Содержание статьи

При работе с текстовыми файлами в Python ошибка кодировки чаще всего проявляется в виде UnicodeDecodeError или искажённых символов. Причина почти всегда одна – реальная кодировка файла не совпадает с той, которую ожидает интерпретатор. Это особенно характерно для данных, полученных из внешних источников: CSV из бухгалтерских систем, логи серверов, выгрузки из старых баз данных или файлы, созданные в разных операционных системах.
Python по умолчанию опирается на UTF-8, но на практике файлы могут быть сохранены в Windows-1251, KOI8-R, ISO-8859-5 и других кодировках. Попытка открыть такой файл без предварительного анализа приводит к ошибкам уже на этапе чтения. Поэтому перед обработкой текста важно получить максимально точную информацию о кодировке, опираясь не на догадки, а на фактические данные.
В экосистеме Python для этого используются два подхода: анализ байтового содержимого файла и проверка гипотез через декодирование. Библиотеки chardet и charset-normalizer позволяют оценить вероятную кодировку на основе статистики символов, а ручная проверка через open() помогает убедиться в корректности результата. Дополнительную роль играет наличие BOM, который можно определить без сторонних инструментов.
В статье рассматриваются практические способы определения кодировки файла в Python: от чтения первых байтов и работы с внешними библиотеками до обработки ошибок при неверном распознавании. Все методы ориентированы на реальные сценарии обработки данных и могут быть встроены в рабочий код без сложной настройки.
Чтение байтов файла для анализа кодировки

Определение кодировки начинается с анализа бинарного содержимого файла, поскольку текстовая интерпретация на этом этапе может привести к ошибкам. Файл необходимо открывать строго в бинарном режиме, чтобы получить доступ к исходным байтам без попыток автоматического декодирования со стороны Python.
Первые несколько байтов часто содержат сигнатуры, указывающие на конкретную кодировку. Например, последовательность 0xEF 0xBB 0xBF однозначно указывает на UTF-8 с BOM, 0xFF 0xFE – на UTF-16 LE, а 0xFE 0xFF – на UTF-16 BE. Если такие маркеры присутствуют, дополнительный анализ не требуется, так как кодировка определяется напрямую.
При отсутствии BOM анализ продолжается за счёт изучения распределения байтов. Частые значения выше 0x7F указывают на многобайтовые кодировки или однобайтовые национальные таблицы. Например, регулярное появление байтов в диапазоне 0xC0–0xFF характерно для кириллических кодировок вроде Windows-1251, тогда как строго структурированные последовательности байтов могут говорить о UTF-8.
Для практического анализа достаточно считать первые 4–8 КБ файла. Этого объёма хватает, чтобы выявить закономерности без лишней нагрузки на память. Такой подход особенно полезен при обработке больших файлов, где полное чтение нецелесообразно.
Чтение байтов также позволяет заранее выявить повреждённые файлы: случайное распределение значений или наличие нулевых байтов внутри текстового потока часто свидетельствуют о бинарном формате или ошибочной передаче данных. В таких случаях попытка определить кодировку текстовыми методами будет заведомо некорректной.
Определение кодировки с помощью библиотеки chardet
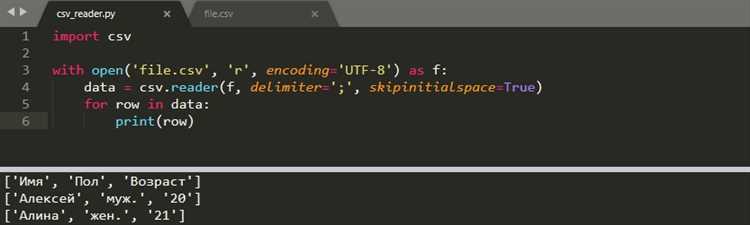
Для получения корректного результата важно передавать в анализ именно бинарные данные, считанные из файла. На практике достаточно первых нескольких килобайт текста, но для коротких файлов лучше анализировать всё содержимое. Низкий объём данных напрямую снижает точность распознавания, особенно для кодировок с похожими распределениями символов.
Возвращаемое значение уверенности следует рассматривать критически. Показатель ниже 0.7 часто означает, что кодировка определена на основе недостаточной статистики или файл содержит смешанные данные. В таких случаях результат стоит использовать как гипотезу, а не как окончательное решение.
Для русскоязычных текстов chardet обычно корректно различает UTF-8 и Windows-1251, но может ошибаться между близкими однобайтовыми кодировками при наличии коротких строк, большого количества чисел или технических данных. Логи, конфигурационные файлы и CSV без естественного языка являются типичными источниками неточных определений.
Оптимальный сценарий использования chardet – предварительное определение кодировки с последующей попыткой декодирования и проверкой отсутствия ошибок. Такой подход позволяет отфильтровать ложные срабатывания и избежать искажения текста при дальнейшей обработке.
Использование charset-normalizer для файлов с Unicode
Библиотека charset-normalizer ориентирована на распознавание Unicode-кодировок и поставляется как стандартный инструмент в современных версиях Python через зависимости. В отличие от вероятностных моделей старого типа, она анализирует корректность декодирования, а не только частоту символов, что делает её более предсказуемой при работе с UTF-8, UTF-16 и UTF-32.
Основой работы charset-normalizer является проверка валидности байтовых последовательностей. Каждая возможная кодировка оценивается по количеству допустимых символов, наличию некорректных байтов и степени искажения текста. Результат представляет собой список кандидатов, отсортированных по качеству декодирования, а не единственное предположение.
Для файлов с Unicode библиотека почти всегда выдвигает utf_8 или utf_8_sig на первое место, корректно учитывая наличие BOM. Это особенно полезно при обработке данных из веб-источников, API и современных редакторов, где UTF-8 является де-факто стандартом, но может быть сохранён в разных вариантах.
Если файл содержит смешанный текст или повреждённые участки, charset-normalizer позволяет оценить долю успешно декодированных символов. Низкий показатель читаемости указывает на ошибочную гипотезу или на то, что файл не является текстовым. Такой сигнал важен при автоматической обработке больших наборов данных.
На практике библиотеку удобно использовать как основной инструмент для Unicode-файлов, дополняя её ручной проверкой результата через попытку чтения. Это снижает риск скрытых искажений, которые не вызывают исключений, но приводят к потере информации в тексте.
Проверка кодировки через попытку декодирования в Python

Самый надёжный способ подтвердить предполагаемую кодировку – попытаться декодировать файл с явным указанием параметра encoding. В отличие от автоматического распознавания, этот метод сразу выявляет несовместимость байтов и выбранной кодировки через исключение UnicodeDecodeError или через появление искажённых символов.
Проверку удобно выполнять последовательно, перебирая ограниченный список вероятных кодировок. Для кириллических файлов обычно рассматриваются UTF-8, Windows-1251 и KOI8-R, для данных из Unix-систем – UTF-8 и ISO-8859-5. Полный перебор всех возможных вариантов нецелесообразен и затрудняет интерпретацию результата.
- Файл открывается в текстовом режиме с явно указанной кодировкой
- Считывается небольшая часть данных, а не весь файл целиком
- Фиксируется либо успешное чтение, либо возникшее исключение
Даже при отсутствии ошибок декодирования результат следует оценивать визуально или программно. Наличие символов замены �, неожиданных управляющих знаков или искажённых букв указывает на неверный выбор кодировки, несмотря на формально успешное чтение.
Для автоматизации проверки полезно анализировать результат декодирования:
- Подсчитать количество непечатных символов
- Проверить наличие типичных букв целевого языка
- Оценить долю ASCII-символов относительно общего объёма
Метод попытки декодирования хорошо дополняет результаты библиотек распознавания и позволяет принять окончательное решение перед дальнейшей обработкой текста, особенно в сценариях с нестандартными или устаревшими форматами данных.
Определение кодировки текстовых файлов с BOM
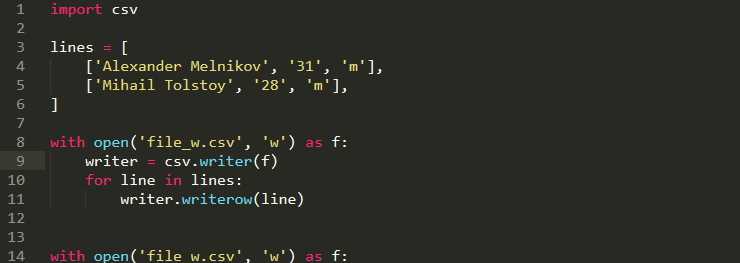
BOM представляет собой специальную байтовую метку в начале файла, которая явно указывает используемую Unicode-кодировку. В Python анализ BOM выполняется на уровне байтов и не требует сторонних библиотек, что делает этот способ надёжным для первичной диагностики.
Чаще всего встречается BOM для UTF-8 в виде последовательности 0xEF 0xBB 0xBF. Для UTF-16 используются двухбайтовые маркеры, различающиеся порядком байтов: 0xFF 0xFE для Little Endian и 0xFE 0xFF для Big Endian. Реже можно встретить BOM для UTF-32, занимающий четыре байта.
При обнаружении BOM кодировка определяется однозначно, а дальнейший анализ содержимого файла не требуется. В Python такие файлы корректно обрабатываются при указании кодировки utf-8-sig или соответствующего варианта UTF-16, что автоматически удаляет служебную метку из текста.
Отсутствие BOM не означает, что файл не использует Unicode. Большинство UTF-8 файлов сохраняются без этой метки, поэтому проверка BOM должна рассматриваться как быстрый фильтр, а не универсальное решение для всех случаев.
При автоматической обработке данных рекомендуется сначала проверять наличие BOM, затем переходить к анализу байтов и только после этого использовать статистические методы. Такая последовательность позволяет избежать ложных определений и упрощает логику обработки кодировок.
Обработка ошибок при неверно определённой кодировке

Перехват исключений при чтении файла позволяет сохранить контроль над выполнением программы. Вместо аварийного завершения можно зафиксировать неудачную попытку, сменить кодировку и повторить операцию. Такой подход особенно полезен в скриптах, обрабатывающих большие коллекции файлов с неизвестным происхождением.
Даже при отсутствии исключений возможны скрытые ошибки. Использование параметра errors=»replace» или errors=»ignore» устраняет сбой, но приводит к потере данных и затрудняет диагностику. Эти режимы допустимы только на этапе анализа, но не при финальном чтении данных для дальнейшей обработки.
Практичным решением является проверка результата декодирования: поиск символов замены, подсчёт управляющих кодов и анализ доли читаемого текста. Если искажения превышают допустимый порог, файл следует повторно проанализировать другими методами определения кодировки.
Для воспроизводимости ошибок рекомендуется логировать имя файла, используемую кодировку и тип сбоя. Это упрощает отладку и позволяет со временем сформировать список корректных кодировок для конкретных источников данных, снижая вероятность повторных ошибок.
Вопрос-ответ:
Почему Python выбрасывает UnicodeDecodeError, хотя файл открывается в текстовом редакторе без проблем?
Текстовые редакторы часто используют автоматическое определение кодировки и могут корректно отображать файл, не сообщая, какая именно кодировка применена. Python же требует точного указания параметра encoding. Если реальная кодировка файла отличается от ожидаемой, интерпретатор сразу сообщает об ошибке. Частая ситуация — файл сохранён в Windows-1251, а Python пытается читать его как UTF-8.
Можно ли определить кодировку файла без сторонних библиотек?
Да, частично. Python позволяет считать файл в бинарном режиме и проверить наличие BOM, что помогает распознать UTF-8, UTF-16 и UTF-32. Также можно поочерёдно пробовать декодировать файл с предполагаемыми кодировками и анализировать результат. Такой подход требует аккуратной проверки текста, так как отсутствие ошибки не гарантирует корректность отображения символов.
Почему chardet иногда ошибается на CSV или логах?
chardet опирается на статистику символов и языковые модели. В файлах, где преобладают числа, разделители, технические ключи или короткие строки, таких закономерностей недостаточно. В результате библиотека строит предположение на слабых сигналах и может выбрать неверную кодировку, особенно среди близких однобайтовых вариантов.
Как понять, что файл вообще не является текстовым?
При чтении бинарных данных как текста обычно обнаруживаются нулевые байты, большое количество управляющих символов и хаотичное распределение значений. Попытки декодирования приводят либо к множеству замен символов, либо к исключениям для большинства кодировок. В таких случаях дальнейший поиск текстовой кодировки не имеет смысла.