Содержание статьи

Строки в Java часто содержат числовые данные в неструктурированном виде: идентификаторы, суммы, версии, показания датчиков, параметры из логов или пользовательского ввода. Для корректной обработки таких данных требуется точно выделять числовые фрагменты, учитывая формат записи, возможные разделители и знаки. Ошибки на этом этапе приводят к некорректным вычислениям, сбоям парсинга и трудноотлавливаемым багам.
Java предоставляет несколько инструментов для извлечения чисел из текста: классы Pattern и Matcher, методы работы с символами, а также стандартные парсеры числовых типов. Выбор подхода зависит от структуры строки, количества чисел и требований к контролю формата. Например, обработка строки «order_145_total=89.50USD» требует иного подхода, чем разбор CSV-подобных данных или логов с переменной разметкой.
Особое внимание стоит уделять работе с отрицательными значениями, десятичными разделителями и переполнению числовых типов. При извлечении чисел важно не только найти подходящую подстроку, но и корректно преобразовать её в int, long, double или BigDecimal с учетом возможных исключений. Грамотно выстроенный процесс парсинга снижает риск ошибок и упрощает последующую обработку данных.
Поиск целых чисел в строке с помощью регулярных выражений
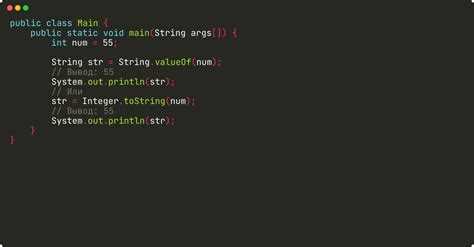
Для извлечения целых чисел в Java чаще всего используется связка классов Pattern и Matcher. Базовое регулярное выражение \d+ позволяет находить последовательности цифр в любом тексте, включая строки с буквами, символами и пробелами. Такой подход подходит для ситуаций, когда числа не имеют знака и разделены произвольными символами.
Если требуется учитывать отрицательные значения, шаблон дополняется необязательным знаком минус: -?\d+. Это выражение корректно извлекает числа из строк вида «temp=-12 error=3». Для исключения ложных совпадений внутри слов рекомендуется использовать границы: \b-?\d+\b, что предотвращает захват чисел, встроенных в идентификаторы.
На практике поиск выполняется через цикл вызовов matcher.find(), позволяющий получить все совпадения без предварительного разбиения строки. Полученное значение извлекается методом matcher.group() и далее преобразуется в числовой тип. Такой подход подходит для обработки логов, параметров URL и строк с неопределённым количеством чисел.
Регулярные выражения чувствительны к формату входных данных. При наличии чисел с ведущими нулями, разделителями или смешанных форматов необходимо заранее определить допустимый шаблон. Жёстко заданное выражение снижает риск извлечения некорректных значений и упрощает последующую обработку результата.
Извлечение дробных чисел и чисел с плавающей точкой
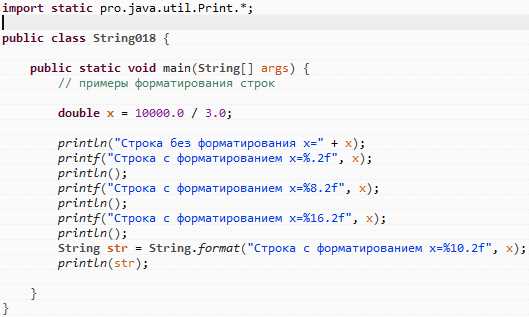
Дробные значения в строках чаще всего представлены в виде чисел с десятичной точкой, поэтому для их поиска используется расширенный шаблон регулярного выражения. На практике применяется выражение -?\d+\.\d+, позволяющее извлекать значения вроде 12.75 или -0.34 из произвольного текста. Такой шаблон не захватывает целые числа и подходит для сценариев, где ожидается строго дробный формат.
Если входные данные допускают как целые, так и дробные значения, используется комбинированный вариант -?\d+(?:\.\d+)?. Он находит числа без дробной части и с ней, не создавая отдельных совпадений. Для предотвращения захвата фрагментов версий или IP-адресов рекомендуется ограничивать шаблон границами слова или анализировать контекст строки.
После извлечения строкового представления число преобразуется в double, float или BigDecimal. Для финансовых расчётов предпочтителен BigDecimal, так как он исключает накопление ошибок округления, характерных для чисел с плавающей точкой. Создание объекта через конструктор с String сохраняет исходную точность значения.
Отдельного внимания требуют данные с альтернативным десятичным разделителем. Если в строке используется запятая, необходимо либо предварительно заменить её на точку, либо применять более сложный шаблон с условной обработкой. Явное описание допустимого формата упрощает контроль входных данных и снижает вероятность некорректного парсинга.
Получение чисел из строки без использования regex
Отказ от регулярных выражений оправдан в случаях, когда формат строки предсказуем или требуется полный контроль над процессом разбора. Наиболее прямой подход – последовательный обход символов строки с проверкой через Character.isDigit(). Такой метод позволяет собирать числовые фрагменты вручную, фиксируя начало и конец каждого значения.
При посимвольном анализе удобно использовать StringBuilder для накопления цифр. Когда встречается нечисловой символ, накопленная последовательность преобразуется в число и очищается. Этот способ подходит для извлечения нескольких значений из одной строки и легко расширяется поддержкой знака минус или разделителей.
Если структура строки известна заранее, рационально применять методы split() и indexOf(). Например, при разборе параметров формата key=value можно выделить подстроку после символа = и сразу передать её в Integer.parseInt() или Long.parseLong(). Такой подход снижает вероятность захвата лишних данных.
Для повышения надёжности важно обрабатывать исключения NumberFormatException и проверять диапазон значений до преобразования. Явный контроль логики разбора упрощает отладку и делает код предсказуемым при работе с нестандартными или частично повреждёнными строками.
Обработка отрицательных чисел и знаков плюс/минус
При извлечении чисел из строки важно корректно учитывать символы + и —, так как они напрямую влияют на итоговое значение. В текстовых данных знак может располагаться вплотную к числу или быть отделён пробелом, что необходимо учитывать при анализе строки. Игнорирование этого фактора приводит к потере знака и искажению результата.
При использовании регулярных выражений знак задаётся как необязательная часть шаблона: [+-]?\d+ для целых значений или [+-]?\d+(?:\.\d+)? для дробных. Такой подход позволяет корректно извлекать значения из строк вида «+15», «-8» или «balance -42.7», не захватывая лишние символы.
В случае посимвольного разбора знак следует обрабатывать как отдельное состояние. При обнаружении — или + перед цифрой необходимо сохранить его и применить к числу после завершения накопления цифр. Важно проверять, что знак действительно относится к числу, а не используется как математический оператор или разделитель.
После извлечения строкового представления знак автоматически учитывается при вызове Integer.parseInt, Long.parseLong или при создании BigDecimal. Дополнительная валидация позволяет отсеять случаи с повторяющимися знаками или некорректным расположением символов, что повышает надёжность обработки входных данных.
Преобразование найденных подстрок в числовые типы Java
После извлечения числовых фрагментов из строки следующий шаг – приведение их к подходящему типу данных. Для целых значений применяются методы Integer.parseInt и Long.parseLong, которые принимают строку и возвращают примитивное значение. Выбор между ними определяется ожидаемым диапазоном чисел, так как выход за пределы типа приводит к исключению.
Для работы с дробными значениями используются Double.parseDouble и Float.parseFloat. Эти методы корректно обрабатывают стандартную запись с точкой, но подвержены погрешностям представления. При необходимости точного соответствия входному значению, например при обработке денежных сумм, следует использовать BigDecimal и создавать объект из строки, а не из примитива.
Любое преобразование строки в число может завершиться NumberFormatException. Чтобы избежать сбоев, рекомендуется предварительно проверять формат подстроки или оборачивать парсинг в блок try-catch. Это особенно важно при обработке пользовательского ввода и данных из внешних источников.
Дополнительно стоит учитывать локальные особенности формата чисел. Если входная строка содержит нестандартные разделители или пробелы, их необходимо удалить или нормализовать до передачи в метод преобразования. Явная подготовка строки снижает вероятность ошибок и упрощает контроль корректности результата.
Разбор строк с числами в пользовательских форматах
Пользовательские форматы часто выходят за рамки стандартных числовых представлений и включают суффиксы, префиксы, единицы измерения и нестандартные разделители. Примеры таких строк – «12kg», «USD 1_250», «v2-build45». Для корректного разбора необходимо заранее определить допустимую структуру данных и исключить неоднозначные элементы.
При обработке подобных строк удобно комбинировать несколько приёмов:
- удаление известных префиксов и суффиксов с помощью replace или substring
- нормализация разделителей, включая замену подчёркиваний и пробелов
- выделение числовых блоков по позициям, а не по шаблону
Если формат допускает несколько чисел в одной строке, полезно применять пошаговый разбор с сохранением контекста. Например, в строке «item3x20» первое число может обозначать количество, а второе – размер. Жёсткая привязка к позиции символов снижает риск перепутать значения.
Для сложных форматов с изменяемыми правилами разумно выносить логику разбора в отдельный метод или класс. Такой подход упрощает поддержку и позволяет централизованно контролировать допустимые варианты записи чисел.
Вопрос-ответ:
Как извлечь несколько чисел из строки, если их количество заранее неизвестно?
В такой ситуации применяется итеративный поиск. Чаще всего используют Matcher с циклом find(), который возвращает каждое совпадение по очереди. Альтернатива — посимвольный разбор строки с накоплением цифр и фиксацией границ числа при встрече нецифровых символов. Оба подхода позволяют получить список значений без знания их количества заранее.
Почему Double.parseDouble может вернуть неточное значение после извлечения числа?
Тип double хранит данные в двоичном формате, из-за чего некоторые десятичные дроби не представимы точно. После парсинга значения вроде 0.1 могут содержать погрешность. Если требуется точное совпадение с текстовым представлением, следует использовать BigDecimal и создавать объект напрямую из строки.
Как избежать захвата чисел, которые являются частью идентификаторов?
Для этого используется контекстный контроль. При работе с регулярными выражениями применяются границы слова или явные разделители. При ручном разборе проверяется окружение цифр: если рядом находятся буквы без разделителей, такое совпадение можно пропустить или обработать отдельно.
Что делать, если в строке используются разные десятичные разделители?
Перед парсингом строку приводят к единому формату. Чаще всего запятую заменяют на точку, а пробелы удаляют. После нормализации значение можно безопасно передать в стандартные методы преобразования чисел.
Есть ли смысл отказываться от регулярных выражений при разборе чисел?
Да, если формат строки известен и стабилен. Посимвольный анализ даёт полный контроль над логикой и упрощает отладку. Такой подход удобен при работе с пользовательскими форматами, где правила извлечения чисел жёстко привязаны к позиции символов.