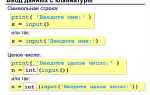
STL (Standard Template Library) в C++ представляет собой набор шаблонов классов и функций для работы с контейнерами, алгоритмами и итераторами. Она включает готовые структуры данных, такие как vector, map, set, что позволяет хранить и обрабатывать данные без ручного управления памятью.
Контейнер vector подходит для хранения последовательностей элементов с динамическим изменением размера. Для быстрого поиска и сортировки используется map и unordered_map, которые обеспечивают ассоциативное хранение данных с доступом по ключу. Set гарантирует уникальность элементов и удобен для фильтрации повторов.
Алгоритмы STL позволяют выполнять операции, такие как сортировка, поиск, копирование и объединение контейнеров без написания дополнительных циклов. Итераторы обеспечивают универсальный доступ к элементам контейнеров и совместимы с большинством алгоритмов, что упрощает модификацию и обработку данных.
Применение STL ускоряет разработку и уменьшает вероятность ошибок при работе с памятью и структурой данных. Для практических задач рекомендуется выбирать контейнер исходя из характера операций: vector для последовательного доступа, map для поиска по ключу, set для проверки уникальности элементов.
Основные контейнеры STL и их назначение
STL включает несколько типов контейнеров, разделённых на последовательные и ассоциативные, каждый из которых решает специфические задачи хранения и обработки данных.
Последовательные контейнеры позволяют хранить элементы в порядке вставки и поддерживают итерационный доступ:
- vector – динамический массив, быстрый доступ по индексу, добавление в конец с амортизированной сложностью O(1).
- deque – двусторонняя очередь, обеспечивает эффективное добавление и удаление элементов с обеих сторон.
- list – двусвязный список, оптимален при частых вставках и удалениях в середине последовательности.
- forward_list – односвязный список, экономит память, подходит для обхода только в прямом направлении.
Ассоциативные контейнеры организуют элементы по ключу для быстрого поиска и упорядочивания:
- set – множество уникальных элементов, автоматически упорядоченных по ключу.
- map – отображение ключ → значение, ключи уникальны, поддерживает быструю вставку и поиск.
- unordered_set и unordered_map – аналоги set и map на основе хеш-таблиц, доступ к элементам за константное время в среднем.
Выбор контейнера зависит от характера операций: vector подходит для случайного доступа и последовательной обработки, list – для частых вставок и удалений, map и set – для поиска и хранения уникальных значений, unordered_map – при необходимости ускоренного доступа к данным.
Использование векторов для динамических массивов
Контейнер vector представляет собой динамический массив, размер которого автоматически изменяется при добавлении или удалении элементов. Он обеспечивает доступ к элементам по индексу за константное время O(1) и поддерживает итераторы для обхода.
Для добавления элементов в конец используется метод push_back(), который увеличивает размер массива и при необходимости выделяет дополнительную память. Метод emplace_back() позволяет вставлять элементы напрямую без копирования, что ускоряет работу с объектами сложных типов.
Удаление элементов из конца осуществляется с помощью pop_back(). Для удаления элементов из середины или начала следует применять методы erase() или insert() с итераторами, учитывая, что это требует сдвига оставшихся элементов.
Для оптимизации памяти можно использовать reserve() для предварительного выделения места под заданное количество элементов, что снижает количество перераспределений при последовательных вставках.
Vector подходит для хранения больших последовательностей с частым доступом по индексу и редкими вставками или удалениями в середине. Для задач, где важна скорость вставки в середину, лучше рассмотреть list или deque.
Работа с множествами и уникальными элементами
Контейнер set используется для хранения уникальных элементов в упорядоченном виде. Все вставляемые значения автоматически сортируются по возрастанию, что обеспечивает быстрый поиск, вставку и удаление за логарифмическое время O(log n).
Для хранения уникальных элементов без порядка используется unordered_set. Он реализован на основе хеш-таблиц и обеспечивает доступ к элементам за константное время в среднем, что полезно при необходимости быстрого поиска.
Основные операции для работы с множествами:
- insert(value) – добавляет элемент, если его ещё нет в контейнере.
- erase(value) – удаляет элемент по значению.
- find(value) – проверяет наличие элемента и возвращает итератор.
- count(value) – возвращает 0 или 1 для set и unordered_set, указывая наличие элемента.
Для объединения, пересечения и разности множеств STL предоставляет алгоритмы set_union, set_intersection и set_difference. Они работают с отсортированными контейнерами, что позволяет использовать set напрямую.
Рекомендуется выбирать set при необходимости упорядочивания и логарифмического доступа, а unordered_set – для задач с интенсивным поиском без требований к порядку элементов.
Применение ассоциативных контейнеров: map и unordered_map
Ассоциативные контейнеры map и unordered_map хранят пары ключ → значение и обеспечивают быстрый доступ к элементам по ключу. Map поддерживает автоматическую сортировку ключей по возрастанию, а unordered_map использует хеш-таблицы для константного доступа в среднем.
Основные методы работы с этими контейнерами:
| Метод | Описание |
|---|---|
| insert({key, value}) | Добавляет пару ключ → значение, игнорирует существующий ключ в map, перезаписывает в unordered_map через оператор [] |
| operator[key] | Возвращает ссылку на значение по ключу, создаёт новый элемент при отсутствии ключа |
| erase(key) | Удаляет элемент по ключу |
| find(key) | Возвращает итератор на элемент или end(), если ключ отсутствует |
| count(key) | Возвращает 1 при наличии ключа и 0 при отсутствии (для map и unordered_map) |
Map подходит, когда требуется хранить ключи в отсортированном виде и обеспечивать логарифмическое время операций. Unordered_map эффективен для быстрого поиска и вставки без необходимости сортировки ключей.
Для подсчёта частоты появления элементов, кэширования и реализации словарей рекомендуется использовать unordered_map, а для хранения данных с упорядоченными ключами – map.
Сортировка и поиск с алгоритмами STL

STL предоставляет готовые алгоритмы для сортировки и поиска элементов в контейнерах, что позволяет избегать ручной реализации этих операций. Основной алгоритм сортировки – sort(), который работает с vector и deque и использует быструю сортировку с временем выполнения O(n log n) в среднем.
Для частичной сортировки или нахождения минимальных/максимальных элементов применяются алгоритмы partial_sort(), min_element() и max_element(). Они позволяют обрабатывать только нужную часть контейнера, экономя ресурсы.
Поиск элементов выполняется с помощью binary_search() для отсортированных последовательностей и find() для любых контейнеров. Lower_bound() и upper_bound() возвращают позиции вставки или границы значений, что удобно для работы с диапазонами.
Для упорядоченных контейнеров set и map сортировка не требуется, так как ключи уже расположены по возрастанию. В этих случаях поиск выполняется за логарифмическое время с помощью find() и count().
Рекомендуется применять sort() для vector, а для частых вставок и удалений в отсортированном контейнере использовать алгоритмы с ассоциативными контейнерами для минимизации операций с памятью.
Итераторы и их роль в обходе контейнеров

Итераторы в STL представляют собой объекты, которые обеспечивают последовательный доступ к элементам контейнеров без прямого использования индексов. Они совместимы с большинством алгоритмов STL, что позволяет применять сортировку, поиск и модификацию данных универсально для разных типов контейнеров.
Основные типы итераторов:
- Input Iterator – поддерживает последовательное чтение элементов.
- Output Iterator – используется для записи элементов в контейнер.
- Forward Iterator – комбинирует чтение и запись с возможностью обхода в прямом направлении несколько раз.
- Bidirectional Iterator – позволяет перемещаться вперёд и назад, используется в list и set.
- Random Access Iterator – обеспечивает доступ по индексу, как в vector и deque.
Для обхода контейнера применяются методы begin() и end(), возвращающие итераторы на первый и последний элемент. Использование итераторов минимизирует ошибки при работе с указателями и упрощает переносимость кода между разными типами контейнеров.
Рекомендуется применять итераторы при любых операциях с STL, включая вставку, удаление и сортировку, так как они совместимы с алгоритмами STL и обеспечивают безопасный доступ к элементам контейнера без прямой работы с памятью.
Использование стека и очереди для управления данными
Контейнер stack реализует принцип LIFO (Last In, First Out), позволяя добавлять элементы с помощью push() и удалять верхний элемент через pop(). Метод top() возвращает текущий верхний элемент без удаления. Стек подходит для обработки задач с обратным порядком выполнения, таких как разбор выражений или сохранение состояния вызовов функций.
Контейнер queue реализует принцип FIFO (First In, First Out). Элементы добавляются с помощью push() и извлекаются через pop(), доступ к первому элементу осуществляется через front(). Для двустороннего доступа используется deque или priority_queue, где элементы извлекаются в порядке приоритета.
Основные операции стека и очереди:
- empty() – проверка на наличие элементов.
- size() – количество элементов в контейнере.
- push() – добавление элемента в конец (для очереди) или верх (для стека).
- pop() – удаление элемента с конца (стек) или начала (очередь).
Стек рекомендуется использовать для алгоритмов обратного обхода и рекурсивных структур, очередь – для организации обработки данных по порядку поступления, а priority_queue – для сортировки по приоритету без дополнительной сортировки контейнера.
Примеры типовых задач с применением STL
STL упрощает решение многих стандартных задач на хранение и обработку данных. Примеры:
- Подсчёт частоты элементов в массиве с помощью unordered_map. Каждый элемент используется как ключ, значение хранит количество вхождений.
- Сортировка списка объектов по полю с применением sort() и пользовательской функции сравнения, работающей с vector.
- Удаление дубликатов из последовательности с помощью set или комбинации sort() и unique() для vector.
- Обход и модификация элементов контейнера через итераторы для вставки, удаления или преобразования данных без прямого доступа к индексам.
- Реализация очереди задач с приоритетом через priority_queue, где новые элементы добавляются с указанием приоритета, а извлекаются наиболее важные.
- Реализация алгоритмов поиска пути или обхода графа с использованием stack и queue для хранения промежуточных состояний.
Использование STL позволяет минимизировать ручное управление памятью, ускоряет разработку и делает код более читаемым и переносимым между различными задачами, где применяются контейнеры и алгоритмы.
Вопрос-ответ:
Что такое STL в C и зачем его использовать?
STL (Standard Template Library) — это библиотека шаблонов C++, включающая контейнеры, алгоритмы и итераторы. Она позволяет хранить данные в готовых структурах, таких как vector, map или set, и выполнять операции с ними без ручного управления памятью. Использование STL ускоряет разработку и уменьшает вероятность ошибок при работе с динамическими массивами, ассоциативными структурами и алгоритмами сортировки или поиска.
Какие основные контейнеры предоставляет STL и в чем их различие?
STL делит контейнеры на последовательные и ассоциативные. Последовательные (vector, deque, list, forward_list) хранят элементы в порядке вставки и обеспечивают доступ по индексу или через итераторы. Ассоциативные (set, map, unordered_set, unordered_map) организуют данные по ключу, поддерживают поиск, вставку и удаление элементов без перебора всего контейнера. Выбор зависит от требований к скорости доступа и способу обработки данных.
Как использовать vector для динамических массивов и какие методы наиболее полезны?
Vector позволяет хранить элементы с динамическим изменением размера. Основные методы: push_back() для добавления в конец, pop_back() для удаления последнего элемента, insert() и erase() для работы с элементами в середине. Метод reserve() позволяет заранее выделить память, снижая количество перераспределений. Для вставки объектов без копирования используется emplace_back(). Vector подходит для задач с частым доступом по индексу и редкими вставками или удалениями.
Когда стоит использовать set и unordered_set для работы с уникальными элементами?
Set автоматически упорядочивает элементы по возрастанию и обеспечивает логарифмическое время поиска, вставки и удаления, что удобно для хранения уникальных значений в отсортированном виде. Unordered_set использует хеш-таблицы, обеспечивает доступ за константное время в среднем и подходит для задач, где важен быстрый поиск без требования сортировки. Выбор зависит от необходимости порядка элементов и скорости доступа.
Как применять алгоритмы STL для сортировки и поиска элементов?
Для сортировки последовательностей используется sort(), для частичной сортировки – partial_sort(). Алгоритмы min_element() и max_element() находят минимальные и максимальные значения. Для поиска применяется find() для любых контейнеров и binary_search() для отсортированных. Для работы с диапазонами значений используют lower_bound() и upper_bound(). Ассоциативные контейнеры set и map не требуют сортировки, доступ к элементам выполняется через find() и count().
Как выбрать подходящий контейнер STL для конкретной задачи в C++?
Выбор контейнера зависит от характера операций с данными. Если требуется последовательный доступ и частый доступ по индексу, лучше использовать vector. Для частых вставок и удалений в середине последовательности подходит list или deque. Когда важен быстрый поиск по ключу, используют map или unordered_map. Для хранения уникальных элементов с автоматической сортировкой применяется set, а для быстрого поиска без сортировки – unordered_set. Кроме того, для работы с последовательностями, где важен порядок добавления и удаление с обеих сторон, применяют stack и queue. Рекомендуется оценивать частоту операций вставки, удаления, поиска и сортировки, чтобы подобрать контейнер с подходящими характеристиками и минимальными затратами на перераспределение памяти.