Работа с датами и временем в Python требует точного формата данных. Строки, содержащие даты, часто поступают из CSV, JSON или веб-форм, и для вычислений их нужно конвертировать в объекты datetime. Использование неправильного формата может привести к ValueError или некорректным вычислениям разницы между датами.
Библиотека datetime предоставляет метод strptime, который позволяет явно указать шаблон даты, например «%d-%m-%Y %H:%M:%S». При парсинге больших наборов данных удобно комбинировать pandas.to_datetime, который автоматически определяет формат и поддерживает обработку столбцов с миллионами записей.
Для строк с часовыми поясами важно использовать datetime.strptime вместе с модулем pytz или стандартным zoneinfo в Python 3.9+, чтобы избежать ошибок при вычислениях времени. При работе с нестандартными шаблонами дат стоит заранее определить все варианты формата, чтобы обработка была предсказуемой и не приводила к исключениям.
Использование datetime.strptime для точного формата даты
Метод datetime.strptime позволяет преобразовать строку в объект datetime при точном соответствии формата. Формат задается с помощью символов-шаблонов:
- %Y – полный год с четырьмя цифрами, например 2025
- %m – месяц от 01 до 12
- %d – день месяца от 01 до 31
- %H – часы в 24-часовом формате от 00 до 23
- %M – минуты от 00 до 59
- %S – секунды от 00 до 59
Пример точного преобразования:
- Строка даты: «22-12-2025 14:35:50»
- Формат: «%d-%m-%Y %H:%M:%S»
- Код: datetime.strptime(«22-12-2025 14:35:50», «%d-%m-%Y %H:%M:%S»)
- Результат: объект datetime.datetime(2025, 12, 22, 14, 35, 50)
Советы при использовании strptime:
- Всегда проверяйте формат входной строки перед конвертацией, чтобы избежать ValueError.
- Для разных разделителей (точка, слэш, дефис) задавайте соответствующий шаблон.
- При отсутствии времени используйте шаблон только с датой, например %d-%m-%Y.
- Для массовой обработки данных применяйте цикл или генератор, чтобы преобразовывать списки строк в объекты datetime.
Преобразование ISO 8601 строк в datetime

Стандарт ISO 8601 представляет даты в виде YYYY-MM-DD или с временем YYYY-MM-DDTHH:MM:SS. Python поддерживает его напрямую через метод fromisoformat в модуле datetime.
Пример конвертации даты и времени:
- Строка: «2025-12-22T14:35:50»
- Код: datetime.fromisoformat(«2025-12-22T14:35:50»)
- Результат: объект datetime.datetime(2025, 12, 22, 14, 35, 50)
Для строк с часовым поясом, например «2025-12-22T14:35:50+03:00», fromisoformat корректно создаст объект с атрибутом tzinfo. При использовании strptime потребуется вручную задать формат %Y-%m-%dT%H:%M:%S%z.
Рекомендации:
- Использовать fromisoformat для прямого парсинга ISO 8601 без дополнительных проверок.
- Проверять наличие символа T между датой и временем, иначе fromisoformat может вернуть ошибку.
- Для обработки массивов данных ISO 8601 в pandas применяйте pd.to_datetime, который автоматически распознает формат и часовые пояса.
Обработка разных разделителей в датах
Строки с датами могут содержать различные разделители: дефис, слэш, точку или пробел. Метод datetime.strptime требует точного соответствия шаблону, поэтому формат должен учитывать используемый разделитель.
Примеры корректного парсинга:
- Дефис: «22-12-2025» → datetime.strptime(«22-12-2025», «%d-%m-%Y»)
- Слэш: «22/12/2025» → datetime.strptime(«22/12/2025», «%d/%m/%Y»)
- Точка: «22.12.2025» → datetime.strptime(«22.12.2025», «%d.%m.%Y»)
Рекомендации для работы с разными разделителями:
- Перед преобразованием стандартизируйте строки, заменяя все варианты разделителей на один единый символ.
- При работе с большим набором данных используйте регулярные выражения для выявления формата даты и выбора подходящего шаблона.
- Для смешанных форматов столбцов в pandas применяется pd.to_datetime(errors=’coerce’), чтобы некорректные строки автоматически становились NaT.
Парсинг даты с временем и часовым поясом
Строки с датой, временем и часовым поясом требуют точного шаблона при использовании datetime.strptime. Формат времени с зоной указывается через %z, например: «2025-12-22 14:35:50+0300» с шаблоном «%Y-%m-%d %H:%M:%S%z».
Пример конвертации:
- Строка: «2025-12-22 14:35:50+0300»
- Код: datetime.strptime(«2025-12-22 14:35:50+0300», «%Y-%m-%d %H:%M:%S%z»)
- Результат: объект datetime.datetime(2025, 12, 22, 14, 35, 50, tzinfo=datetime.timezone(datetime.timedelta(hours=3)))
При работе с Python 3.9+ можно использовать zoneinfo для указания именованных часовых поясов:
- Импорт: from zoneinfo import ZoneInfo
- Создание объекта с часовой зоной: datetime(2025, 12, 22, 14, 35, tzinfo=ZoneInfo(«Europe/Moscow»))
Рекомендации:
- Для строк с разными часовыми поясами стандартизируйте формат с помощью %z или используйте zoneinfo для именованных зон.
- При массовой обработке данных pandas корректно распознает строки с часовыми поясами через pd.to_datetime.
- Не обрезайте символы зоны времени в строках, иначе объекты будут создаваться без tzinfo и вычисления времени станут некорректными.
Преобразование строк с сокращёнными месяцами
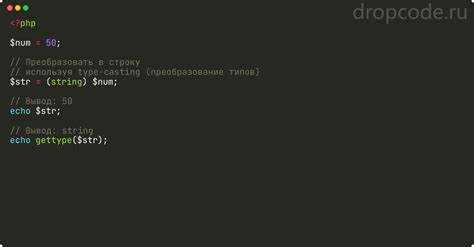
В строках дат сокращённые названия месяцев чаще всего встречаются в формате Jan, Feb, Mar и аналогах. В стандартной библиотеке Python они обрабатываются через форматный код %b функции datetime.strptime(). Этот код ожидает именно сокращённое название месяца, а не числовое значение.
Пример разбора строки с английским сокращением месяца:
from datetime import datetime
dt = datetime.strptime("12 Feb 2024", "%d %b %Y")
Важно учитывать локаль. По умолчанию Python использует системную локаль, поэтому %b корректно работает только с тем языком, который задан в окружении. Для английских месяцев на системе с другой локалью потребуется явная установка:
import locale
locale.setlocale(locale.LC_TIME, "en_US.UTF-8")
Без корректной локали разбор строки вида «12 Feb 2024» завершится ошибкой ValueError. Это особенно актуально для серверов и контейнеров, где локаль часто отличается от ожидаемой.
Если строка содержит нестандартные или смешанные сокращения месяцев (например, Jan., Sept, Mär), удобнее использовать словарь соответствий и предварительную замену:
months = {"Jan": "01", "Feb": "02", "Mar": "03"}
date_str = "12 Feb 2024"
for k, v in months.items():
date_str = date_str.replace(k, v)
dt = datetime.strptime(date_str, "%d %m %Y")
Такой подход избавляет от зависимости от локали и позволяет контролировать поддерживаемые варианты сокращений.
Альтернативный вариант – использование библиотеки dateutil. Функция parser.parse() корректно распознаёт большинство сокращённых месяцев без настройки локали:
from dateutil import parser
dt = parser.parse("12 Feb 2024")
Этот способ удобен при обработке данных из внешних источников, но менее строгий и может допускать неоднозначные интерпретации формата.
Для предсказуемого результата в критичных сценариях предпочтительно использовать datetime.strptime() с явным форматом и контролируемым набором допустимых сокращений месяцев.
Использование pandas для массового преобразования столбцов

Для преобразования строк в datetime в табличных данных pandas предоставляет функцию to_datetime(), оптимизированную для работы с большими объёмами. Она применяется сразу к целому столбцу Series или к нескольким столбцам DataFrame.
Базовый вариант преобразования одного столбца:
df["created_at"] = pd.to_datetime(df["created_at"])
При известном формате рекомендуется указывать параметр format. Это снижает нагрузку и ускоряет обработку:
df["created_at"] = pd.to_datetime(df["created_at"], format="%Y-%m-%d %H:%M:%S")
Для массового преобразования нескольких столбцов используется цикл или метод apply:
cols = ["created_at", "updated_at", "deleted_at"]
df[cols] = df[cols].apply(pd.to_datetime)
При наличии ошибочных значений применяется параметр errors=»coerce», который заменяет некорректные строки на NaT:
df["created_at"] = pd.to_datetime(df["created_at"], errors="coerce")
Это позволяет избежать исключений при обработке данных из CSV, логов или API.
Для дат, разделённых по разным столбцам, используется параметр unit или объединение полей:
df["event_time"] = pd.to_datetime(df[["year", "month", "day"]])
Если источник содержит Unix-время, указывается единица измерения:
df["ts"] = pd.to_datetime(df["ts"], unit="s")
При обработке временных зон параметр utc=True приводит все значения к UTC:
df["created_at"] = pd.to_datetime(df["created_at"], utc=True)
Основные параметры to_datetime() и их влияние:
| Параметр | Назначение | Практический эффект |
|---|---|---|
| format | Явный формат даты | Ускоряет разбор и снижает риск ошибки |
| errors | Обработка некорректных значений | Позволяет продолжить загрузку данных |
| unit | Единица Unix-времени | Корректный разбор числовых меток |
| utc | Приведение к UTC | Упрощает работу с часовыми поясами |
Для больших наборов данных предпочтительно заранее нормализовать формат строк и избегать автоматического определения формата, так как оно существенно увеличивает время выполнения.
Обработка ошибок при некорректном формате даты
При разборе строк в datetime основная проблема – несоответствие формата ожидаемому шаблону. В стандартной библиотеке Python функция datetime.strptime() при ошибке всегда выбрасывает ValueError, поэтому преобразование следует изолировать.
Минимальный вариант с перехватом исключения:
from datetime import datetime
try:
dt = datetime.strptime(date_str, "%Y-%m-%d")
except ValueError:
dt = None
Такой подход удобен для единичных значений, но плохо масштабируется при обработке массивов данных.
Для массовых операций в pandas предпочтительнее использовать параметр errors=»coerce». Некорректные строки автоматически преобразуются в NaT без остановки выполнения:
df["created_at"] = pd.to_datetime(df["created_at"], errors="coerce")
После этого NaT легко выявляются через isna() и могут быть отфильтрованы или заменены:
invalid = df["created_at"].isna()
При строгих требованиях к формату рекомендуется предварительная проверка строки с помощью регулярных выражений. Это позволяет отсеять заведомо неверные значения до вызова преобразования:
import re
pattern = r"^\d{4}-\d{2}-\d{2}$"
if re.match(pattern, date_str):
dt = datetime.strptime(date_str, "%Y-%m-%d")
Отдельный класс ошибок связан с диапазонами значений. Дата может соответствовать формату, но быть некорректной логически, например 2024-02-30. Такие случаи не отлавливаются регулярными выражениями и выявляются только при разборе.
Для входных данных с несколькими возможными форматами допустимо поочерёдное применение шаблонов:
formats = ["%Y-%m-%d", "%d.%m.%Y"]
dt = None
for fmt in formats:
try:
dt = datetime.strptime(date_str, fmt)
break
except ValueError:
pass
Этот метод даёт контроль над допустимыми форматами и позволяет избежать некорректных автоматических интерпретаций.
Для отладки полезно логировать исходные строки, которые не удалось преобразовать. Это упрощает анализ источника данных и корректировку правил разбора.
Преобразование строк с нестандартными шаблонами
Нестандартные шаблоны дат встречаются в логах, экспортированных отчётах и пользовательском вводе. К ним относятся комбинированные форматы, нестабильные разделители и встроенные текстовые фрагменты.
При наличии фиксированной структуры рекомендуется описывать формат максимально точно через strptime(). Пример строки с текстовой вставкой:
from datetime import datetime
dt = datetime.strptime("2024|03|15[14:32]", "%Y|%m|%d[%H:%M]")
Если формат частично меняется, сначала выполняется нормализация строки. Типовые приёмы:
- замена нестандартных разделителей на стандартные символы
- удаление служебных слов и суффиксов
- приведение чисел к фиксированной длине
Пример предварительной обработки:
raw = "15-3-2024 time=9:05"
clean = raw.replace("time=", "").replace("-", ".")
dt = datetime.strptime(clean, "%d.%m.%Y %H:%M")
Для строк с переменным порядком компонентов применяется разбор по частям с последующей сборкой:
- извлечение числовых значений через регулярные выражения
- явное сопоставление позиции с годом, месяцем и днём
- создание объекта datetime через конструктор
import re
y, m, d = map(int, re.findall(r"\d+", "year=2024;day=15;month=3"))
dt = datetime(y, m, d)
Если строка содержит нестандартные обозначения месяцев или дней недели, используется словарь соответствий с заменой перед разбором:
- локальные сокращения месяцев
- числовые коды вместо названий
- комбинированные обозначения даты и версии
Для массовой обработки в pandas логика нормализации выносится в отдельную функцию и применяется к столбцу через apply(), после чего вызывается to_datetime() с явным форматом.
Автоматический разбор без указания шаблона допустим только при анализе входных данных. В рабочем коде предпочтительна явная фиксация всех шагов преобразования, чтобы исключить неоднозначную интерпретацию даты.
Вопрос-ответ:
Почему datetime.strptime() не принимает строку, которая выглядит корректно
Чаще всего причина — несовпадение формата. strptime() требует полного соответствия шаблону: порядок элементов, разделители и ведущие нули имеют значение. Например, строка «2024-3-7» не будет разобрана форматом «%Y-%m-%d». В таких случаях нужно либо изменить шаблон, либо предварительно нормализовать строку, приведя месяц и день к двум цифрам.
Как разобрать дату, если формат заранее неизвестен
При отсутствии фиксированного формата допустимо использовать dateutil.parser.parse(). Он пытается определить структуру автоматически и поддерживает разные варианты записи. Однако результат может быть неоднозначным, особенно при формате вроде «01/02/2024». Для стабильного кода лучше сначала определить допустимые форматы и проверять их последовательно.
Что делать, если в данных встречаются ошибки и пустые значения
Для одиночных значений используется try/except с обработкой ValueError. При работе с таблицами pandas предпочтительно применять pd.to_datetime() с параметром errors=»coerce». Все некорректные строки будут заменены на NaT, после чего их можно выявить через isna() и обработать отдельно.
Как ускорить преобразование большого столбца дат в pandas
Наиболее заметный прирост скорости даёт указание параметра format в pd.to_datetime(). Это отключает автоматический анализ строки. Также стоит избегать apply() с пользовательскими функциями, если задача решается стандартными средствами pandas. Для Unix-времени обязательно указывать unit, иначе разбор займёт больше времени.
Как корректно работать с датами и часовыми поясами при разборе строк
Если входные строки не содержат информации о часовом поясе, их лучше сразу приводить к UTC через параметр utc=True в pd.to_datetime(). При наличии смещения в строке оно будет учтено автоматически. Для стандартной библиотеки после разбора применяется метод replace(tzinfo=…) или astimezone(), чтобы явно зафиксировать временную зону.
Почему pd.to_datetime() иногда меняет день и месяц местами
Такое поведение возникает при разборе строк без явного формата, например «03/04/2024». pandas пытается определить структуру автоматически и может трактовать её как MM/DD/YYYY или DD/MM/YYYY. Чтобы избежать этого, нужно всегда задавать параметр format либо использовать dayfirst=True. Фиксация формата полностью исключает неоднозначность и даёт предсказуемый результат при обработке данных.