Содержание статьи

При работе со строками в Python нередко возникает задача полного удаления цифр из текстовых данных. Это актуально при очистке пользовательского ввода, обработке логов, подготовке данных для анализа или нормализации строк перед сравнением. Например, телефонные номера, артикулы или идентификаторы могут быть встроены в текст и мешать дальнейшей логике программы.
Python предоставляет сразу несколько инструментов для решения этой задачи, и выбор подхода напрямую зависит от контекста. В одних случаях важна поддержка Unicode-цифр, в других – минимальное количество кода или наглядность решения. Ошибочный выбор метода может привести к некорректной обработке символов или усложнению поддержки кода.
Для удаления цифр можно использовать базовые возможности строк, встроенные функции языка и модуль re. Каждый способ по-разному обрабатывает символы, отличается по читаемости и поведению на нестандартных данных. Например, метод isdigit() удаляет не только символы от 0 до 9, но и числовые знаки из других письменностей.
В этой статье рассматриваются прикладные способы удаления всех цифр из строки в Python с разбором их особенностей, ограничений и типичных сценариев применения. Материал ориентирован на практическое использование в реальных проектах, а не на абстрактные примеры.
Использование метода str.replace() в цикле по цифрам
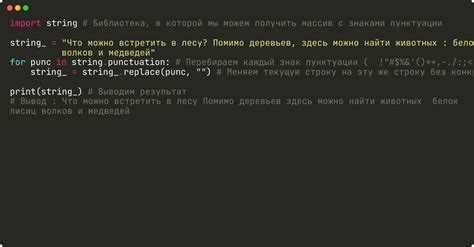
Типовая реализация выглядит как цикл по строковому диапазону цифр:
text = "Версия Python 3.12 вышла в 2024 году"
for d in "0123456789":
text = text.replace(d, "")
После выполнения цикла в строке не останется ни одного ASCII-цифрового символа. Метод replace() удаляет все вхождения символа за один вызов, что упрощает логику и делает код легко читаемым даже для начинающих разработчиков.
Важно учитывать, что данный способ работает только с цифрами от 0 до 9 и не затрагивает Unicode-цифры, такие как ١ или 4. Это делает его подходящим для обработки технических строк, логов, версий программ и других данных со строго заданным форматом.
Метод не требует импорта модулей и хорошо подходит для коротких строк. Однако при обработке больших объемов текста стоит помнить, что каждое преобразование создает новую строку, что увеличивает количество операций копирования в памяти.
Рекомендуется использовать этот вариант в случаях, когда приоритетом является наглядность кода и предсказуемое поведение без учета расширенных наборов символов.
Удаление цифр с помощью генератора строк и условия isdigit()
Генератор строк в сочетании с методом str.isdigit() позволяет удалить цифры за один проход по строке. Подход основан на посимвольной фильтрации, где в результирующую строку включаются только те символы, которые не распознаются как цифры.
Типовая реализация использует функцию join() и генераторное выражение:
text = "Python 3.12 поддерживает 64-битные системы"
result = "".join(ch for ch in text if not ch.isdigit())
Метод isdigit() возвращает True не только для символов от 0 до 9, но и для Unicode-цифр из других письменностей. Это важно учитывать при обработке данных, поступающих из внешних источников, где возможны нестандартные числовые символы.
Данный способ не изменяет исходную строку и не требует промежуточных замен. Каждое условие проверяется один раз, что делает поведение кода предсказуемым и удобным для анализа. При этом логика удаления цифр явно выражена в одном выражении.
Подход хорошо подходит для очистки пользовательского ввода, текстов с многоязычным содержимым и строк, где заранее неизвестен набор числовых символов. Если требуется сохранить только буквенные и специальные символы без ручного перечисления цифр, использование isdigit() является оправданным выбором.
Применение регулярных выражений с модулем re
Модуль re позволяет удалить цифры из строки с помощью шаблонов, описывающих нужные символы. Для этой задачи чаще всего используется функция re.sub(), которая заменяет все совпадения по шаблону на пустую строку.
Базовый вариант удаления ASCII-цифр выглядит следующим образом:
import re
text = "Релиз версии 3.12 состоялся в 2024 году"
result = re.sub(r"\d", "", text)
Шаблон \d соответствует любой цифре. По умолчанию он учитывает Unicode, поэтому будут удалены не только символы от 0 до 9, но и числовые знаки из других систем письма. Если требуется ограничиться только ASCII-цифрами, необходимо использовать символьный класс [0-9].
| Шаблон | Какие цифры удаляются |
|---|---|
| \d | Все Unicode-цифры |
| [0-9] | Только ASCII-цифры |
Регулярные выражения особенно полезны, когда удаление цифр является частью более сложной обработки строки, например совместно с очисткой пробелов, пунктуации или определённых слов. В таких случаях один вызов re.sub() заменяет несколько этапов фильтрации.
Следует учитывать, что использование re оправдано при наличии шаблонов. Для простых строк без дополнительных условий этот подход усложняет код и требует импорта модуля, что не всегда целесообразно.
Фильтрация символов через функцию filter()
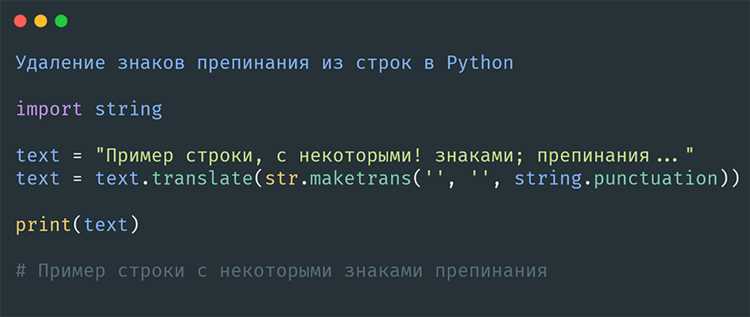
Встроенная функция filter() позволяет удалить цифры из строки, применяя предикат к каждому символу. В контексте обработки строк она работает в паре с функцией, определяющей, какие символы должны остаться в результате.
Чаще всего используется лямбда-выражение с проверкой через isdigit():
text = "Python 3.12 выпущен в 2024"
result = "".join(filter(lambda ch: not ch.isdigit(), text))
Функция filter() возвращает итератор, поэтому для получения строки требуется объединение символов через join(). Проверка выполняется для каждого символа, что обеспечивает полную очистку строки от числовых знаков, включая Unicode-цифры.
По поведению данный подход близок к генератору строк, однако логика фильтрации вынесена в отдельную функцию. Это удобно, если условие отбора символов используется повторно или требуется передавать готовый предикат без переписывания выражений.
При чтении кода важно учитывать, что использование lambda может снижать наглядность для разработчиков без опыта функционального стиля. В таких случаях имеет смысл заменить лямбда-выражение именованной функцией с явным описанием логики.
Фильтрация через filter() подходит для сценариев, где требуется сохранить единый стиль функциональной обработки данных и избежать вложенных выражений внутри генераторов.
Удаление цифр с использованием таблицы перевода str.maketrans()
Метод str.maketrans() позволяет удалить цифры из строки через механизм символьного перевода, минуя явные циклы и проверки. Для этого создаётся таблица, в которой цифры сопоставляются с None, после чего применяется метод translate().
Базовый пример удаления ASCII-цифр выглядит так:
text = "Python 3.12 был выпущен в 2024"
table = str.maketrans("", "", "0123456789")
result = text.translate(table)
Третий аргумент функции maketrans() определяет набор символов, которые будут полностью удалены из строки. Все остальные символы копируются без изменений, что делает результат предсказуемым и стабильным.
Данный способ работает исключительно с явно указанными символами. Это означает, что Unicode-цифры не будут затронуты, если они не добавлены в таблицу перевода. Такой подход подходит для строк со строго заданным форматом, где используются только цифры от 0 до 9.
Использование translate() оправдано при многократной обработке строк одного типа, так как таблица перевода создаётся один раз и может применяться повторно. Это упрощает код и снижает количество операций на уровне Python-логики.
Метод особенно удобен, когда требуется удалить сразу несколько категорий символов, объединяя их в одну строку для третьего аргумента maketrans(), без усложнения условий фильтрации.
Обработка Unicode-цифр и отличие от ASCII-цифр
В Python важно различать ASCII-цифры и Unicode-цифры, так как они по-разному обрабатываются встроенными методами строк. ASCII-набор включает символы от 0 до 9 с кодами от 48 до 57, тогда как Unicode охватывает десятки числовых систем, используемых в различных языках и стандартах.
Примеры Unicode-цифр, которые визуально похожи на привычные числа, но имеют другие кодовые точки:
- арабско-индейские цифры: ٠١٢٣٤٥٦٧٨٩
- персидские цифры: ۰۱۲۳۴۵۶۷۸۹
- полноширинные цифры: 0123456789
Поведение основных методов удаления цифр отличается:
- str.isdigit() возвращает True для всех перечисленных символов, поэтому генераторы строк и filter() удаляют их без дополнительной настройки.
- Регулярное выражение \d в модуле re также учитывает Unicode, если не задан флаг re.ASCII.
- Методы replace() и translate() удаляют только те символы, которые явно указаны разработчиком.
При очистке пользовательского ввода, данных из форм или внешних API рекомендуется учитывать Unicode-цифры, так как визуальный контроль не гарантирует использования ASCII-набора. Для таких случаев предпочтительны методы, опирающиеся на isdigit() или \d.
Если же обрабатываются технические строки с заранее известным форматом, например версии ПО или идентификаторы, ограничение ASCII-цифрами позволяет сохранить полный контроль над результатом и избежать удаления неожиданных символов.
Сравнение способов по читаемости и удобству поддержки кода

Выбор способа удаления цифр напрямую влияет на то, насколько легко код читается и модифицируется в дальнейшем. Даже при одинаковом результате разные подходы по-разному воспринимаются при анализе и сопровождении.
С точки зрения наглядности методы можно условно сгруппировать следующим образом:
- Цикл с str.replace() – понятен без знания дополнительных инструментов, но требует просмотра всего блока кода, чтобы понять, какие символы удаляются.
- Генератор строк с isdigit() – компактно отражает логику фильтрации и сразу показывает критерий отбора символов.
- filter() с лямбда-выражением – читаем для разработчиков, знакомых с функциональным стилем, но может замедлять понимание для остальных.
- re.sub() – лаконичен, если регулярные выражения уже используются в проекте, иначе усложняет вход в код.
- translate() с maketrans() – выглядит необычно, но хорошо масштабируется при удалении фиксированных наборов символов.
При сопровождении кода важна предсказуемость поведения. Подходы, основанные на isdigit() или \d, автоматически охватывают Unicode-цифры, что может быть как преимуществом, так и источником неожиданных изменений при работе с разными данными.
Для командной разработки рекомендуется выбирать способ, который:
- явно показывает критерий удаления символов;
- не требует специальных знаний без необходимости;
- легко расширяется при изменении требований.
В большинстве прикладных задач генератор строк с isdigit() обеспечивает баланс между краткостью, прозрачной логикой и минимальными зависимостями, что упрощает поддержку кода на длительной дистанции.
Вопрос-ответ:
Почему при использовании str.replace() цифры удаляются только от 0 до 9?
Метод str.replace() работает строго с теми символами, которые переданы в аргументах. Если в цикле перечислены только строки «0»–»9″, будут удалены исключительно ASCII-цифры. Числовые символы из других письменностей имеют другие кодовые точки и не совпадают с указанными значениями, поэтому остаются в строке.
Чем отличается поведение isdigit() от проверки символа в диапазоне [0-9]?
isdigit() проверяет принадлежность символа к категории чисел в стандарте Unicode. Это включает арабские, персидские и полноширинные цифры. Проверка через диапазон [0-9] или явный список символов охватывает только ASCII-набор, что даёт иной результат при работе с многоязычными строками.
Можно ли удалить цифры без циклов и условий в коде?
Да, это возможно с помощью метода translate() и таблицы, созданной через str.maketrans(). В таблице задаётся перечень символов, которые нужно убрать, а сама обработка выполняется на уровне внутреннего механизма строк без явных проверок каждого символа.
Почему регулярное выражение \\d удаляет больше символов, чем ожидается?
Шаблон \\d в Python по умолчанию ориентируется на Unicode. Он совпадает с любыми числовыми символами, а не только с привычными цифрами. Чтобы ограничиться ASCII-набором, нужно использовать класс [0-9] или флаг re.ASCII.
Какой способ лучше выбрать для очистки пользовательского ввода?
Для пользовательского ввода чаще подходят варианты с isdigit(), так как они учитывают разные формы числовых символов, которые могут быть вставлены при копировании текста или вводе с мобильных устройств. Такой подход снижает риск пропуска чисел, не относящихся к ASCII.