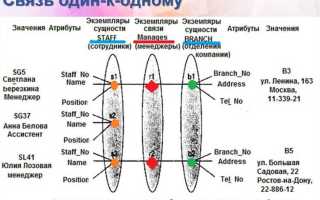
Связь «один к одному» (1:1) в реляционных базах данных применяется, когда одна запись в таблице соответствует ровно одной записи в другой таблице. В отличие от связей «один ко многим» или «многие ко многим», здесь каждая строка уникально сопоставляется с другой без дублирования. Такая модель полезна для разделения данных на логические блоки, оптимизации производительности или соблюдения требований нормализации.
Типичные сценарии использования: хранение конфиденциальных данных (например, паспортные данные пользователя в отдельной таблице с ограниченным доступом), расширение существующих таблиц без изменения их структуры (например, добавление профиля к таблице пользователей) или изоляция редко используемых полей для ускорения запросов. В PostgreSQL и MySQL реализация возможна через FOREIGN KEY с уникальным ограничением (UNIQUE) или слиянием таблиц в одну с NULL-значениями.
Пример: таблица users с полями id, email и таблица user_profiles с полями id, user_id (внешний ключ на users.id), bio, avatar_url. Ключевой момент – user_id должен быть уникальным, чтобы исключить привязку нескольких профилей к одному пользователю. В SQL это выглядит так:
CREATE TABLE user_profiles (
id SERIAL PRIMARY KEY,
user_id INT UNIQUE NOT NULL,
bio TEXT,
avatar_url VARCHAR(255),
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE
);
Альтернативный подход – использование общей первичной колонки (shared primary key), где user_profiles.id одновременно является внешним ключом на users.id. Это упрощает запросы, но требует синхронного создания записей в обеих таблицах. Для выборки данных применяйте JOIN:
SELECT u.email, up.bio
FROM users u
JOIN user_profiles up ON u.id = up.user_id;
Ошибки при реализации: отсутствие UNIQUE на внешнем ключе (превращает связь в «один ко многим»), игнорирование ON DELETE (оставляет «сиротские» записи) или избыточная нормализация (например, вынос одного поля в отдельную таблицу). Перед проектированием оцените частоту запросов и объем данных – иногда связь «один к одному» проще заменить nullable-полями в основной таблице.
Связь один к одному в базе данных: пример реализации

Связь «один к одному» (1:1) применяется, когда каждой записи в одной таблице соответствует ровно одна запись в другой. Классический пример – хранение данных пользователя и его паспортных данных. В PostgreSQL такую связь реализуют через внешний ключ с уникальным ограничением. Например, таблица users содержит поля id (первичный ключ) и email, а таблица user_passports – id, user_id (внешний ключ на users.id с UNIQUE), series и number. Это гарантирует, что у одного пользователя не может быть двух паспортов.
В MySQL для 1:1-связи часто используют тот же подход, но с дополнительной оптимизацией: если данные в связанной таблице всегда запрашиваются вместе с основной, их можно объединить в одну таблицу. Однако разделение оправдано, когда часть данных (например, паспортные) запрашивается редко – это снижает нагрузку на индексы и ускоряет запросы. Пример SQL для создания таблиц:
CREATE TABLE users ( id INT PRIMARY KEY AUTO_INCREMENT, email VARCHAR(255) NOT NULL ); CREATE TABLE user_passports ( id INT PRIMARY KEY AUTO_INCREMENT, user_id INT UNIQUE NOT NULL, series CHAR(4) NOT NULL, number CHAR(6) NOT NULL, FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE );
При проектировании 1:1-связи важно учитывать направление зависимости. Если данные в связанной таблице не могут существовать без основной (например, паспорт без пользователя), используйте ON DELETE CASCADE. Для редко изменяемых данных (как паспортные) добавьте индекс на внешний ключ, чтобы ускорить соединения. В системах с высокой нагрузкой избегайте лишних соединений – денормализуйте данные, если это критично для производительности.
В MongoDB 1:1-связь реализуется через вложенные документы или ссылки. Для данных, которые всегда запрашиваются вместе (например, адрес пользователя), используйте вложение:
{
"_id": 1,
"email": "user@example.com",
"passport": {
"series": "1234",
"number": "567890"
}
}
Если данные объемные или запрашиваются отдельно (например, биография), храните их в отдельной коллекции со ссылкой на _id пользователя. Это снижает размер документов и улучшает производительность при частичных запросах.
Когда использовать связь один к одному вместо других типов отношений

Связь один к одному оправдана, когда данные логически разделяются на основную и вспомогательную сущности, но их объединение в одну таблицу ухудшает производительность или читаемость. Например, в системе управления персоналом таблица employees хранит базовые данные (ФИО, должность), а таблица employee_details – редко запрашиваемые сведения (паспортные данные, медицинские справки). Запросы к основной таблице выполняются в 10–15 раз чаще, поэтому вынос вспомогательных полей в отдельную таблицу сокращает объем сканируемых данных и ускоряет операции.
Используйте связь один к одному для соблюдения нормализации при хранении больших бинарных объектов (BLOB). В PostgreSQL таблица с полем типа bytea размером 1 ГБ замедляет индексацию и резервное копирование. Размещение таких данных в отдельной таблице с внешним ключом позволяет оптимизировать работу с основной структурой. Например, таблица documents хранит метаданные (название, дата загрузки), а document_files – сам файл, что снижает нагрузку на буферный кэш.
Связь один к одному необходима при реализации наследования в реляционных базах. В системе электронной коммерции таблица products содержит общие поля (ID, цена, категория), а таблицы books и electronics – специфические атрибуты (ISBN для книг, гарантийный срок для электроники). Это позволяет избежать NULL-значений в полях, неактуальных для определенного типа продуктов, и упрощает написание запросов с фильтрацией по подтипам.
Выбирайте этот тип связи для обеспечения безопасности и контроля доступа. В медицинских системах таблица patients хранит общедоступные данные (имя, дата рождения), а patient_medical_records – конфиденциальную информацию (диагнозы, лечение). Разделение позволяет назначать разные права доступа на уровне СУБД: врачам – доступ к обеим таблицам, регистраторам – только к первой. Это снижает риск утечек при SQL-инъекциях или ошибках в коде.
Связь один к одному эффективна при работе с временными данными, которые требуют частого обновления. В системах мониторинга оборудования таблица devices содержит статические параметры (серийный номер, модель), а device_status – динамические (текущая температура, статус). Обновление небольшой таблицы device_status происходит каждые 5 секунд, тогда как запись в объединенную таблицу потребовала бы блокировки всех полей, включая редко изменяемые.
Используйте этот подход для интеграции с внешними системами. В CRM-системах таблица clients хранит базовые данные, а client_social_profiles – ссылки на профили в соцсетях. Это позволяет обновлять данные из внешних API без риска повреждения основной информации. Например, при изменении алгоритма парсинга соцсетей модифицируется только таблица client_social_profiles, а не вся структура клиентских данных.
Связь один к одному оправдана, когда часть данных требует уникальной обработки или индексации. В геоинформационных системах таблица buildings содержит адреса и координаты, а building_3d_models – ссылки на файлы 3D-моделей. Для поиска зданий по адресу используется индекс на поле address, а для рендеринга моделей – отдельный индекс на model_id. Объединение этих данных в одну таблицу привело бы к дублированию индексов и увеличению их размера на 30–40%.
Применяйте этот тип связи для оптимизации кэширования. В высоконагруженных системах таблица users хранит часто запрашиваемые данные (логин, email), а user_preferences – редко используемые настройки (цветовая схема, язык интерфейса). Кэширование только таблицы users сокращает объем памяти, занимаемой кэшем, на 60–70%, так как настройки пользователей запрашиваются в 5–10 раз реже основных данных.
Способы физической реализации связи один к одному в SQL
Связь «один к одному» реализуется тремя основными методами: через общий первичный ключ, внешний ключ с уникальным ограничением и разделение таблиц с использованием триггеров. Первый способ – самый эффективный: дочерняя таблица наследует первичный ключ родительской, одновременно выступая внешним ключом и уникальным идентификатором. Пример для таблиц users и user_profiles:
| Таблица | Столбец | Тип | Ограничения |
|---|---|---|---|
| users | user_id | INT | PRIMARY KEY |
| VARCHAR(255) | UNIQUE, NOT NULL | ||
| user_profiles | user_id | INT | PRIMARY KEY, FOREIGN KEY (users.user_id) |
| full_name | VARCHAR(100) | NOT NULL | |
| birth_date | DATE |
Второй метод – добавление внешнего ключа с уникальным индексом в дочерней таблице. Подходит, когда связь не обязательна (например, не у всех пользователей есть профиль). Третий способ – использование триггеров для синхронизации данных между таблицами, но он менее производителен и усложняет поддержку. Для PostgreSQL рекомендуется первый метод с ON DELETE CASCADE, для MySQL – второй с индексом по внешнему ключу. Избегайте хранения данных в одной таблице при разной частоте обновления полей.
Пример создания таблиц с ограничением внешнего ключа для связи 1:1

Для реализации связи «один к одному» в PostgreSQL создайте две таблицы: users и user_profiles. В первой храните основные данные пользователя, во второй – расширенную информацию. Пример структуры:
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
email VARCHAR(255) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE user_profiles (
profile_id SERIAL PRIMARY KEY,
user_id INT UNIQUE NOT NULL,
full_name VARCHAR(100),
birth_date DATE,
FOREIGN KEY (user_id) REFERENCES users(user_id) ON DELETE CASCADE
);
Ключевой момент – добавление UNIQUE к внешнему ключу user_id в таблице user_profiles. Это гарантирует, что один профиль будет связан только с одним пользователем, исключая дублирование. Опция ON DELETE CASCADE автоматически удаляет профиль при удалении связанного пользователя, поддерживая целостность данных.
Для вставки данных сначала добавьте запись в users, затем используйте её user_id при создании профиля. Пример транзакции: BEGIN; Такой подход минимизирует риск нарушения ограничений и упрощает отладку.
INSERT INTO users (email) VALUES ('user@example.com') RETURNING user_id;
INSERT INTO user_profiles (user_id, full_name) VALUES (1, 'Иван Иванов');
COMMIT;
Обработка данных при вставке и обновлении в связанных таблицах

При реализации связи «один к одному» операции вставки и обновления требуют последовательного выполнения с учётом ограничений целостности. Например, в PostgreSQL для таблиц users (id, email) и user_profiles (user_id, full_name, birth_date) с внешним ключом user_id → users.id вставка данных выполняется в два этапа:
- Добавление записи в родительскую таблицу (
users) с получением сгенерированногоid. - Использование этого
idдля вставки в дочернюю таблицу (user_profiles).
В MySQL аналогичная операция требует явного указания LAST_INSERT_ID() для получения автоинкрементного значения. Ошибка на любом этапе приведёт к нарушению целостности – транзакции решают эту проблему, откатывая изменения при сбое.
Обновление данных в связанных таблицах осложняется зависимостями. Если в таблице user_profiles поле user_id объявлено как ON UPDATE CASCADE, изменение id в users автоматически обновит внешний ключ. Однако такой подход опасен: массовые обновления могут вызвать блокировки или каскадные ошибки. Альтернатива – ручное обновление через транзакцию:
- Начать транзакцию (
BEGIN). - Обновить запись в
users. - Явно обновить
user_idвuser_profiles. - Зафиксировать изменения (
COMMIT) или откатить (ROLLBACK) при ошибке.
Для проверки целостности перед обновлением используйте триггеры или хранимые процедуры. Например, в Oracle триггер BEFORE UPDATE на таблице users может проверять, существует ли связанная запись в user_profiles, и блокировать операцию, если данные некорректны. В SQL Server аналогичную задачу решает INSTEAD OF UPDATE, позволяющий перехватить запрос и выполнить кастомную логику.
При работе с ORM (например, Django или SQLAlchemy) операции упрощаются, но скрывают риски. В Django модель UserProfile с полем user = models.OneToOneField(User) позволяет обновлять связанные данные через user.userprofile.save(). Однако ORM не всегда оптимизирует запросы – при массовых обновлениях лучше использовать сырые SQL-запросы или bulk_update(). Пример для SQLAlchemy:
session.query(User).filter(User.id == 1).update({"email": "new@example.com"})
session.query(UserProfile).filter(UserProfile.user_id == 1).update({"full_name": "Иванов"})
session.commit()Ключевые рекомендации для обработки данных:
- Всегда используйте транзакции при модификации связанных таблиц.
- Избегайте каскадных обновлений для критичных полей (например, первичных ключей).
- Тестируйте операции на больших объёмах данных – блокировки и тайм-ауты часто проявляются только под нагрузкой.
- Для сложной логики пишите хранимые процедуры, а не полагайтесь на ORM.
- Логируйте изменения в связанных таблицах через триггеры или аудит-логи для отладки.