Содержание статьи

Графы широко применяются для моделирования социальных сетей, маршрутов транспортных систем и сетей зависимостей в приложениях. Выбор метода хранения напрямую влияет на скорость выполнения запросов и объем занимаемой памяти. Например, для графа с 100 000 вершин и 500 000 рёбер матрица смежности потребует около 10 ГБ памяти, тогда как список смежности займет менее 1 ГБ.
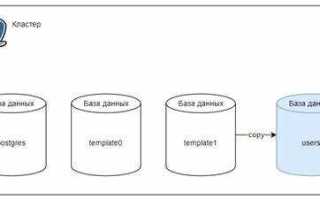
Реляционные СУБД позволяют хранить графовые структуры через таблицы вершин и рёбер, но сложные запросы на многозвенные связи могут резко замедляться. В таких случаях использование индексов по столбцам source и target ускоряет поиск связей в 10–15 раз. Для иерархических графов удобно применять вложенные множества или пути, что сокращает количество JOIN-запросов.
Документоориентированные базы данных и графовые движки поддерживают Property Graph, где вершины и рёбра имеют набор атрибутов. Это облегчает хранение метаданных, например веса связи или временной метки, без создания дополнительных таблиц. При проектировании схемы хранения важно учитывать частоту изменений рёбер: динамические графы требуют алгоритмов обновления индексов и кэширования соседей.
Методы хранения графов в базе данных определяют возможности анализа и масштабирования приложений. Планирование структуры данных с учетом характера запросов и размера графа снижает нагрузку на систему и повышает скорость выполнения операций поиска и агрегации.
Сравнение матрицы смежности и списка смежности для реляционных баз данных
Матрица смежности и список смежности представляют два разных подхода к хранению графов в реляционных базах данных. Выбор структуры зависит от плотности графа, объема данных и типов запросов.
Матрица смежности:
- Представляется таблицей NxN, где N – количество вершин. Каждая ячейка содержит 1 (ребро существует) или 0 (ребра нет).
- Подходит для плотных графов, где количество ребер близко к N².
- Операции проверки существования ребра выполняются за O(1).
- Хранение больших разреженных графов неэффективно: память растет пропорционально N², большинство ячеек пустые.
- Реализация в SQL: таблица с колонками vertex_from, vertex_to и флагом связи либо полностью матричная таблица с N колонками.
Список смежности:
- Каждая вершина хранит список связанных вершин. В реляционной базе это таблица с колонками vertex_id и adjacent_vertex_id.
- Оптимален для разреженных графов: хранится только существующие ребра, объем данных пропорционален числу ребер E.
- Проверка существования ребра требует поиска по индексу или фильтрации, сложность O(k), где k – число смежных вершин.
- Легко реализовать динамическое добавление и удаление вершин или ребер без перерасчета всей структуры.
- Упрощает выполнение запросов, связанных с обходом графа, подсчетом степени вершин и выборкой смежных узлов.
Рекомендации:
- Использовать матрицу смежности для графов с небольшим количеством вершин (<1000) и высокой плотностью (>50% возможных ребер).
- Использовать список смежности для больших разреженных графов, где E << N², чтобы снизить затраты на хранение.
- Для анализа маршрутов и обхода графа предпочтительнее список смежности.
- Для быстрых проверок существования ребра без учета обхода – матрица смежности.
- В реляционной модели список смежности проще индексировать, что ускоряет выборки по конкретной вершине.
Использование вложенных множеств для представления иерархий графа
Метод вложенных множеств (Nested Sets) применяется для хранения иерархий в реляционных базах данных, позволяя эффективно выполнять запросы на извлечение поддеревьев без рекурсивных соединений.
Каждый узел графа получает два числовых значения: left и right. Эти значения отражают позицию узла в обходе дерева, где все потомки узла имеют left и right внутри диапазона родителя.
- Выбор всех потомков узла выполняется запросом
WHERE left > parent_left AND right < parent_right. - Определение уровня узла в иерархии возможно через подсчет числа узлов с
left < current_leftиright > current_right. - Добавление узла требует смещения
leftиrightвсех последующих узлов на 2 единицы. - Удаление узла и его поддерева выполняется с аналогичным смещением.
- Метод позволяет выполнять сложные выборки: все листья, подсчет глубины поддерева, фильтрацию по уровню.
Рекомендации:
- Использовать для относительно стабильных иерархий с редкими вставками и удалениями.
- Для частых изменений деревьев предпочтительнее материализованные пути или adjacency list с рекурсивными запросами.
- Индексация по колонкам
leftиrightсущественно ускоряет выборки поддеревьев. - Для анализа больших графов с тысячами узлов использовать транзакции при смещении значений, чтобы избежать неконсистентности.
- Комбинировать с дополнительными атрибутами узлов (например,
level,parent_id) для упрощения фильтрации и сортировки.
Применение модели Property Graph в документоориентированных СУБД

Модель Property Graph позволяет хранить вершины и ребра графа с произвольными атрибутами, что удобно для документоориентированных СУБД, где каждый узел и связь представляются как отдельные документы.
Структура хранения включает коллекции для вершин и ребер. Вершины содержат идентификатор и набор свойств, ребра – ссылки на начальную и конечную вершины, а также свойства связи.
| Коллекция | Пример документа | Назначение |
|---|---|---|
| Vertices | {
«_id»: «u1», «type»: «User», «name»: «Иван», «age»: 30 } |
Хранение узлов графа с набором атрибутов |
| Edges | {
«_id»: «e1», «from»: «u1», «to»: «u2», «relation»: «friend», «since»: «2022-05-01» } |
Описание направленных связей между узлами с дополнительными свойствами |
Рекомендации:
- Использовать индексирование по
_idи свойствамfrom/toдля ускорения поиска соседних вершин и обхода графа. - Для анализа сложных связей применять агрегации и pipeline-функции, характерные для документоориентированных СУБД.
- При больших графах с тысячами вершин и миллионов ребер рекомендуется хранить часто запрашиваемые свойства напрямую в документе ребра, чтобы сократить количество join-подобных операций.
- Обновление свойств узлов и ребер выполнять через атомарные операции, чтобы избежать частичной несогласованности графа.
- Использовать Property Graph для гибкой схемы, когда количество и тип атрибутов может меняться для разных узлов и связей.
Оптимизация запросов с помощью индексов для графовых связей
Индексы существенно ускоряют выборку смежных вершин и фильтрацию по свойствам ребер. В реляционных базах данных для графов используются составные и одно-колоночные индексы на таблицах связей.
Примеры индексов:
- Индекс по
(vertex_from, vertex_to)ускоряет проверку существования конкретного ребра. - Индекс по
vertex_fromоптимизирует выборку всех смежных вершин для обхода графа. - Индекс по свойствам ребра (
relation_type,weight) ускоряет фильтрацию по типу или весу связи. - Комбинированные индексы (
vertex_from, relation_type) эффективны для поиска соседей с конкретными типами ребер.
В документоориентированных СУБД индексация выполняется на полях from и to:
- Индекс на
fromускоряет выборку всех исходящих связей. - Индекс на
toнужен для поиска всех входящих ребер. - Индексация вложенных свойств позволяет фильтровать связи по атрибутам, например, дате создания или статусу.
Рекомендации:
- Создавать индексы на столбцах, участвующих в WHERE и JOIN для связей.
- Для больших графов с миллионами ребер комбинировать составные индексы с частичной индексацией по часто используемым значениям.
- Следить за балансом между количеством индексов и временем вставки/обновления: избыточная индексация снижает производительность изменений.
- Использовать индексы для оптимизации рекурсивных запросов и обходов, особенно при вычислении подграфов или кратчайших путей.
- Регулярно анализировать статистику использования индексов и удалять неиспользуемые для снижения нагрузки на СУБД.
Хранение динамических графов с учётом частых изменений связей
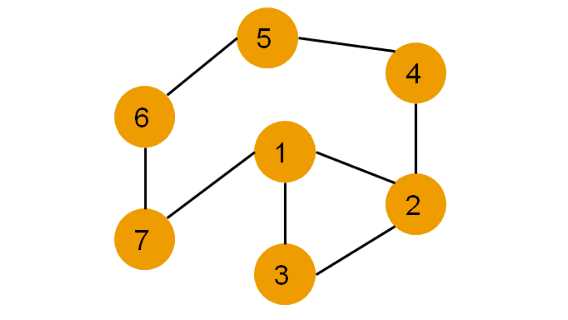
Динамические графы характеризуются частыми добавлениями, удалениями и изменениями ребер. Выбор структуры хранения влияет на скорость обновлений и эффективность запросов.
Список смежности является оптимальным для динамических графов:
- Хранится таблица с колонками
vertex_idиadjacent_vertex_id, что позволяет добавлять и удалять связи за O(1) при использовании индексов. - Фильтрация по свойствам ребер выполняется через индексы на дополнительных колонках.
- Поддержка транзакций обеспечивает консистентность при массовых обновлениях.
Матрица смежности подходит только для небольших графов с высокой плотностью:
- Обновление ребра требует изменения одной ячейки, но при удалении или добавлении вершины необходимо перерасчет всей матрицы.
- Реализация больших разреженных графов крайне неэффективна по памяти.
Рекомендации для реляционных СУБД:
- Использовать отдельную таблицу Edges с индексами по
vertex_fromиvertex_toдля ускорения выборки смежных узлов. - При массовых вставках применять пакетные операции и временные таблицы для минимизации блокировок.
- Для графов с миллионами ребер использовать партиционирование таблиц по диапазону вершин или по свойствам ребер.
- Регулярно обновлять статистику индексов для корректного планирования запросов.
- При изменении атрибутов ребер хранить историю изменений в отдельной таблице для поддержки версионности графа.
Рекомендации для документоориентированных СУБД:
- Хранить вершины и ребра как отдельные документы с уникальными идентификаторами.
- Индексировать поля
from,toи ключевые свойства для ускорения выборок. - Для часто изменяемых ребер использовать атомарные операции update и bulk write.
- Разделять коллекции на активные и архивные связи для оптимизации хранения и уменьшения объема индексов.
Интеграция графовых и реляционных данных для анализа связей
Для анализа связей часто требуется объединение графовой модели и традиционных реляционных данных. Графовые структуры позволяют работать с топологией, а реляционные таблицы хранят свойства и атрибуты объектов.
Методы интеграции:
- Использование внешних ключей: таблицы вершин связаны с реляционными таблицами через
vertex_id, что позволяет получать свойства узлов без дублирования данных. - Создание промежуточных представлений (views) или объединенных таблиц, включающих свойства из реляционной базы и смежные вершины для ускорения запросов.
- Использование SQL JOIN и фильтров совместно с графовыми функциями для поиска соседей, подсчета степени узлов и построения подграфов.
- В документоориентированных СУБД связывание осуществляется через вложенные документы или ссылки на коллекции с атрибутами из реляционных таблиц.
Рекомендации:
- Индексировать
vertex_idв реляционных таблицах и идентификаторы узлов в графовой модели для ускорения объединений. - Для больших графов использовать агрегированные представления с заранее рассчитанными связями для часто запрашиваемых подграфов.
- Разделять статические атрибуты узлов и динамические связи, чтобы минимизировать блокировки при обновлениях.
- Использовать ETL-процессы для синхронизации реляционных данных с графовой структурой при анализе больших объемов информации.
- Применять графовые функции и процедуры для вычисления центральности, кратчайших путей и кластеризации на основе объединенных данных.
Вопрос-ответ:
Какие критерии выбирать при выборе между матрицей смежности и списком смежности для реляционной базы?
Выбор зависит от плотности графа и объема данных. Матрица смежности подходит для плотных графов с небольшим числом вершин, так как проверка существования ребра выполняется за константное время, но требует память, пропорциональную N². Список смежности эффективен для разреженных графов: хранится только существующие связи, объем памяти растет линейно от числа ребер, а добавление и удаление ребер выполняется быстро. Для динамических или крупных графов предпочтительнее использовать список смежности.
Как вложенные множества помогают выполнять выборку поддеревьев в иерархическом графе?
Метод вложенных множеств присваивает каждому узлу значения left и right на основе обхода дерева. Все потомки узла находятся внутри диапазона этих значений. Таким образом, выбор всех дочерних узлов выполняется одним запросом с условием WHERE left > parent_left AND right < parent_right, без необходимости рекурсивных соединений. Дополнительно можно вычислить уровень узла, подсчитав количество охватывающих его узлов, что упрощает фильтрацию по глубине и построение подграфов.
Какие индексы наиболее полезны для ускорения работы с графовыми связями в реляционной базе?
Для таблиц связей создаются индексы по колонкам vertex_from и vertex_to. Индекс на обоих полях одновременно ускоряет проверку существования конкретного ребра. Если ребра имеют тип или вес, имеет смысл создать составные индексы (vertex_from, relation_type) или отдельные индексы по атрибутам ребра. Эти индексы сокращают время выборки соседних узлов, фильтрации по типу связи и выполнения обходов подграфов. Для больших графов частичная индексация по часто встречающимся значениям позволяет снизить нагрузку на СУБД.
Как интегрировать графовые данные с реляционными для анализа связей?
Связь между графовыми вершинами и реляционными таблицами осуществляется через уникальные идентификаторы узлов. Например, vertex_id в таблице вершин связывается с таблицами с атрибутами объектов. Для ускорения выборки создаются представления, объединяющие свойства узлов с их смежными вершинами. SQL JOIN или агрегации позволяют анализировать подграфы с учетом реляционных данных. В документоориентированных СУБД используется хранение ссылок или вложенных документов для атрибутов, а индексация ключевых полей ускоряет фильтрацию и обход графа.