В pandas индекс определяет способ идентификации строк в DataFrame и влияет на доступ к данным, объединение таблиц и фильтрацию. Неправильный выбор индекса может замедлить операции выборки и усложнить обработку больших наборов данных, особенно при работе с миллионами строк.

Прямое указание нового индекса при создании DataFrame позволяет сразу структурировать данные под конкретные задачи анализа. Например, использование уникальных идентификаторов клиентов в качестве индекса ускоряет поиск и упрощает группировку.
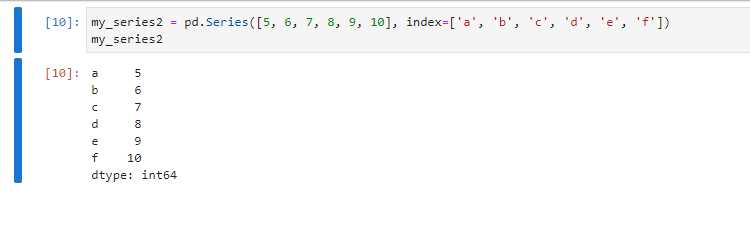
Использование существующих столбцов для замены текущего индекса помогает поддерживать актуальность данных без создания дополнительных столбцов. С помощью set_index() можно выбрать один или несколько столбцов, сразу создавая многоуровневый индекс для сложной аналитики.
 можно выбрать один или несколько столбцов, сразу создавая многоуровневый индекс для сложной аналитики.»>
можно выбрать один или несколько столбцов, сразу создавая многоуровневый индекс для сложной аналитики.»>
Сброс индекса с помощью reset_index() полезен, когда необходимо сохранить порядок строк и преобразовать индекс в обычный столбец для дальнейшей обработки. Этот подход особенно востребован при подготовке данных к экспорту в CSV или для работы с внешними библиотеками.
Понимание возможностей переиндексации, сортировки и переименования уровней индекса позволяет строить гибкие алгоритмы анализа, корректно объединять таблицы и избегать ошибок при работе с дублированными значениями.
Вопрос-ответ:
Как в pandas заменить текущий индекс на один из столбцов DataFrame?
Для замены индекса на один из столбцов используется метод set_index(). Например, если есть DataFrame с колонками «id», «имя», «возраст», можно сделать колонку «id» индексом: df.set_index(«id», inplace=True). После этого строки будут идентифицироваться по значениям «id», а сам столбец исчезнет из обычных колонок, но останется доступным через индекс.
Когда нужно сбрасывать индекс в DataFrame и как это сделать?
Сброс индекса полезен, если необходимо вернуть стандартную нумерацию строк и сделать текущий индекс обычной колонкой. Для этого используется метод reset_index(). Например, df.reset_index(inplace=True) создаст новый числовой индекс, а прежний индекс переместит в колонку с соответствующим названием. Это удобно при объединении таблиц или перед экспортом данных в CSV.
Можно ли создать многоуровневый индекс из нескольких колонок?
Да, pandas поддерживает многоуровневые индексы (MultiIndex). Для этого в set_index() передается список колонок: df.set_index([«город», «год»], inplace=True). В результате строки будут идентифицироваться комбинацией значений двух колонок, что упрощает фильтрацию и агрегирование данных по нескольким критериям одновременно.
Как переиндексировать DataFrame с использованием нового списка меток?
Для замены индекса на конкретный список значений применяется метод reindex(). Например, если текущие индексы — [1, 2, 3], а нужно установить [2, 3, 4], выполняется df.reindex([2, 3, 4]). Строки с отсутствующими значениями создаются с NaN, что позволяет заранее подготовить DataFrame под новый порядок или фильтровать недостающие данные.
Как изменить имена уровней многоуровневого индекса?
Для переименования уровней MultiIndex используется атрибут index.names. Например, если текущий индекс создан из колонок «город» и «год», можно задать новые имена: df.index.names = [«регион», «период»]. Это улучшает читаемость таблицы и позволяет удобнее ссылаться на уровни при группировках и агрегациях.
Как сохранить старый индекс при замене его на новый в pandas?
Если нужно изменить индекс, но при этом сохранить старый в качестве обычной колонки, можно использовать метод set_index() с параметром drop=False. Например, df.set_index(«новый_столбец», drop=False, inplace=True) заменит текущий индекс на значения из «новый_столбец», а старый индекс станет отдельной колонкой. Это удобно, когда старый индекс содержит важные данные, которые могут понадобиться для объединения таблиц, фильтрации или анализа.