Содержание статьи

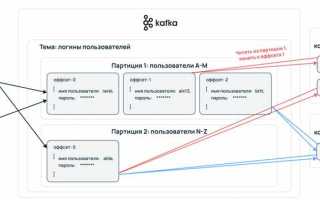
Kafka lag показывает разницу между смещением последнего сообщения в партиции и смещением, которое уже обработал потребитель. Это числовой показатель, по которому можно понять, насколько быстро приложение успевает разбирать входящие данные. Если значение растёт, поток сообщений начинает сдвигаться вперёд быстрее, чем его читает клиент.
Для оценки состояния системы используют значения current offset, log end offset и consumer offset. Эти параметры позволяют вычислить величину отставания и определить, связано ли оно с пропускной способностью, задержками в логике обработки или настройками партиций. Чем точнее измерения, тем проще установить причину сбоя.
При анализе лагов важно учитывать скорость поступления данных, количество активных потоков обработки и поведение групп потребителей. Если один из инстансов замедляется, нагрузка перераспределяется, и разрыв в смещениях становится заметен. Правильная интерпретация этих показателей помогает выявлять узкие места в приложении и корректировать настройки до появления перегрузок.
Как формируется задержка между продюсером и потребителем в Kafka
Задержка возникает из-за разницы между смещением, записанным продюсером, и смещением, которое фиксирует потребитель. Когда продюсер публикует сообщения быстрее, чем их успевает разбирать клиент, значение log end offset уходит вперёд, а consumer offset остаётся позади. Разрыв между ними и есть lag.
На величину отставания влияет размер партиции, режим подтверждений продюсера, скорость дисковой подсистемы и время обработки каждого сообщения. Чем больше объём входящего потока или сложнее логика обработки, тем быстрее растёт разница между текущим и обработанным смещением.
Корректная оценка задержки требует сверять показатели produce rate и consume rate. Если скорость записи стабильно выше, клиент будет постоянно уходить в минус по смещениям. Для устранения проблемы стоит увеличивать число потоков обработки, оптимизировать код, изменять размеры batch’ей или распределять нагрузку по нескольким партициям.
Какие метрики Kafka напрямую отражают величину lag
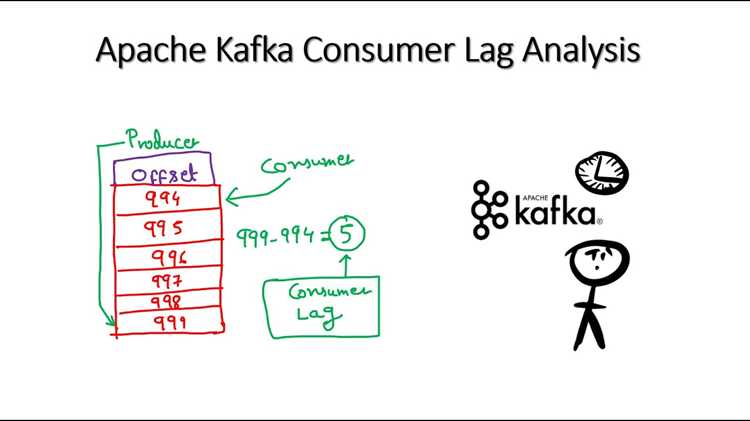
Основными показателями считаются log end offset, current offset и consumer offset. Первый показывает положение последнего сообщения в партиции, второй – текущее состояние лога, третий – смещение, которое уже зафиксировал потребитель. Разница между значениями позволяет оценить масштаб отставания.
Дополнительное значение даёт метрика records-lag, которую предоставляет клиентская библиотека. Она отображает число сообщений, которые предстоит обработать конкретному инстансу. Если это число растёт при неизменном трафике, нагрузка на группу распределяется неравномерно или клиент не справляется с обработкой.
Для оценки динамики используется records-lag-max. Показатель отражает максимальное отставание среди всех потоков в группе. Он помогает обнаружить «медленные» инстансы, которые тормозят работу всей группы и создают перекос в потреблении.
При мониторинге брокеров полезно учитывать log flush time и количество операций записи. Эти данные позволяют понять, не ограничивает ли задержку дисковая подсистема. Если смещения растут быстрее, чем обновляется лог, lag будет увеличиваться даже при быстрой обработке на стороне клиента.
Как интерпретировать рост lag при стабильном трафике
Увеличение lag при неизменном количестве входящих сообщений указывает на снижение скорости обработки. Если produce rate остаётся на прежнем уровне, а consume rate падает даже на 5–10%, разрыв между смещениями начинает расти. Это признак перегруженного кода, задержек при работе с внешними сервисами или нехватки потоков обработки.
Для оценки ситуации удобно сравнивать показатели, влияющие на пропускную способность потребителя.
| Показатель | Значение для интерпретации |
|---|---|
| Среднее время обработки сообщения | Рост на десятки миллисекунд приводит к накоплению lag |
| Количество активных потоков | Меньше числа партиций – часть данных простаивает |
| records-lag-max | Если высокий показатель держится у одного инстанса, есть «медленный» потребитель |
| Время отклика внешних сервисов | Задержки при запросах вызывают падение consume rate |
Если показатели показывают падение скорости только у одной партиции, проблема часто связана с конкретным инстансом. При равномерном увеличении lag во всех партициях стоит проверять состояние хранилища, объём batch’ей и параметры автокоммита. Такой подход помогает определить, что именно замедляет работу при неизменном входящем потоке.
Причины скачков lag при работе потребительских групп
Резкие изменения lag чаще всего связаны с перераспределением партиций во время ребалансировки. В момент пересчёта назначений потребители временно не читают данные, и смещение продюсера уходит вперёд. Чем больше партиций и инстансов, тем заметнее скачок.
Ещё один источник – непредвиденные паузы внутри приложения. Если поток обработки блокируется из-за долгих запросов к базе, работы с файловой системой или ожиданий внутри сторонних библиотек, объём непрочитанных сообщений растёт. Падение производительности одного инстанса создаёт перекос во всей группе.
Скачки наблюдаются и при задержках в фиксации смещений. Если автокоммит срабатывает реже, чем происходит чтение сообщений, брокер некоторое время считает, что потребитель не продвинулся. Это создаёт видимость резкого роста разрыва между смещениями.
При анализе подобных случаев важно проверять временные метки ребалансировок, количество перераспределённых партиций, интервалы коммита и латентность внешних операций. Такой подход помогает выявить конкретный участок, который вызывает кратковременное накопление непрочитанных сообщений.
Как проверять скорость обработки сообщений относительно скорости записи
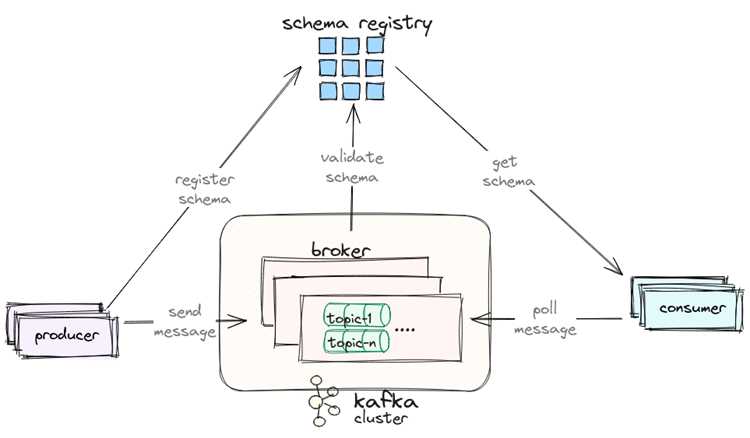
Для оценки соотношения скоростей используют два показателя: produce rate и consume rate. Первый отображает количество сообщений, которое продюсер отправляет в секунду, второй – сколько сообщений потребитель реально обрабатывает. Если второй показатель ниже хотя бы на 5–15%, lag начинает расти даже при небольшом входящем потоке.
Проверка проводится через системные метрики клиента и данные брокера. Значения records-consumed-rate и records-produced-rate позволяют сравнивать пропускную способность в режиме реального времени. Если показатели показывают устойчивый дисбаланс, следует анализировать длительность обработки, размеры batch’ей и наличие блокировок в коде.
Для долгосрочной оценки важно измерять разницу между log end offset и consumer offset на разных временных промежутках. Если разрыв увеличивается при стабильном трафике, приложение не успевает обрабатывать записи с той же скоростью, с какой они появляются в логе.
При исследовании причин полезно фиксировать интервалы чтения и проверки смещений. Если обработка занимает больше времени, чем интервал коммита, потребитель продвигается медленнее, чем растёт общий объём данных. Это позволяет точно определить, какой участок снижает скорость и вызывает отставание.
Как связать lag с настройками партиций и числом инстансов потребителя
В Kafka величина lag напрямую зависит от структуры топика и числа активных потребителей. Каждый топик разбивается на партиции, и каждая партиция может быть обработана только одним инстансом потребителя внутри группы. Если партиций меньше, чем инстансов, часть потребителей будет простаивать, а lag не уменьшится.
Основные рекомендации:
- Поддерживать количество партиций не меньше числа инстансов потребителя, чтобы загрузка распределялась равномерно.
- Следить за балансировкой нагрузки: при росте числа партиций увеличивается параллелизм, но растет нагрузка на брокеры.
- Использовать consumer rebalancing для автоматического перераспределения партиций при добавлении новых инстансов.
Пример влияния настроек:
- Топик с 4 партициями и 2 инстансами: каждый инстанс обрабатывает по 2 партиции. Lag распределяется равномерно.
- Топик с 4 партициями и 6 инстансами: 2 инстанса остаются без нагрузки, общий lag сокращается медленно.
- Топик с 8 партициями и 4 инстансами: каждый инстанс получает по 2 партиции, обработка ускоряется, lag падает быстрее.
Следует учитывать, что увеличение числа партиций требует больше ресурсов на стороне брокеров и может влиять на задержку записи. Оптимальное сочетание числа партиций и инстансов потребителя позволяет минимизировать lag без перегрузки кластера.
Когда высокий lag указывает на проблемы с производительностью брокеров
Высокий lag может возникать не только из-за медленной обработки потребителей, но и из-за ограничений на стороне брокеров. Если брокеры не успевают записывать сообщения или обслуживать запросы, lag растет независимо от скорости потребителей.
Основные признаки проблем с производительностью брокеров:
- Увеличение времени отклика produce и fetch запросов.
- Рост очередей сообщений на брокерах (проверяется через метрики UnderReplicatedPartitions и ActiveControllerCount).
- Частые ISR changes (изменения списка реплик, которые вовремя не синхронизированы).
Рекомендации для анализа и устранения:
- Мониторить broker throughput и disk I/O, чтобы определить узкие места записи.
- Сравнивать lag на разных брокерах: если один из брокеров постоянно отстает, возможно, перегружен диск или сеть.
- Регулировать num.replica.fetchers и replica.lag.time.max.ms для ускорения синхронизации реплик.
- При необходимости добавлять брокеры в кластер для распределения нагрузки.
Высокий lag указывает на системную проблему, если потребители не испытывают ограничений. В таких случаях проверка метрик брокеров позволяет выявить узкие места и принять меры для снижения задержки обработки сообщений.