Содержание статьи

Ceph – это распределённая система хранения данных с открытым исходным кодом, которая объединяет серверы и дисковые устройства в единый кластер. Основная задача Ceph – обеспечить сохранность информации и доступ к ней без узких мест, используя принцип децентрализованного управления данными.
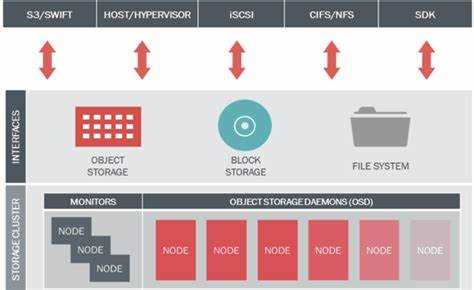
Система разделяет данные на объекты и распределяет их между узлами с помощью алгоритма CRUSH. Это позволяет автоматически балансировать нагрузку, исключать дублирование и обеспечивать высокую отказоустойчивость без необходимости централизованного контроллера. В кластере Ceph каждая единица хранения может быть одновременно задействована для нескольких типов сервисов: блокового, объектного или файлового хранилища.
Ceph поддерживает интеграцию с виртуальными машинами через Ceph Block Device, хранение больших объёмов объектов через Ceph Object Storage и организацию распределённых файловых систем с CephFS. Для администрирования предусмотрены инструменты мониторинга состояния кластера, автоматического восстановления после сбоев и контроля за целостностью данных, что облегчает управление даже крупными инфраструктурами.
При планировании кластера Ceph важно учитывать количество узлов, тип используемых дисков и пропускную способность сети. Для повышения устойчивости рекомендуется настраивать репликацию объектов или использовать кодирование с исправлением ошибок, а также регулярно проверять метрики производительности и логи ошибок для своевременного выявления узких мест.
Архитектура Ceph и роль компонентов в хранении данных
Ceph построен на модульной архитектуре с несколькими типами компонентов, каждый из которых выполняет конкретные функции для распределённого хранения данных:
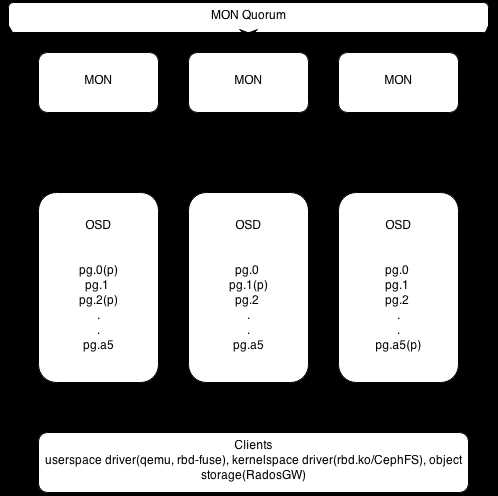
- Монитор (Ceph Monitor, MON) – следит за состоянием кластера, хранит карту кластера и обеспечивает согласованность данных между узлами.
- Объектные хранилища (Ceph OSD) – основной компонент, который хранит данные на дисках, выполняет репликацию и восстановление при сбоях.
- Менеджер (Ceph Manager, MGR) – собирает метрики производительности, управляет мониторингом и интеграцией с инструментами анализа.
- Метаданные (Ceph Metadata Server, MDS) – отвечает за управление файловой системой CephFS, хранит структуру каталогов и разрешения доступа.
Компоненты взаимодействуют по принципу распределённого контроля. Алгоритм CRUSH определяет, на какие OSD попадут конкретные объекты, минимизируя вероятность потери данных и устраняя необходимость централизованного распределителя. Это обеспечивает:
- Автоматическое распределение и балансировку нагрузки между узлами.
- Поддержку репликации и исправления ошибок без участия администратора.
- Мгновенное восстановление данных при выходе из строя отдельного узла.
При проектировании кластера важно правильно распределить MON, MGR и OSD по физическим серверам для повышения отказоустойчивости. Рекомендуется минимум три MON для поддержания кворума и не менее трёх OSD на узел для оптимального распределения объектов. MDS требуется только при использовании CephFS, а количество его экземпляров зависит от количества активных клиентов.
Принцип распределения данных в кластере Ceph
Ceph использует алгоритм CRUSH для распределения данных по узлам кластера без централизованного контроллера. Каждый объект получает уникальный идентификатор, на основе которого CRUSH определяет OSD, на которых будет храниться копия данных. Это обеспечивает автоматическое масштабирование и отказоустойчивость.
Объекты могут реплицироваться или кодироваться с исправлением ошибок (erasure coding) для снижения потерь данных при выходе из строя узлов. Репликация создаёт полные копии на нескольких OSD, а кодирование разбивает объект на фрагменты с избыточными данными, позволяя восстановить объект при повреждении части фрагментов.
CRUSH учитывает физическую топологию кластера, включая серверы, шкафы и дата-центры. Это позволяет распределять объекты так, чтобы копии не находились на одном узле или в одном стойке, снижая риск потери данных при локальном сбое.
Для планирования кластера рекомендуется:
- Определять уровень репликации в зависимости от числа OSD и требуемой надёжности.
- Размещать OSD равномерно по узлам и стойкам.
- Использовать кодирование с исправлением ошибок для больших объёмов архивных данных.
- Регулярно проверять карту CRUSH после добавления или удаления узлов, чтобы сохранить баланс распределения объектов.
Настройка хранилища объектов с помощью Ceph Object Storage

Ceph Object Storage (RADOS Gateway, RGW) предоставляет интерфейсы совместимые с S3 и Swift для хранения объектов. Настройка начинается с развёртывания OSD, MON и MGR, после чего создаётся пул объектов для размещения данных.
Для настройки RGW необходимо:
- Создать отдельный пул для хранения объектов и их метаданных.
- Настроить пользователей и ключи доступа для работы с S3 или Swift API.
- Конфигурировать политику репликации или кодирования с исправлением ошибок для обеспечения надёжности.
Рекомендуется использовать не менее трёх реплик для критически важных данных и проверять балансировку объектов по OSD с помощью команд rados df и radosgw-admin bucket stats. Для повышения производительности следует распределять RGW-инстансы по разным узлам и привязывать их к отдельным пулу OSD, чтобы избежать конкуренции за ресурсы.
Мониторинг хранилища объектов включает проверку состояния пулов, использование CRUSH-карты для контроля распределения и анализ логов RGW для выявления ошибок при доступе к объектам. Автоматизация с помощью Ceph Manager помогает отслеживать метрики загрузки и пропускной способности, позволяя своевременно увеличивать ресурсы кластера.
Использование Ceph Block Device для виртуальных машин
Ceph Block Device (RBD) позволяет создавать виртуальные диски для виртуальных машин с высокой надёжностью и масштабируемостью. Каждый RBD-образ хранится как объект в пуле Ceph, что обеспечивает автоматическое распределение данных и репликацию.
Для интеграции RBD с виртуальными машинами необходимо:
- Создать пул RBD с заданным уровнем репликации.
- Сформировать образ RBD нужного объёма и подключить его к гипервизору через librbd или iSCSI.
- Настроить доступ по ключам Ceph для конкретного пользователя или виртуальной машины.
Рекомендуется использовать минимум три реплики для повышения отказоустойчивости. Для крупных кластеров стоит разделять пулы RBD по типам нагрузки: один пул для баз данных, другой для файловых хранилищ виртуальных машин. Это снижает конкуренцию за ресурсы и упрощает управление производительностью.
Мониторинг включает проверку состояния пулов, отслеживание латентности операций чтения/записи и регулярное использование команды rbd status для контроля подключённых образов. При увеличении числа виртуальных машин или объёма данных следует масштабировать OSD и балансировать объекты по узлам с помощью CRUSH-карты.
Организация файловой системы CephFS для совместного доступа
CephFS предоставляет распределённую файловую систему поверх кластера Ceph, позволяя множеству клиентов работать с общими данными одновременно. Файловая система использует MDS для хранения метаданных, а сами файлы хранятся в пуле объектов Ceph.
Для настройки CephFS необходимо:
- Создать один или несколько пулов для хранения данных и метаданных.
- Развернуть MDS-демоны, обеспечивающие управление каталогами, разрешениями и блокировками.
- Подключить клиентов через kernel client или FUSE, указав адреса MON и имя файловой системы.
Рекомендуется минимум два MDS для обеспечения отказоустойчивости и распределения нагрузки при активном использовании каталогов. Для крупных каталогов с высокой активностью операций записи стоит включить дополнительный MDS для балансировки метаданных.
Мониторинг CephFS включает проверку состояния MDS, загрузки пулов и распределения объектов. Регулярное использование команд ceph fs status и ceph mds stat позволяет своевременно выявлять узкие места и предотвращать задержки при одновременном доступе множества клиентов.
Мониторинг состояния кластера и контроль за отказоустойчивостью

Мониторинг Ceph осуществляется через демоны MGR и инструменты командной строки, позволяя отслеживать состояние OSD, MON, MDS и пулов данных. Контроль за отказоустойчивостью включает проверку репликации, целостности объектов и своевременное восстановление после сбоев.
Основные параметры мониторинга:
| Компонент | Метрика | Цель |
|---|---|---|
| OSD | Статус, доступность, использование диска | Обнаружение перегруженных или недоступных дисков |
| MON | Состояние кворума, синхронизация карты кластера | Гарантия согласованности распределённых данных |
| MDS | Загрузка, состояние метаданных | Обеспечение стабильной работы CephFS при множественных клиентах |
| Пулы | Репликация, объём использования, состояние объектов | Контроль целостности и распределения данных |
Рекомендуется использовать команды ceph health, ceph osd tree и ceph df для регулярного контроля кластера. В случае выхода узлов из строя CRUSH автоматически перераспределяет объекты, а мониторинг позволяет вовремя оценить скорость восстановления. Для повышения отказоустойчивости стоит настроить алерты на превышение порогов использования дисков, задержки операций и потерю реплик объектов.
Методы масштабирования Ceph при росте нагрузки
Ceph масштабируется горизонтально путём добавления новых OSD, MON и MDS в кластер. Каждый новый OSD автоматически включается в CRUSH-карту, что позволяет перераспределять объекты без остановки сервиса. Для MON рекомендуется добавлять узлы по три, чтобы поддерживать кворум и согласованность данных.
При увеличении объёма данных или количества виртуальных машин стоит:
- Создавать дополнительные пулы для сегментации нагрузки между различными типами данных.
- Разворачивать дополнительные MDS при активной работе с CephFS для ускорения операций с метаданными.
- Настраивать многоканальные сети для разделения трафика репликации, клиента и администрирования.
CRUSH автоматически балансирует данные при добавлении новых OSD, но при больших кластерах рекомендуется пересчитывать карту и проверять распределение объектов с помощью ceph osd df tree. При использовании кодирования с исправлением ошибок увеличение числа фрагментов и контроль избыточности помогают ускорить восстановление после сбоев и поддерживать надёжность хранения.
Практические рекомендации по настройке резервного копирования и восстановления
Для обеспечения сохранности данных в Ceph необходимо реализовать стратегию резервного копирования и восстановления, учитывающую тип хранения: объекты, блоки или файловую систему.
Рекомендации по настройке:
- Создавать отдельные пулы для резервных копий, чтобы не смешивать с основными данными.
- Использовать репликацию или кодирование с исправлением ошибок для всех критически важных объектов.
- Планировать периодическое копирование RBD-образов с помощью rbd export и rbd import.
- Для CephFS выполнять резервное копирование метаданных MDS с помощью ceph mds failover и snapshot.
Процесс восстановления следует тестировать на отдельной среде:
- Восстановить объекты или образы из резервного пула и проверить целостность данных.
- Синхронизировать восстановленные данные с рабочим пулом с учётом изменений после создания резервной копии.
- Проверить корректность монтирования CephFS и доступ к файлам через клиентов.
Дополнительно рекомендуется настраивать алерты на сбои OSD и потери реплик, чтобы вовремя инициировать восстановление. Хранение резервных копий на отдельной физической инфраструктуре снижает риск одновременной потери данных из-за аппаратных сбоев или сетевых проблем.
Вопрос-ответ:
Какие основные компоненты входят в архитектуру Ceph и какую роль они выполняют?
Архитектура Ceph включает MON, OSD, MGR и MDS. MON контролирует состояние кластера и поддерживает карту кворума. OSD хранит объекты, выполняет репликацию и восстановление. MGR собирает метрики и управляет мониторингом. MDS отвечает за метаданные файловой системы CephFS, обеспечивая работу каталогов и разрешений доступа.
Как алгоритм CRUSH обеспечивает распределение данных в кластере Ceph?
CRUSH вычисляет, на каких OSD будут храниться объекты, исходя из идентификатора объекта и структуры кластера. Алгоритм учитывает физическое размещение серверов и стоек, что предотвращает сосредоточение копий на одном узле. Это позволяет балансировать нагрузку и автоматически восстанавливать данные при выходе OSD из строя.
В чем разница между Ceph Object Storage и Ceph Block Device?
Ceph Object Storage (RGW) предоставляет доступ к объектам через S3 или Swift API, подходит для больших архивов и веб-приложений. Ceph Block Device (RBD) создаёт виртуальные диски для виртуальных машин, поддерживает снапшоты и позволяет интегрировать с гипервизорами. Основное отличие — способ доступа к данным и применение: объекты против блочных устройств.
Какие шаги нужны для настройки резервного копирования и восстановления в Ceph?
Для RBD-образов используют команды rbd export и import, создают отдельные пулы для резервных копий и контролируют целостность данных. Для CephFS применяют snapshot и резервное копирование метаданных MDS. Рекомендуется тестировать восстановление на отдельной среде и хранить резервные копии на отдельной физической инфраструктуре, чтобы минимизировать риск потери информации.