Содержание статьи

Во многих языках программирования строки являются неизменяемыми: каждая операция объединения создаёт новый объект в памяти. При последовательной конкатенации из десяти фрагментов формируется не одна строка, а девять промежуточных экземпляров, которые сразу становятся мусором. В циклах это поведение масштабируется квадратично: при сборке строки длиной 10 000 символов через оператор + может быть создано десятки тысяч временных объектов.
Цена таких операций измеряется не только дополнительными байтами памяти, но и временем копирования данных. Каждый новый объект строки содержит полный дубликат предыдущего содержимого плюс добавляемый фрагмент. При росте строки это означает многократное копирование уже обработанных символов. В реальных нагрузках это приводит к заметным задержкам: профилирование часто показывает, что значительная доля процессорного времени уходит именно на операции работы со строками, а не на бизнес-логику.
Дополнительное давление испытывает и сборщик мусора. Короткоживущие строковые объекты быстро заполняют молодое поколение памяти, увеличивая частоту сборок. Даже если каждая отдельная операция выглядит безобидно, их накопление в горячих участках кода может привести к скачкам времени отклика и нестабильному поведению приложения под нагрузкой.
Практическая рекомендация проста: когда итоговая строка формируется по частям, заранее неизвестна по длине или собирается в цикле, следует использовать специализированные механизмы накопления символов, а не повторные операции объединения. Такой подход снижает количество аллокаций, уменьшает объём копируемых данных и делает поведение программы более предсказуемым при росте входных данных.
Как неизменяемость строк приводит к созданию лишних объектов в памяти
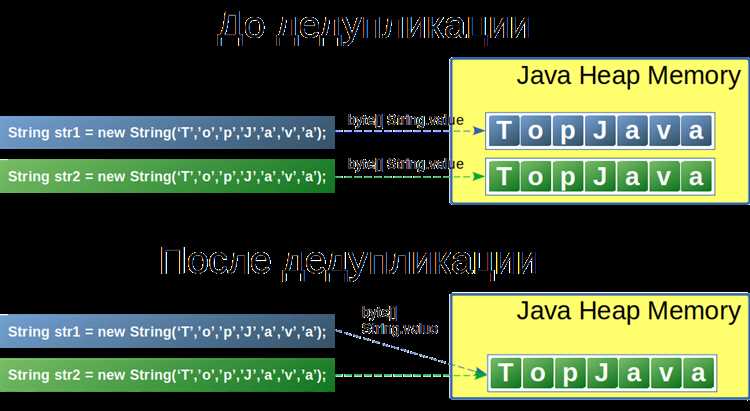
Неизменяемость строк означает, что после создания объект строки не может быть изменён. Любая операция объединения, даже добавление одного символа, приводит к созданию нового объекта в памяти. Исходная строка при этом остаётся без изменений и ожидает удаления сборщиком мусора. При конкатенации трёх фрагментов последовательно создаются как минимум два временных объекта, которые не используются дальше.
Каждый такой объект содержит собственный массив символов. При объединении строк длиной 1 000 и 1 000 символов создаётся новый массив на 2 000 символов с полным копированием данных из обоих источников. Если подобная операция выполняется в цикле, размер копируемых данных растёт с каждой итерацией, а количество выделяемой памяти увеличивается непропорционально итоговой длине строки.
Проблема особенно заметна при сборке строк из динамических источников: логов, SQL-запросов, JSON или HTML. Например, формирование текста из 5 000 небольших фрагментов через конкатенацию создаёт тысячи короткоживущих объектов, которые быстро заполняют область памяти для временных данных. Это повышает нагрузку на аллокатор и усложняет работу управления памятью.
Рекомендация сводится к контролю жизненного цикла строк. Если результат формируется пошагово, следует использовать структуры, которые накапливают символы в одном буфере без пересоздания объектов. Это позволяет сократить количество временных строк, уменьшить объём копирования данных и сохранить предсказуемое потребление памяти при росте входных данных.
Почему последовательные операции «+» увеличивают время выполнения
При каждой операции объединения через + система обязана создать новый объект строки, даже если добавляется небольшой фрагмент. Время выполнения напрямую зависит от текущей длины результата: чем длиннее строка, тем больше символов требуется скопировать. В сценариях, где строка наращивается постепенно, стоимость одной операции растёт на каждом шаге.
Последовательные конкатенации формируют не линейную, а нарастающую нагрузку. Например, при добавлении 1 000 фрагментов длиной по 10 символов итоговая строка содержит 10 000 символов, но суммарно копируется около 5 миллионов символов. Эти дополнительные операции не видны на уровне кода, но легко обнаруживаются при анализе времени выполнения.
Дополнительные задержки возникают из-за частых обращений к менеджеру памяти. Каждая операция + инициирует выделение нового блока, что увеличивает количество проверок доступного пространства и синхронизаций внутри среды выполнения. В многонагруженных приложениях это становится заметным фактором деградации отклика.
Чтобы сократить время выполнения, рекомендуется избегать цепочек операций + при динамическом формировании строк. Когда известен примерный объём данных или используется цикл, целесообразно применять подходы, позволяющие добавлять фрагменты без повторного копирования всего содержимого. Это снижает суммарное количество операций и делает скорость работы менее зависимой от размера результата.
Что происходит с аллокациями памяти при конкатенации в циклах
При конкатенации строк внутри цикла каждая итерация запускает новую аллокацию памяти под результирующую строку. Даже если добавляется небольшой фрагмент, система выделяет блок, достаточный для хранения всего накопленного содержимого. Предыдущий объект строки при этом становится временным и больше не используется.
Количество аллокаций напрямую зависит от числа итераций. Цикл из 10 000 шагов создаёт не одну строку, а 10 000 отдельных объектов, каждый со своим массивом символов. По мере роста результата увеличивается и размер выделяемых блоков, что приводит к фрагментации памяти и росту накладных расходов на управление ей.
Такая модель особенно чувствительна в горячих участках кода. Частые аллокации заполняют области памяти для краткоживущих объектов, ускоряя их исчерпание. Это вынуждает среду выполнения чаще запускать процессы очистки, даже если итоговый объём данных остаётся умеренным.
Практическая рекомендация заключается в отказе от прямой конкатенации в циклах. Если строка собирается по частям, следует использовать подходы с предварительным резервированием или накоплением данных в одном буфере. Это снижает количество операций выделения памяти и делает поведение приложения более стабильным при росте числа итераций.
Как множественные конкатенации влияют на работу сборщика мусора

Каждая операция объединения строк создаёт новый объект, а предыдущий почти сразу становится недостижимым. При множественных конкатенациях формируется поток короткоживущих строк, который быстро заполняет область памяти, предназначенную для временных объектов. Сборщик мусора вынужден реагировать чаще, даже если итоговый результат занимает сравнительно небольшой объём.
При интенсивной генерации строк молодое поколение памяти заполняется за считанные миллисекунды. Это приводит к увеличению числа циклов очистки, во время которых приостанавливается выполнение пользовательского кода. В системах с жёсткими требованиями к задержкам такие паузы могут стать источником нестабильного времени отклика.
Часть строк может переживать несколько циклов очистки и продвигаться в более долгоживущие области памяти. Там стоимость их удаления возрастает, поскольку проверяется больший объём объектов. В результате даже временные операции со строками начинают влиять на общую пропускную способность приложения.
Чтобы снизить нагрузку на сборщик мусора, рекомендуется ограничивать создание временных строк. Использование механизмов накопления символов в одном объекте позволяет уменьшить количество краткоживущих аллокаций и сократить число пауз очистки. Такой подход делает поведение приложения более предсказуемым при увеличении объёма обрабатываемых данных.
Почему конкатенация строк в цикле отличается от одиночной операции

Одиночная операция объединения создаёт один новый объект строки и копирует символы один раз. В цикле каждая итерация формирует новый объект, копируя весь накопленный результат вместе с добавляемым фрагментом. При n итерациях суммарное количество копирований растёт примерно как n²/2 символов, что резко увеличивает время выполнения и нагрузку на память.
В цикле временные объекты накапливаются очень быстро. Даже если отдельные строки малы, их суммарный объём может превышать размер итоговой строки в несколько раз. Сборщик мусора получает больше объектов для очистки, что повышает частоту пауз и нагрузку на систему.
В отличие от одиночной конкатенации, циклическое наращивание строк не может быть эффективно оптимизировано компилятором или виртуальной машиной без явного использования накопителя символов. Поэтому разница между единичной операцией и многократной конкатенацией проявляется не только в памяти, но и в стабильности времени выполнения.
Рекомендация: при формировании строки в цикле использовать StringBuilder, StringBuffer или аналогичные структуры с внутренним буфером, который расширяется по мере необходимости. Это минимизирует количество копирований и аллокаций, делая работу с большим количеством фрагментов предсказуемой.
В каких случаях StringBuilder и аналоги решают проблему
Использование StringBuilder или аналогичных структур эффективно в сценариях, где строка формируется по частям или в цикле. Они позволяют накапливать символы в едином буфере, избегая создания множества временных объектов и повторного копирования данных.
- Циклы с динамическим добавлением строк: при добавлении тысяч фрагментов структура расширяет внутренний массив по мере необходимости, вместо выделения нового объекта на каждой итерации.
- Формирование больших текстовых документов или логов: StringBuilder позволяет предварительно задать размер буфера, уменьшая количество перераспределений памяти.
- Сборка SQL-запросов, HTML, JSON или других текстовых форматов из множества частей: использование буфера сокращает накладные расходы на аллокации и улучшает производительность.
- Обработка входных данных с неизвестной длиной: структуры с внутренним буфером гарантируют, что добавление символов остаётся линейным по времени, даже при значительном росте объёма данных.
Рекомендации по применению:
- При предварительно известном объёме данных задавать размер буфера для минимизации перераспределений.
- Использовать методы append вместо операций «+» в цикле или при пошаговом формировании строки.
- В многопоточных сценариях применять потокобезопасные аналоги (StringBuffer) или управлять синхронизацией вручную.
Использование этих структур позволяет сократить количество временных объектов, уменьшить нагрузку на сборщик мусора и обеспечить предсказуемое время выполнения при работе с большими или динамически формируемыми строками.
Как конкатенации строк ухудшают читаемость и поддержку кода
Частые операции объединения строк с помощью + приводят к длинным и трудночитаемым выражениям. Когда строка формируется из нескольких переменных, литералов и методов в одной строке кода, становится сложно отследить порядок фрагментов и структуру результата.
Многоступенчатые конкатенации усложняют поддержку кода. Любое изменение формата строки требует проверки всех мест объединения, иначе легко внести ошибку или нарушить ожидаемую последовательность символов. Это особенно критично при формировании SQL-запросов, HTML или логов, где ошибка в одной конкатенации может привести к сбою всей операции.
Наличие множества временных строк в коде затрудняет отладку и профилирование. Инструменты для анализа памяти показывают большое количество короткоживущих объектов, что маскирует реальные узкие места и отвлекает от поиска источника проблем с производительностью.
Для улучшения читаемости и поддержки рекомендуется использовать структуры накопления строк или разбивать формирование текста на логические блоки. Методы вроде append в StringBuilder или шаблоны форматирования позволяют явно видеть структуру итоговой строки, упрощают модификацию и уменьшают риск ошибок при внесении изменений.
Какие ошибки профилирования скрывают проблемы со строками

При анализе производительности строк часто упускаются нюансы, связанные с множественными конкатенациями. На первый взгляд приложение может работать быстро, но скрытые накладные расходы на создание временных объектов остаются незамеченными.
- Использование поверхностных метрик CPU: суммарное время выполнения отдельных методов не отражает затраты на копирование символов и аллокации памяти внутри цикла конкатенаций.
- Игнорирование краткоживущих объектов в профилировщике: временные строки создаются и уничтожаются очень быстро, что затрудняет их идентификацию как источника проблем.
- Сосредоточение на крупных структурах данных: профилировщики часто выделяют внимание массивам или коллекциям, маскируя множественные мелкие аллокации, которые накапливаются и замедляют выполнение.
- Пренебрежение анализом GC-паузы: частые конкатенации увеличивают нагрузку на сборщик мусора, но короткие паузы могут не попадать в стандартные отчёты, создавая иллюзию нормальной работы.
Чтобы выявить скрытые проблемы со строками, рекомендуется:
- Использовать профилировщики, способные отслеживать количество и длительность аллокаций временных объектов.
- Анализировать горячие участки кода с множественными конкатенациями, особенно в циклах и при динамическом формировании текста.
- Сравнивать производительность с альтернативными подходами, например, с использованием StringBuilder или буферов символов, чтобы оценить реальный эффект оптимизации.
- Следить за частотой запуска сборщика мусора и временем пауз, чтобы понять влияние краткоживущих строк на отклик приложения.
Только комплексный подход к профилированию позволяет обнаружить и исправить скрытые узкие места, связанные с множественными конкатенациями строк, и улучшить производительность и предсказуемость работы приложения.
Вопрос-ответ:
Почему использование оператора «+» для соединения строк в цикле так медленно?
Оператор «+» создаёт новый объект строки при каждом объединении. В цикле это приводит к множеству промежуточных объектов, каждый из которых копирует все предыдущие символы. Чем больше итераций и длина строки, тем больше копирований и выделений памяти происходит, что заметно замедляет выполнение кода и увеличивает нагрузку на сборщик мусора.
Какая разница между одиночной конкатенацией и множественными объединениями в цикле?
Одиночная конкатенация создаёт один новый объект и копирует символы один раз. В цикле каждая итерация формирует новый объект, повторно копируя всё накопленное содержимое. Это означает, что при нескольких тысячах итераций количество операций копирования возрастает значительно, что замедляет выполнение и увеличивает потребление памяти по сравнению с одиночной операцией.
В каких ситуациях имеет смысл использовать StringBuilder или аналогичные структуры?
StringBuilder и аналогичные структуры полезны при формировании строк в циклах или из множества отдельных фрагментов, когда итоговый размер заранее неизвестен. Они накапливают символы в одном буфере, уменьшая количество временных объектов и копирований. Это ускоряет работу программы и снижает нагрузку на сборщик мусора. Кроме того, такие структуры делают код более читаемым, особенно при построении больших текстовых документов или сложных запросов.
Как множественные конкатенации влияют на сборщик мусора?
Каждая операция объединения создаёт временный объект, который быстро становится недостижимым. При большом числе конкатенаций таких объектов накапливается много, что увеличивает частоту срабатывания сборщика мусора. Это приводит к дополнительным паузам и нагрузке на систему, особенно при обработке больших массивов данных, где временные строки создаются в больших количествах.