Содержание статьи

Определение размера файла – базовая задача при работе с загрузками, резервным копированием, обработкой данных и ограничениями ресурсов. В Python эта операция решается стандартными средствами, без сторонних библиотек, и занимает одну–две строки кода. При этом важно понимать, в каком контексте выполняется проверка: локальный файл, путь пользователя, директория или потенциально недоступный ресурс.
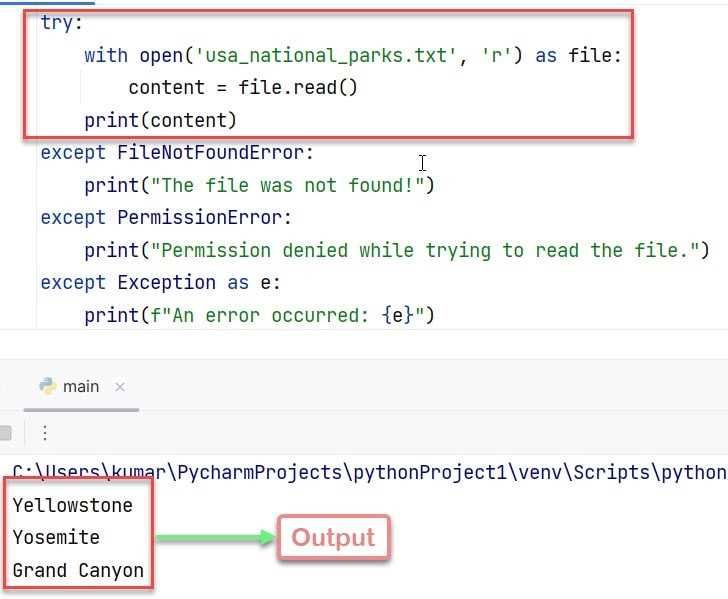
Отдельного внимания требует обработка исключений. Проверка размера файла может завершиться ошибкой из-за отсутствия файла, прав доступа или некорректного пути. Игнорирование этих случаев приводит к падению скриптов в рантайме. В статье рассматриваются практические способы получения размера файла с учётом таких сценариев.
Материал ориентирован на разработчиков, которые работают с файловой системой напрямую и хотят использовать стандартную библиотеку Python без лишних абстракций. Все подходы применимы как в небольших скриптах, так и в серверных приложениях.
Получение размера файла по пути с помощью os.path.getsize

Функция os.path.getsize() предназначена для получения размера конкретного файла по его пути и возвращает значение в байтах. Она работает с абсолютными и относительными путями и не требует предварительного открытия файла. Это делает её удобной для проверок перед чтением, копированием или отправкой данных.
Для использования функции необходимо передать строковый путь к файлу. Если файл существует и доступен, результатом будет целое число, отражающее фактический размер на диске. Например, файл размером 2,5 МБ вернёт значение 2621440, что важно учитывать при сравнении с лимитами или квотами.
Функция не проверяет тип объекта по пути. Если указать путь к директории, результат будет зависеть от файловой системы и не отражает суммарный размер содержимого каталога. Поэтому перед вызовом рекомендуется дополнительно проверять, что путь указывает именно на файл.
При отсутствии файла или недостатке прав доступа os.path.getsize() выбрасывает исключение OSError. Для стабильной работы скрипта получение размера следует оборачивать в обработку ошибок, особенно при работе с пользовательскими путями или временными файлами.
Модуль os.path входит в стандартную библиотеку Python и поддерживается на всех основных платформах. Это делает getsize надёжным выбором для кросс-платформенных сценариев, где требуется быстро определить объём файла без дополнительной нагрузки на память.
Определение размера файла через объект Path из pathlib
Модуль pathlib предоставляет объектно-ориентированный способ работы с файловой системой. Для получения размера файла используется объект Path и его атрибут stat(), который возвращает метаданные файла, включая размер в байтах.
После создания объекта Path по нужному пути размер файла доступен через поле st_size. Это целое число, соответствующее фактическому объёму файла на диске. Значение подходит для прямых сравнений, расчёта лимитов и логирования без дополнительных преобразований.
Метод stat() выполняет системный вызов и требует существования файла. Если путь указывает на несуществующий объект или файл недоступен, будет выброшено исключение FileNotFoundError или PermissionError. При работе с внешними путями такие ситуации необходимо учитывать заранее.
Объект Path позволяет выполнять предварительные проверки через методы exists() и is_file(). Это снижает риск получения некорректных данных, например при передаче пути к директории или символьной ссылке.
Использование pathlib особенно удобно в проектах, где активно применяются пути, объединение каталогов и проверка файлов. Получение размера через Path хорошо вписывается в единый стиль работы с файловой системой и повышает читаемость кода.
Проверка размера файла перед обработкой или загрузкой
На практике размер файла сравнивают с заранее заданным порогом в байтах. Например, при ограничении в 10 МБ используется значение 10485760. Сравнение выполняется напрямую, без округлений, чтобы исключить пограничные ошибки при проверке условий.
Перед загрузкой файла на сервер проверка размера позволяет сразу отклонить неподходящий объект и вернуть контролируемый ответ. Это снижает нагрузку на сеть и защищает обработчики от получения данных, которые не могут быть сохранены или обработаны.
При обработке локальных файлов проверка размера помогает выбрать сценарий работы: потоковое чтение, разбиение на части или полный отказ от операции. Такой подход особенно актуален для архивов, логов и медиафайлов.
Проверку размера следует выполнять совместно с контролем существования файла и прав доступа. Это исключает ситуации, когда скрипт пытается сравнивать значение, полученное для несуществующего или недоступного объекта.
Получение размера файла в байтах, килобайтах и мегабайтах
Все стандартные способы определения размера файла в Python возвращают значение в байтах. Это базовая единица, удобная для вычислений и проверок условий, но плохо читаемая для человека. Поэтому на практике почти всегда требуется преобразование в килобайты или мегабайты.
Преобразование выполняется арифметически, без обращения к файловой системе. Используются двоичные единицы измерения, где:
- 1 килобайт равен 1024 байтам
- 1 мегабайт равен 1024 × 1024 байтам
После получения размера в байтах значение можно делить на соответствующий коэффициент. Для логов и интерфейсов часто применяют округление до одного или двух знаков после запятой, чтобы избежать перегруженных чисел.
При сравнении с лимитами преобразование выполнять не требуется. Корректнее хранить пороговые значения сразу в байтах, чтобы исключить ошибки из-за округления и неточных дробных значений.
Типовой подход к работе с разными единицами включает:
- хранение исходного размера в байтах
- использование целых чисел для проверок условий
Такой порядок позволяет сохранять точность расчётов и при этом отображать данные в удобном для восприятия виде.
Определение размера файла с обработкой ошибок доступа
При работе с файловой системой получение размера файла часто сопровождается ошибками, связанными не с логикой программы, а с внешними условиями. Python выбрасывает исключения на этапе обращения к метаданным файла, поэтому попытка получить размер без защиты приводит к аварийному завершению скрипта.
Основные проблемы возникают при обращении к несуществующим путям, файлам без прав чтения или объектам, к которым доступ ограничен операционной системой. Эти ситуации необходимо учитывать заранее, особенно при работе с пользовательским вводом, временными каталогами и сетевыми ресурсами.
На практике обработка ошибок строится вокруг перехвата конкретных исключений, а не общего блока. Это позволяет точно определить причину сбоя и принять корректное решение: пропустить файл, зафиксировать ошибку или уведомить пользователя.
| Исключение | Причина возникновения | Типовая реакция |
|---|---|---|
| FileNotFoundError | Файл отсутствует по указанному пути | Проверка пути или пропуск обработки |
| PermissionError | Недостаточно прав доступа к файлу | Логирование и отказ от операции |
| OSError | Системная ошибка файловой системы | Обработка по общему сценарию |
Перед получением размера файла допустимо выполнять предварительные проверки существования и типа объекта, однако они не гарантируют отсутствие ошибок доступа. Финальная защита всегда должна быть реализована на уровне обработки исключений.
Такой подход позволяет безопасно получать размер файла в автоматических скриптах, фоновых задачах и серверных приложениях, не прерывая выполнение программы из-за единичных проблем с доступом.
Получение размера файлов в директории с помощью Python
Определение размера файлов внутри директории требуется при анализе занимаемого места, очистке хранилищ и подготовке отчётов. В Python эта задача решается путём обхода содержимого каталога и получения размера каждого файла отдельно, так как файловая система не предоставляет агрегированное значение для директории.
При обходе каталога важно учитывать, что в нём могут находиться подкаталоги, символьные ссылки и служебные объекты. Размер имеет смысл получать только для файлов, предварительно отфильтровывая остальные элементы. Это предотвращает искажение данных и ошибки при обращении к метаданным.
Для крупных директорий рекомендуется использовать пошаговый обход, а не загрузку всего списка файлов в память. Такой подход позволяет обрабатывать тысячи объектов без резкого роста потребления ресурсов и применять ограничения по размеру на раннем этапе.
При подсчёте суммарного объёма директории размеры файлов складываются в байтах. Преобразование в другие единицы выполняется после завершения расчёта, чтобы сохранить точность итогового значения.
В рабочих сценариях обход директории следует сочетать с обработкой ошибок доступа. Отдельные файлы могут быть недоступны или удалены в процессе выполнения скрипта, поэтому пропуск проблемных элементов позволяет получить результат без прерывания работы программы.
Вопрос-ответ:
Почему размер файла в Python всегда возвращается в байтах?
Операционная система хранит информацию о файлах в байтах, и Python передаёт это значение без преобразований. Такой формат удобен для точных сравнений, расчёта лимитов и арифметических операций. Перевод в килобайты или мегабайты выполняется уже на уровне приложения, если требуется вывод для пользователя.
Можно ли узнать размер файла, не открывая его?
Да, стандартные функции Python получают размер из метаданных файловой системы. Файл при этом не читается и не загружается в память. Это позволяет проверять объём больших объектов перед копированием, обработкой или отправкой по сети.
Чем отличается получение размера через os.path и pathlib?
Оба способа используют системные данные и возвращают одинаковый результат. Разница заключается в стиле работы с путями. os.path опирается на строки, а pathlib предоставляет объект Path с методами проверки существования, типа файла и доступа к метаданным, что делает код более структурированным.
Что произойдёт, если попытаться получить размер файла без прав доступа?
Python выбросит исключение, связанное с доступом к файловой системе. Без обработки такой ситуации выполнение программы будет прервано. В практических сценариях размер файла запрашивают внутри блока обработки ошибок, чтобы корректно реагировать на отказ в доступе.
Как узнать общий размер всех файлов в папке?
Размер каталога вычисляется путём обхода его содержимого и сложения размеров отдельных файлов. Подкаталоги обрабатываются отдельно, если требуется рекурсивный подсчёт. Значение собирается в байтах, а перевод в другие единицы выполняется после завершения расчёта.
Почему размер файла может отличаться от значения, показанного в проводнике?
Python возвращает фактический размер файла в байтах, записанный в метаданных файловой системы. Проводник часто округляет значения, использует другие единицы измерения или отображает размер с учётом особенностей отображения. Из-за этого одно и то же значение может выглядеть по-разному, хотя реальный объём данных не меняется.
Как корректно сравнивать размер файла с лимитом, заданным в мегабайтах?
Для сравнения удобнее перевести лимит в байты и работать с целыми числами. Например, ограничение в 5 МБ соответствует 5242880 байтам. Такой подход исключает ошибки округления и позволяет точно определить, превышает ли файл допустимый объём.