи, которые напрямую влияют на показатели компании: прогнозирование спроса, оптимизация маркетинговых кампаний, выявление аномалий и оттока клиентов. Для систематизации этих задач часто используют таблицы с указанием цели, используемых данных и методов анализа.
| Задача | Используемые данные | Методы анализа |
|---|---|---|
| Прогноз продаж | Исторические продажи, сезонность, акции | Временные ряды, регрессия, машинное обучение |
| Сегментация клиентов | Возраст, поведение на сайте, покупки | Кластеризация (K-means, DBSCAN), PCA |
| Выявление оттока клиентов | История покупок, обращения в поддержку, активность | Логистическая регрессия, деревья решений, градиентный бустинг |
| Оптимизация маркетинговых кампаний | Клики, конверсии, демография | A/B-тестирование, регрессия, рекомендации |
| Обнаружение мошенничества | Транзакции, IP-адреса, поведение пользователей | Аномалии, классификация, алгоритмы ансамблей |
Каждая из этих задач требует подготовки данных, выбора подходящей модели и верификации результатов. Правильное сочетание источников данных и методов анализа позволяет Data Scientist создавать прогнозы и рекомендации, которые повышают доход и снижают риски компании.
Как Data Scientist превращает данные в решения для компании
Data Scientist преобразует сырые данные в управляемые решения через последовательную работу с информацией и моделями. Основные этапы включают:
- Сбор и интеграция данных: объединение информации из SQL- и NoSQL-баз, API, облачных хранилищ и CSV-файлов для формирования единой аналитической среды.
- Очистка и подготовка: удаление дубликатов, обработка пропусков, нормализация значений и создание новых признаков для повышения качества моделей.
- Анализ и построение моделей: применение статистических методов, регрессий, кластеризации и алгоритмов машинного обучения для выявления закономерностей и прогнозов.
- Визуализация и интерпретация: создание графиков, дашбордов и интерактивных отчетов с помощью matplotlib, seaborn, Tableau или Power BI для наглядного представления результатов.
- Рекомендации и внедрение: формулирование конкретных действий для бизнес-подразделений, например, корректировка маркетинговой стратегии или оптимизация запасов на складе.
Результат работы Data Scientist – конкретные решения, которые помогают компании повышать доход, снижать затраты и управлять рисками на основе данных, а не интуиции.
Вопрос-ответ:
Что входит в обязанности Data Scientist на практике?
Data Scientist занимается сбором, очисткой и анализом данных из разных источников. Он строит модели для прогнозирования продаж, оттока клиентов, выявления аномалий, сегментирует аудиторию и создает визуальные отчеты для руководства. Кроме того, специалист разрабатывает рекомендации на основе аналитики и проверяет их результаты через A/B-тесты и статистические проверки.
Какие инструменты и языки программирования используют Data Scientist?
Наиболее часто используются Python и R для анализа данных и построения моделей, SQL для работы с базами, а также библиотеки matplotlib, seaborn и Plotly для визуализации. Для больших данных применяются Apache Spark, Hadoop и Dask, а для интерактивных дашбордов – Tableau, Power BI или Shiny.
Как Data Scientist работает с большими объемами данных?
Специалист использует распределённые системы хранения и обработки данных, такие как Hadoop и Spark, а также оптимизирует код для параллельных вычислений. Данные очищаются от пропусков и дубликатов, создаются новые признаки, выполняются агрегации, после чего строятся модели для прогнозирования и анализа. Для потоковых данных применяются Kafka и Spark Streaming.
Почему важны статистика и машинное обучение в работе Data Scientist?
Статистика позволяет оценивать закономерности, проверять гипотезы и анализировать распределение признаков. Машинное обучение используется для прогнозов, классификации и обнаружения аномалий. Совместное применение этих инструментов позволяет строить точные модели и формировать рекомендации, которые можно применять в бизнес-процессах.
Какие бизнес-задачи решает Data Scientist в компаниях?
Data Scientist помогает прогнозировать спрос и продажи, сегментировать клиентов, оптимизировать маркетинговые кампании, выявлять мошеннические операции и предсказывать отток клиентов. Решения, построенные на анализе данных, позволяют снижать риски и принимать обоснованные решения для увеличения дохода компании.
Какие задачи решает Data Scientist в повседневной работе?
Data Scientist анализирует данные для выявления закономерностей, прогнозирования показателей и поддержки решений компании. Он обрабатывает большие массивы информации, строит модели машинного обучения, сегментирует аудиторию, оценивает результаты экспериментов и создаёт визуальные отчёты, которые помогают отделам принимать решения на основе цифр, а не интуиции.
Какие навыки необходимы для работы Data Scientist?
Специалист должен владеть языками Python и R для анализа данных, SQL для работы с базами, а также инструментами визуализации, такими как matplotlib, seaborn, Tableau или Power BI. Знание алгоритмов машинного обучения, статистических методов, работы с распределёнными системами (Spark, Hadoop) и умение обрабатывать большие объёмы данных позволяют строить прогнозы и рекомендации, применимые в бизнесе.