Содержание статьи

Библиотека Pcrec предоставляет набор функций для работы с регулярными выражениями в PHP, позволяя выполнять поиск, замену и проверку строк с высокой точностью. Основные функции включают pcrec_match() для проверки соответствия шаблону, pcrec_replace() для замены совпадений и pcrec_split() для разделения строк по регулярным выражениям.
Использование Pcrec позволяет обрабатывать сложные текстовые данные, включая проверку форматов email, телефонных номеров и идентификаторов. Например, регулярное выражение /^\d{3}-\d{2}-\d{4}$/ с pcrec_match() применимо для валидации номеров социальных страхований в формате США.
Pcrec функции также позволяют автоматизировать замену текста в больших объемах данных. С помощью pcrec_replace() можно быстро исправлять повторяющиеся ошибки в текстах, менять формат дат или нормализовать строки для дальнейшего анализа.
При работе с Pcrec важно учитывать возможные ошибки синтаксиса регулярных выражений и исключения, возникающие при неверных параметрах. Рекомендуется использовать встроенные средства отладки и тестировать регулярные выражения на ограниченных данных перед применением на всей базе.
Практическое применение Pcrec функций включает фильтрацию пользовательского ввода на веб-сайтах, обработку логов серверов, преобразование текстовых данных для аналитических задач и интеграцию с другими инструментами для анализа информации.
Основные функции Pcrec и их синтаксис

Pcrec предоставляет набор функций для работы с регулярными выражениями, каждая из которых имеет конкретное назначение и строгий синтаксис. Основные функции включают:
| Функция | Синтаксис | Назначение |
|---|---|---|
| pcrec_match() | pcrec_match(string $pattern, string $subject, array &$matches = null, int $flags = 0, int $offset = 0) | Проверяет, соответствует ли строка заданному шаблону. При совпадении возвращает 1 и заполняет массив совпадений $matches. |
| pcrec_match_all() | pcrec_match_all(string $pattern, string $subject, array &$matches, int $flags = 0, int $offset = 0) | Ищет все совпадения шаблона в строке и сохраняет их в массив $matches. |
| pcrec_replace() | pcrec_replace(string|array $pattern, string|array $replacement, string|array $subject, int $limit = -1, int &$count = 0) | Заменяет все совпадения шаблона в строке на указанный текст. Используется для исправления форматов данных или очистки текста. |
| pcrec_split() | pcrec_split(string $pattern, string $subject, int $limit = -1, int $flags = 0) | Разделяет строку на массив элементов по регулярному выражению, удобно для парсинга CSV или логов. |
| pcrec_grep() | pcrec_grep(string $pattern, array $input, int $flags = 0) | Фильтрует массив строк, возвращая только те, что соответствуют шаблону. |
Для корректного использования Pcrec функций рекомендуется строго соблюдать синтаксис регулярных выражений, учитывать режимы поиска и флаги, такие как PREG_OFFSET_CAPTURE для получения смещений совпадений и PREG_UNMATCHED_AS_NULL для обработки отсутствующих групп.
Практика показывает, что тестирование регулярных выражений на небольших данных позволяет избежать ошибок и ускоряет внедрение функций в обработку больших массивов текста.
Обработка строк с помощью Pcrec функций
Pcrec функции позволяют выполнять точечный анализ и трансформацию строк, обеспечивая работу с регулярными выражениями на уровне символов и подстрок. Для проверки наличия определенных паттернов используется pcrec_match(), которая возвращает массив совпадений, включая группы и позиции символов в исходной строке.
Для массового поиска всех вхождений шаблона применяется pcrec_match_all(). Она сохраняет результаты в многоуровневый массив, что удобно при разборе логов или извлечении повторяющихся структур, например, всех email-адресов из текста.
pcrec_replace() используется для изменения формата строк или удаления нежелательных символов. Пример: pcrec_replace(«/[^a-z0-9]/i», «», $text) удаляет все символы, кроме букв и цифр, нормализуя данные для дальнейшего анализа.
pcrec_split() разделяет строку на массив по заданному шаблону, что удобно для обработки CSV-файлов с нестандартными разделителями или разбором URL-параметров. Использование флагов позволяет сохранять разделители в массиве или ограничивать количество элементов.
Для фильтрации массивов строк применяется pcrec_grep(), возвращающая только те элементы, которые соответствуют регулярному выражению. Это ускоряет обработку больших данных без необходимости циклической проверки каждой строки вручную.
Рекомендации по применению: тестировать регулярные выражения на примерах, использовать массивы для хранения совпадений, проверять корректность позиций символов при заменах, а также комбинировать функции для сложной обработки текстов, например, последовательная фильтрация и замена данных.
Применение Pcrec для поиска шаблонов

Pcrec функции позволяют точно находить строки, соответствующие заданным шаблонам, используя регулярные выражения. pcrec_match() применяется для проверки наличия конкретного паттерна в одной строке, возвращая массив совпадений и позиции символов.
Для извлечения всех вхождений шаблона в тексте используется pcrec_match_all(). Она формирует многоуровневый массив, где первый уровень содержит все совпадения, а внутренние – группы регулярного выражения. Пример: поиск всех email-адресов pcrec_match_all(«/[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,4}/i», $text, $matches).
Поиск сложных структур можно комбинировать с флагами, такими как PREG_OFFSET_CAPTURE, чтобы получать смещение каждого совпадения в исходном тексте. Это важно при обработке логов или больших документов, где позиции элементов критичны.
pcrec_grep() позволяет фильтровать массивы строк, возвращая только те, что соответствуют шаблону. Например, из списка URL можно выделить все ссылки на определенный домен: pcrec_grep(«/example\.com/», $urls).
При работе с шаблонами рекомендуется тестировать регулярные выражения на отдельных строках, проверять правильность группировки и учитывать чувствительность к регистру. Это минимизирует ошибки при массовой обработке текстов и повышает точность поиска.
Замена и фильтрация данных через Pcrec
pcrec_replace() позволяет заменять в строках все совпадения шаблона на заданный текст. Пример использования: pcrec_replace(«/\s+/», » «, $text) заменяет все последовательности пробелов на одинарный пробел, что упрощает нормализацию текста.
Для замены с ограничением количества вхождений используется параметр $limit. Например, pcrec_replace(«/foo/», «bar», $text, 2) заменит только первые два совпадения шаблона, оставляя остальные без изменений.
Фильтрация данных выполняется через pcrec_grep(), которая возвращает массив элементов, соответствующих регулярному выражению. Пример: pcrec_grep(«/^\d{4}-\d{2}-\d{2}$/», $dates) выделяет только строки с датами в формате YYYY-MM-DD.
Комбинирование замены и фильтрации позволяет формировать чистые массивы данных и подготовить их к аналитике. Например, сначала отфильтровать строки с нужными паттернами, затем удалить лишние символы и привести формат к единому виду.
Рекомендации по применению: проверять шаблоны на тестовых данных, использовать массивы для множественных замен, контролировать количество замен через $limit, а также учитывать регистр символов с помощью флагов, например PREG_OFFSET_CAPTURE.
Работа с регулярными выражениями в Pcrec

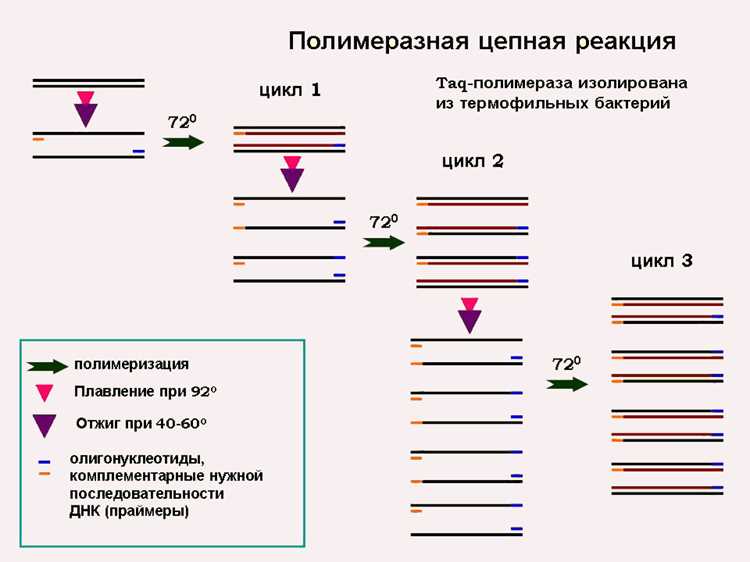
Pcrec функции работают с регулярными выражениями в формате Perl-совместимых шаблонов. Конструкции типа \d, \w, \s позволяют задавать диапазоны символов, а группы (…) и квантификаторы *, +, ? определяют повторения и обязательность элементов.
Для проверки совпадений используется pcrec_match(), где шаблон может включать захватывающие группы для последующего анализа. Пример: /(\d{2})-(\d{2})-(\d{4})/ извлекает день, месяц и год из даты.
pcrec_match_all() позволяет находить все вхождения паттерна в тексте, возвращая многомерный массив с номерами совпадений и позициями. Это удобно для парсинга повторяющихся структур, таких как ссылки или идентификаторы.
Функция pcrec_replace() работает с регулярными выражениями для замены совпадений. Например, pcrec_replace(«/(\d{3})-(\d{2})-(\d{4})/», «$1$2$3», $text) убирает дефисы в номерах, сохраняя числа.
При работе с регулярными выражениями важно учитывать флаги: PREG_OFFSET_CAPTURE для получения смещений совпадений и PREG_UNMATCHED_AS_NULL для обработки отсутствующих групп. Тестирование шаблонов на небольших данных помогает избежать ошибок и повысить точность обработки текстов.
Ошибки и исключения при использовании Pcrec

Pcrec функции могут вызывать ошибки при некорректном синтаксисе регулярных выражений, неверных параметрах или превышении допустимой глубины рекурсии. Основные типы ошибок включают:
- Синтаксические ошибки: неправильное использование метасимволов, незакрытые группы, некорректные квантификаторы.
- Ошибки параметров: передача в функцию не строкового значения или массива там, где ожидается строка.
- Переполнение буфера: слишком длинные шаблоны или текст для обработки, что вызывает pcrec_backtrack_limit или pcrec_recursion_limit.
- Несоответствие флагов: использование неподдерживаемых комбинаций флагов, например PREG_OFFSET_CAPTURE с массивом замены.
Рекомендации по предотвращению ошибок:
- Проверять регулярные выражения через тестовые строки перед применением на реальных данных.
- Использовать функции preg_last_error() для выявления типа ошибки после выполнения Pcrec функции.
- Ограничивать длину обрабатываемых строк и сложность шаблонов, чтобы избежать переполнения стека и превышения лимитов.
- Разделять сложные регулярные выражения на несколько последовательных проверок или замен для упрощения отладки.
Соблюдение этих правил минимизирует вероятность возникновения исключений и повышает стабильность работы с Pcrec при обработке больших массивов текста.
Примеры практического использования Pcrec в проектах
В веб-разработке Pcrec функции применяются для валидации пользовательского ввода. Например, pcrec_match() проверяет формат email или номера телефона перед сохранением в базу данных: pcrec_match(«/^[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,}$/i», $email).
Для обработки логов серверов используют pcrec_match_all(), чтобы извлечь все IP-адреса, даты и коды статусов из файлов access.log: pcrec_match_all(«/(\d{1,3}\.){3}\d{1,3}/», $log, $matches).
pcrec_replace() помогает автоматически исправлять форматы данных. Пример: удаление лишних пробелов и спецсимволов из текстовых полей формы: pcrec_replace(«/[^\w\s]/u», «», $input).
Для анализа массивов строк применяют pcrec_grep(), например, отбор URL, содержащих определенный домен: $filtered = pcrec_grep(«/example\.com/», $urls), что ускоряет работу с большими списками ссылок.
Комбинация функций Pcrec используется в ETL-процессах: фильтрация данных, замена форматов, извлечение ключевых элементов и подготовка текстов к дальнейшей аналитике или загрузке в базы данных.
Вопрос-ответ:
Для чего используют функцию pcrec_match() в PHP?
Функция pcrec_match() проверяет, соответствует ли строка заданному регулярному выражению. Она возвращает 1 при совпадении и заполняет массив $matches с найденными подстроками. Используется для проверки форматов email, номеров телефонов, дат и других структурированных данных перед их сохранением или обработкой.
Чем отличается pcrec_match_all() от pcrec_match()?
pcrec_match_all() ищет все совпадения шаблона в строке, формируя многомерный массив, где первый уровень содержит найденные совпадения, а внутренние уровни — группы регулярного выражения. В отличие от pcrec_match(), она позволяет работать с повторяющимися элементами, например, извлекать все email-адреса из текста.
Как использовать pcrec_replace() для очистки текста от лишних символов?
Функция pcrec_replace() заменяет все совпадения шаблона на указанный текст. Например, pcrec_replace(«/[^\w\s]/u», «», $text) удаляет все символы, кроме букв и цифр, нормализуя текст перед сохранением или анализом. Можно также ограничивать количество замен с помощью параметра $limit.
Когда применяют pcrec_split() и как правильно задавать шаблон разделителя?
pcrec_split() используется для разделения строки на массив по регулярному выражению. Например, pcrec_split(«/[\s,;]+/», $line) разбивает строку по пробелам, запятым и точкам с запятой. Рекомендуется тестировать шаблон на примерах и использовать флаги для сохранения разделителей или ограничения количества элементов.
Какие ошибки чаще всего возникают при работе с Pcrec функциями и как их предотвращать?
Основные ошибки связаны с синтаксисом регулярных выражений, неправильными параметрами и превышением лимитов рекурсии или бэк-трекинга. Для предотвращения ошибок стоит проверять шаблоны на тестовых данных, использовать preg_last_error() для выявления типа ошибки, разбивать сложные выражения на несколько проверок и контролировать длину обрабатываемых строк.
Как с помощью Pcrec функций извлечь все email-адреса из текста?
Для извлечения всех email-адресов используется pcrec_match_all() с регулярным выражением, например: /[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,}/i. Функция возвращает многомерный массив, где каждый элемент соответствует найденному адресу. Дополнительно можно использовать флаг PREG_OFFSET_CAPTURE для получения позиции каждого совпадения в исходном тексте. Такой подход позволяет быстро анализировать большие объемы данных и получать точные результаты без ручного поиска.
Какие правила нужно соблюдать при использовании pcrec_replace() для массовой замены текста?
При работе с pcrec_replace() важно правильно составлять шаблон регулярного выражения, учитывать регистр символов и использовать флаг u для корректной обработки UTF-8. Если требуется заменить только определенное количество совпадений, используется параметр $limit. Для сложных текстов рекомендуется тестировать замену на небольшой выборке, чтобы избежать непредвиденного удаления или изменения данных. Также полезно сохранять оригинальный текст в резервной переменной для проверки результата.