Содержание статьи

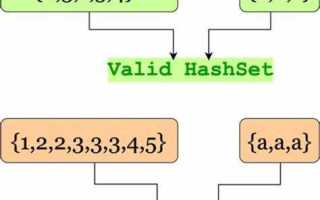
HashSet в Java реализован на основе хэш-таблицы и хранит уникальные объекты без определённого порядка. Каждый элемент при добавлении вычисляет свой hashCode(), что позволяет быстро проверять наличие объекта и управлять коллекцией.
При работе с HashSet важно правильно реализовать методы equals() и hashCode() в пользовательских классах. Неправильная реализация может привести к дублированию элементов или невозможности их корректного поиска.
HashSet не поддерживает индексацию элементов, поэтому доступ по позиции невозможен. Для перебора рекомендуется использовать Iterator или цикл for-each, что обеспечивает безопасный обход даже при изменении коллекции в процессе итерации.
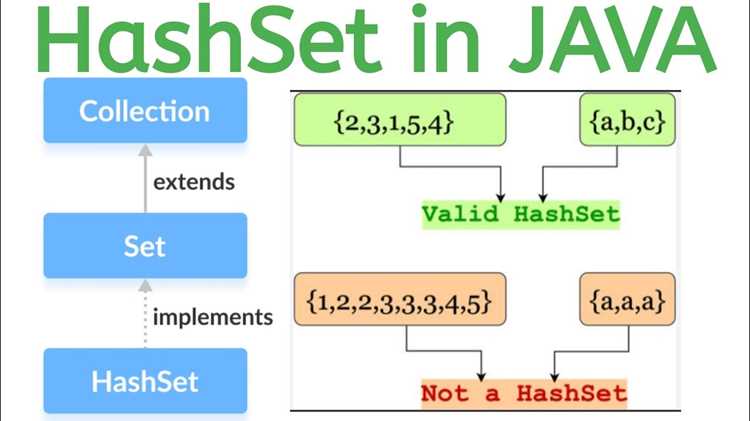
HashSet подходит для хранения множеств данных, где важно исключить повторения: уникальные идентификаторы пользователей, email-адреса, ключи конфигурации. Использование этого класса снижает необходимость ручной проверки на дубликаты и ускоряет операции поиска и удаления.
HashSet в Java: принципы работы и применение
HashSet реализован на основе хэш-таблицы, что обеспечивает быстрый доступ к элементам. Коллекция хранит уникальные объекты и не гарантирует порядок их добавления. Каждый объект при вставке использует метод hashCode() для определения позиции в таблице, а метод equals() проверяет равенство элементов.
Основные характеристики HashSet:
- Скорость операций добавления, удаления и поиска близка к O(1) при равномерном распределении хэшей.
- Отсутствие дубликатов: повторяющийся объект не будет добавлен.
- Неупорядоченность элементов: порядок перебора может отличаться от порядка вставки.
- Поддержка null: коллекция может содержать один элемент null.
Рекомендации по использованию:
- Всегда переопределяйте методы equals() и hashCode() для пользовательских объектов.
- Для перебора используйте Iterator или цикл for-each, избегая обращения по индексу.
- При больших объемах данных учитывайте размер начальной хэш-таблицы и коэффициент загрузки для снижения числа коллизий.
- HashSet подходит для хранения уникальных идентификаторов, email-адресов, ключей конфигураций и любых коллекций, где важна уникальность.
Правильная настройка и понимание работы HashSet позволяет оптимизировать производительность приложений и исключить логические ошибки при работе с множествами объектов.
Создание HashSet и добавление элементов
HashSet создается с использованием класса java.util.HashSet. Конструкторы позволяют задать начальную емкость и коэффициент загрузки, что влияет на производительность при добавлении большого числа элементов.
Примеры создания:
- HashSet<String> set = new HashSet<>(); – стандартный конструктор без параметров.
- HashSet<Integer> set = new HashSet<>(100, 0.75f); – конструктор с начальной емкостью 100 и коэффициентом загрузки 0.75.
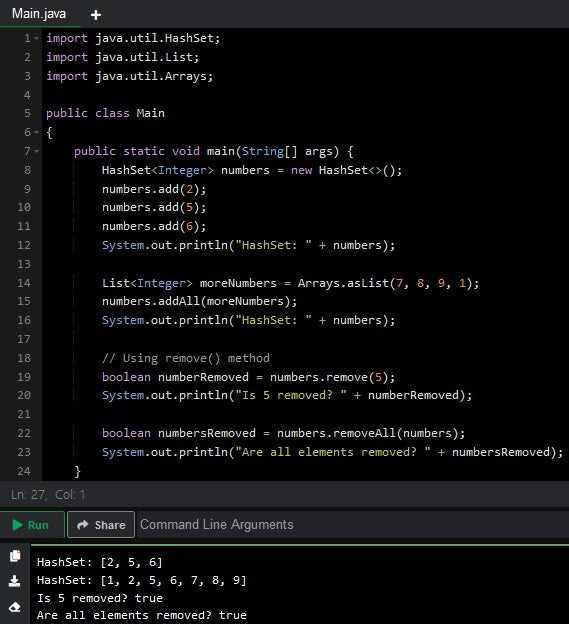
Добавление элементов выполняется методом add(). Если объект уже существует, добавление игнорируется.
Особенности добавления:
- Для пользовательских объектов обязательно реализовать hashCode() и equals() для корректного определения уникальности.
- Добавление null допускается, но только один раз.
- При массовой вставке коллекций рекомендуется использовать конструктор HashSet(Collection<? extends E> c), чтобы избежать множественных перераспределений таблицы.
Метод addAll() позволяет объединять элементы другой коллекции, одновременно фильтруя дубликаты и сокращая количество итераций по отдельным элементам.
Удаление элементов и проверка наличия объекта
Для удаления элементов из HashSet используется метод remove(Object o). Он возвращает true, если элемент был найден и удален, и false, если объекта в коллекции нет.
Особенности удаления:
- Удаление null возможно, если он присутствует в коллекции.
- При работе с пользовательскими объектами корректная реализация equals() и hashCode() обязательна для точного определения удаляемого элемента.
- Метод clear() очищает всю коллекцию, освобождая память хэш-таблицы.
Проверка наличия объекта выполняется методом contains(Object o). Он использует хэш-код и метод equals для поиска элемента, обеспечивая быстрый доступ без перебора всех элементов.
Рекомендации по проверке и удалению:
- Перед удалением пользовательских объектов проверяйте их присутствие с помощью contains(), чтобы избежать ненужных операций.
- При работе с большими множествами данных использование removeAll() или retainAll() позволяет удалять или оставлять элементы из другой коллекции за одну итерацию.
- Методы удаления и проверки учитывают уникальность элементов, поэтому дубликаты автоматически игнорируются.
Обход элементов HashSet с использованием Iterator и for-each
Для перебора элементов HashSet используются два основных способа: цикл for-each и интерфейс Iterator. Оба метода обходят коллекцию без гарантии порядка, так как HashSet не сохраняет последовательность вставки.
Цикл for-each удобен для простого чтения элементов:
- for (String item : set) { } – позволяет обрабатывать каждый элемент без необходимости управления курсором.
Iterator предоставляет дополнительные возможности, включая безопасное удаление элементов во время обхода:
- Iterator<String> it = set.iterator();
- while (it.hasNext()) { String item = it.next(); it.remove(); } – удаляет текущий элемент безопасно без ConcurrentModificationException.
Рекомендации:
- Используйте for-each для простого чтения и обработки данных.
- Iterator выбирайте при необходимости модификации коллекции во время обхода.
- Не пытайтесь обращаться к элементам по индексу – HashSet не поддерживает позиционную адресацию.
Влияние метода hashCode() на работу HashSet
Метод hashCode() определяет позицию объекта в хэш-таблице HashSet. Корректная реализация напрямую влияет на производительность и уникальность элементов. Если hashCode() возвращает одинаковое значение для разных объектов, возникают коллизии, что замедляет операции добавления и поиска.
Принцип работы HashSet с hashCode():
| Действие | Описание |
|---|---|
| Добавление элемента | Вычисляется hashCode(), выбирается бакет. Если бакет пустой, элемент помещается напрямую. При совпадении hashCode() вызывается equals() для проверки уникальности. |
| Проверка наличия элемента | HashSet ищет объект в бакете по hashCode() и использует equals() для точного сопоставления. |
| Удаление элемента | Определяется бакет по hashCode(), затем объект сравнивается через equals() и удаляется. |
Рекомендации:
- Для пользовательских классов реализуйте hashCode() так, чтобы уменьшить количество коллизий.
- Используйте одинаковые поля для hashCode() и equals(), чтобы обеспечить корректное определение уникальности.
- Для immutable объектов hashCode() можно кэшировать, ускоряя повторные операции.
Реализация equals() и корректное сравнение объектов
Метод equals() отвечает за определение равенства объектов в HashSet. Если equals() реализован некорректно, коллекция может содержать дубликаты или неправильно определять наличие элемента.
Основные принципы реализации equals():
| Принцип | Описание |
|---|---|
| Рефлексивность | Объект должен быть равен самому себе: obj.equals(obj) всегда true. |
| Симметричность | Если a.equals(b) true, то b.equals(a) также true. |
| Транзитивность | Если a.equals(b) и b.equals(c) true, то a.equals(c) также true. |
| Согласованность с hashCode() | Если два объекта равны equals(), их hashCode() должен быть одинаковым. |
Рекомендации:
- Использовать для сравнения те поля, которые определяют уникальность объекта в бизнес-логике.
- Не включать изменяемые поля в equals(), чтобы избежать некорректной работы коллекции при изменении объекта.
- Проверять null перед сравнением, чтобы избежать NullPointerException.
- При переопределении equals() всегда переопределяйте hashCode(), соблюдая контракт между методами.
Проблемы с дублированием и уникальность элементов
HashSet гарантирует хранение только уникальных элементов, но корректность этой функции зависит от правильной реализации hashCode() и equals(). Если эти методы реализованы некорректно, один и тот же объект может появляться несколько раз.
Основные причины дублирования:
- Несогласованность между equals() и hashCode(): объекты равны equals(), но имеют разные hashCode().
- Изменение полей объекта после добавления в HashSet, влияющих на hashCode(), что делает объект недоступным для поиска.
- Добавление элементов разных классов с несовместимыми реализациями equals().
Рекомендации по обеспечению уникальности:
- Использовать неизменяемые объекты или поля, участвующие в hashCode() и equals().
- Проверять наличие объекта с помощью contains() перед повторным добавлением, если есть сомнения в уникальности.
- Для массовой вставки использовать конструктор HashSet(Collection<? extends E> c), который автоматически фильтрует дубликаты.
- Тестировать поведение коллекции на примерах с одинаковыми и разными объектами, чтобы убедиться в корректной работе equals() и hashCode().
Сравнение HashSet с другими коллекциями Java
HashSet хранит уникальные элементы без порядка и обеспечивает быстрый доступ благодаря хэш-таблице. Отличия от других коллекций:
- ArrayList: поддерживает индексацию и порядок добавления, допускает дубликаты. Поиск элементов занимает O(n), в отличие от HashSet с близкой к O(1) скоростью.
- LinkedHashSet: наследует свойства HashSet, но сохраняет порядок вставки. Удобен, когда важен последовательный обход элементов.
- TreeSet: хранит элементы в отсортированном порядке по естественному порядку или Comparator. Операции имеют сложность O(log n), что медленнее HashSet при больших объемах данных.
- HashMap: реализует хранение пар ключ-значение. HashSet можно рассматривать как обертку над HashMap с использованием ключей без значений.
Рекомендации по выбору коллекции:
- Используйте HashSet для хранения уникальных объектов, когда порядок не важен.
- Выбирайте LinkedHashSet для сохранения последовательности вставки без дубликатов.
- TreeSet применяйте для хранения отсортированных множеств, когда важен порядок элементов.
- HashMap используют, когда требуется сопоставление ключ-значение с быстрым доступом по ключу.
Примеры использования HashSet в реальных задачах

HashSet подходит для хранения уникальных данных и решения задач, где важно исключить дублирование.
Примеры применения:
- Хранение уникальных идентификаторов пользователей в системе для быстрого поиска и проверки существования.
- Сбор уникальных email-адресов при обработке списков рассылки или регистраций.
- Фильтрация повторяющихся элементов из массивов или других коллекций с помощью метода addAll().
- Реализация множества тегов или категорий для контента с последующим быстрым поиском и проверкой принадлежности.
- Обнаружение повторов при анализе логов или транзакций, когда необходимо исключить дубликаты записей.
Рекомендации при использовании:
- Для больших объемов данных задавайте начальную емкость и коэффициент загрузки, чтобы снизить количество перераспределений хэш-таблицы.
- Для пользовательских объектов обязательно реализуйте equals() и hashCode(), чтобы HashSet корректно идентифицировал уникальные элементы.
- Используйте Iterator для безопасного удаления элементов во время перебора.
- Для объединения нескольких коллекций без дубликатов применяйте addAll() и фильтруйте данные заранее.
Вопрос-ответ:
Как создать HashSet и добавить в него элементы?
Для создания HashSet используется класс java.util.HashSet. Простейший вариант: HashSet<String> set = new HashSet<>();. Элементы добавляются методом add(). Если объект уже присутствует, он не будет добавлен повторно. Для пользовательских объектов необходимо корректно реализовать equals() и hashCode(), чтобы коллекция правильно определяла уникальность элементов.
Чем HashSet отличается от ArrayList и LinkedList?
HashSet не хранит порядок добавления и обеспечивает быстрый поиск по хэшу, а ArrayList и LinkedList поддерживают индексацию и порядок вставки, но поиск элементов требует перебора. HashSet автоматически исключает дубликаты, тогда как списки допускают повторяющиеся объекты.
Почему важно правильно реализовать методы hashCode() и equals() при работе с HashSet?
HashSet использует hashCode() для выбора бакета в хэш-таблице и equals() для проверки равенства объектов внутри бакета. Если hashCode() возвращает одинаковое значение для разных объектов, увеличивается число коллизий и замедляется поиск. Некорректная реализация equals() может привести к дублированию элементов, которые логически должны быть одинаковыми.
Можно ли удалять элементы из HashSet во время перебора коллекции?
Да, для безопасного удаления используется интерфейс Iterator. Цикл for-each не позволяет изменять коллекцию во время обхода без возникновения ConcurrentModificationException. Пример: Iterator<String> it = set.iterator(); while(it.hasNext()){ String item = it.next(); it.remove(); }. Это позволяет удалять текущий элемент безопасно во время итерации.