Содержание статьи

Парсер HTML на PHP требуется, когда данные недоступны через API или выгрузки. Типичные задачи – сбор карточек товаров, цен, ссылок, описаний, таблиц и метаданных со страниц сайтов. В PHP для этого применяются стандартные расширения и библиотеки, позволяющие работать напрямую с разметкой, без сторонних сервисов и лишних зависимостей.
Основа разбора HTML – связка DOMDocument и DOMXPath. DOMDocument загружает HTML и строит дерево узлов, а XPath позволяет выбирать элементы по тегам, атрибутам и вложенности. Такой подход подходит для страниц с любым уровнем сложности и не зависит от форматирования исходного кода, отступов или переносов строк.
Перед разбором HTML требуется корректно получить исходный код страницы. На практике используют cURL для работы с заголовками, cookies и редиректами, либо file_get_contents для простых запросов. Неправильная кодировка, сжатие или ошибки сервера напрямую влияют на результат парсинга, поэтому этап загрузки данных нельзя пропускать.
Результат парсинга обычно приводят к структурам, удобным для хранения и обработки: массивам, JSON или записям в базе данных. На этом этапе выполняют очистку текста, удаление HTML-тегов, нормализацию чисел и проверку на дубли. Такой подход позволяет использовать собранные данные в каталогах, отчетах, мониторинге цен и автоматизированных обновлениях контента.
Выбор библиотеки PHP для загрузки и обработки HTML

Для загрузки HTML в PHP чаще всего применяют cURL и file_get_contents. file_get_contents подходит для простых запросов без авторизации и сложных заголовков, но не дает контроля над тайм-аутами, прокси и cookies. cURL позволяет задавать User-Agent, обрабатывать редиректы, сохранять сессионные данные и работать с HTTPS без ограничений, что делает его основным инструментом для парсеров.
Разбор HTML на уровне структуры выполняется стандартным расширением DOM, входящим в PHP по умолчанию. DOMDocument загружает HTML и формирует дерево узлов, а DOMXPath обеспечивает точечный доступ к элементам по тегам, классам, атрибутам и иерархии. Такой подход устойчив к изменению форматирования и не зависит от порядка атрибутов в тегах.
Для упрощения работы с DOM применяют обертки над стандартными классами. Symfony DomCrawler добавляет удобный CSS-селекторный синтаксис и методы фильтрации, но требует установки через Composer. Он удобен при массовом извлечении однотипных блоков, например карточек товаров или строк таблиц.
Библиотека simple_html_dom предлагает минимальный порог входа и синтаксис, похожий на jQuery, однако она потребляет больше памяти и плохо справляется с большими документами. Ее используют в небольших скриптах, где объем HTML ограничен и не требуется высокая стабильность.
При выборе инструмента важно учитывать объем обрабатываемых страниц, частоту запросов и требования к точности выборки. Для долгоживущих проектов с большим количеством источников оптимальной связкой остается cURL для загрузки и DOMDocument + DOMXPath для разбора, без лишних зависимостей и потерь контроля над процессом.
Получение HTML кода страницы через cURL и file_get_contents

Перед разбором HTML требуется получить исходный код страницы без искажений. В PHP для этого применяют file_get_contents и cURL. Выбор метода зависит от наличия редиректов, защиты по User-Agent, cookies и требований к сетевым параметрам.
file_get_contents выполняет HTTP-запрос одной строкой кода и подходит для страниц без авторизации и сложных заголовков. Для работы с HTTPS требуется включенная директива allow_url_fopen. Заголовки можно передать через контекст потока, но управление процессом загрузки остается ограниченным.
cURL дает полный контроль над запросом. Через опции задают User-Agent, Accept-Language, тайм-ауты, автоматическую обработку редиректов, cookies и прокси. Это позволяет получать HTML с сайтов, которые блокируют запросы без браузерных заголовков или возвращают пустой контент.
| Критерий | file_get_contents | cURL |
|---|---|---|
| Поддержка редиректов | Ограниченная | Полная |
| Настройка заголовков | Через контекст | Через набор опций |
| Работа с cookies | Нет | Да |
| Контроль тайм-аутов | Минимальный | Гибкий |
| Подходит для защищенных сайтов | Редко | Да |
Для парсеров, которые работают с одним источником без ограничений, допустимо использовать file_get_contents. Во всех остальных случаях предпочтение отдают cURL, так как он позволяет воспроизвести поведение браузера и стабильно получать HTML-код для последующего разбора.
Разбор структуры документа с помощью DOMDocument

DOMDocument – стандартный класс PHP для разбора HTML и XML, доступный без установки дополнительных расширений. Он преобразует строку HTML в дерево узлов, где каждый тег, атрибут и текстовый блок представлен отдельным объектом. Такой формат удобен для точечного извлечения данных и анализа вложенности элементов.
Перед загрузкой HTML в DOMDocument следует явно указать кодировку. Частая практика – добавлять префикс <?xml encoding=»UTF-8″?> к исходному коду страницы. Это предотвращает искажение символов и ошибки при работе с кириллицей, спецсимволами и невалидными метатегами charset.
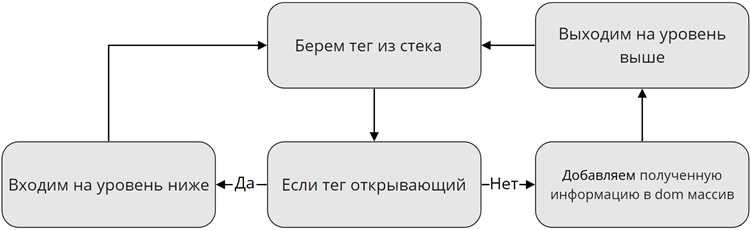
Реальная HTML-разметка редко соответствует стандартам. Незакрытые теги, дублирующиеся атрибуты и нарушенная вложенность вызывают предупреждения. Для стабильного разбора используют подавление ошибок через libxml_use_internal_errors(true), после чего документ загружается методом loadHTML без прерывания выполнения скрипта.
После построения DOM-дерева доступ к элементам осуществляется через методы getElementsByTagName или совместно с DOMXPath. Прямой перебор тегов удобен для простых структур, а XPath-запросы позволяют выбирать узлы по атрибутам, классам и относительному положению, не привязываясь к жесткой иерархии.
При работе с большими страницами важно учитывать потребление памяти. DOMDocument загружает весь HTML целиком, поэтому для объемных документов стоит очищать неиспользуемые переменные и избегать повторной загрузки одного и того же кода. Это снижает риск переполнения памяти и ускоряет обработку данных.
Поиск и извлечение элементов через XPath запросы
XPath используется совместно с DOMXPath для точного выбора элементов в DOM-дереве. Он работает поверх структуры документа, а не исходного HTML-кода, поэтому не зависит от переносов строк и форматирования. Запросы описывают путь к узлам и условия отбора по тегам, атрибутам и вложенности.
На практике XPath применяют для извлечения повторяющихся блоков и отдельных значений. Основные шаблоны запросов выглядят следующим образом:
- Выбор всех элементов по тегу: //a
- Фильтрация по атрибуту: //div[@class=»price»]
- Поиск вложенных элементов: //ul/li/span
- Частичное совпадение атрибута: //img[contains(@src,».jpg»)]
При извлечении данных важно учитывать, что XPath возвращает коллекцию узлов. Даже если ожидается один элемент, результат следует обрабатывать как список. Для получения текста используют свойство nodeValue, а для атрибутов – метод getAttribute.
Для сложных страниц удобно строить запросы относительно найденного узла. Это снижает зависимость от изменений разметки и уменьшает длину выражений. Например, сначала выбирают контейнер карточки товара, а затем извлекают цену, название и ссылку внутри него.
- Найти список контейнеров: //div[@data-id]
- Для каждого контейнера выполнить относительный запрос: .//span[@class=»title»]
- Извлечь значения и привести их к нужному формату
XPath не поддерживает CSS-псевдоклассы и вычисления стилей, поэтому выбор элементов основывается только на структуре и атрибутах. Для устойчивого парсинга стоит избегать привязки к позициям и индексам, используя условия по классам, data-атрибутам и текстовому содержимому.
Обработка атрибутов тегов и текстового содержимого
После выбора узлов через XPath данные извлекают из атрибутов и текстовых значений. Для работы с атрибутами используют метод getAttribute, который возвращает строку без HTML-экранирования. Перед сохранением значений стоит проверять их наличие, так как отсутствующий атрибут возвращает пустую строку и может привести к логическим ошибкам.
Часто обрабатываемые атрибуты – href, src, title, data-*. Относительные ссылки требуется приводить к абсолютному виду, добавляя схему и домен исходной страницы. Для изображений и файлов полезно удалять параметры запроса, если они не участвуют в идентификации ресурса.
Текстовое содержимое узлов доступно через свойство nodeValue. Оно возвращает текст вместе с пробелами и переводами строк, поэтому перед использованием данные очищают функциями trim и preg_replace. Если элемент содержит вложенные теги, nodeValue объединяет весь текст без разделения на части.
Для точной обработки текста важно учитывать кодировку документа. После загрузки HTML в DOMDocument все строки должны находиться в UTF-8. При необходимости применяют html_entity_decode для преобразования HTML-сущностей в обычные символы.
Перед записью результатов парсинга выполняют нормализацию данных: удаляют лишние пробелы, приводят числовые значения к стандартному формату, заменяют нестандартные символы. Это упрощает последующую обработку, поиск и сравнение данных, полученных с разных страниц.
Работа с некорректной версткой и подавление ошибок парсинга
Для безопасного разбора используют следующие подходы:
- Очистка предыдущих ошибок: libxml_clear_errors() перед загрузкой нового документа
- Явное указание кодировки при загрузке: <?xml encoding=»UTF-8″?>
Для работы с частично поврежденной версткой применяют пошаговый разбор:
- Сначала загружают документ в DOMDocument с подавлением ошибок
- Удаляют ненужные скрипты и стили через XPath: //script | //style
- Проверяют наличие ключевых элементов перед извлечением данных
- При отсутствии узла используют значения по умолчанию или пропускают элемент
Такой подход позволяет получать корректное DOM-дерево даже с некорректной версткой и снижает вероятность пустых или неправильных данных при парсинге.
Фильтрация и очистка данных после разбора HTML
Основные операции по очистке данных включают:
- Удаление HTML-тегов с помощью strip_tags
- Преобразование HTML-сущностей через html_entity_decode
- Удаление лишних пробелов, переводов строк и табуляций с помощью trim и регулярных выражений
- Нормализация числовых значений: замена запятой на точку, удаление нечисловых символов
- Фильтрация ссылок и изображений по формату или домену для исключения рекламных и внешних ресурсов
Для массивов данных рекомендуется применять функции фильтрации через array_filter и array_map, чтобы сразу отбросить пустые или некорректные элементы. Это упрощает дальнейшую обработку, сравнение и сохранение информации.
Фильтрация и очистка делают данные пригодными для анализа, сохранения в базу или экспорта, снижая вероятность ошибок при последующем использовании и повышая точность парсинга.
Сохранение результатов парсинга в массивы и базу данных
Для постоянного хранения применяют базы данных. Наиболее распространены MySQL, PostgreSQL и SQLite. При вставке данных используют подготовленные запросы через PDO или MySQLi, чтобы избежать SQL-инъекций и корректно обрабатывать спецсимволы.
Рекомендации по организации сохранения:
- Создавать таблицы с отдельными колонками под ключевые поля
- Использовать уникальные индексы для предотвращения дублирования
- Нормализовать числовые и текстовые значения перед вставкой
- Применять транзакции при массовой вставке, чтобы сохранить целостность данных
- Для больших объемов парсинга сохранять промежуточные результаты в массивы и записывать их пакетами
Такой подход обеспечивает быстрый доступ к данным, простоту их анализа и возможность автоматического обновления информации с сайтов без потери целостности и точности.
Вопрос-ответ:
Какие инструменты PHP подходят для загрузки HTML перед парсингом?
Для получения HTML используют cURL и file_get_contents. file_get_contents подходит для простых страниц без авторизации и редиректов, тогда как cURL позволяет задавать заголовки, обрабатывать cookies, редиректы и работать с HTTPS. Для сайтов с защитой и динамическими перенаправлениями предпочтительнее использовать cURL.
Как правильно использовать DOMDocument для разбора HTML с ошибками верстки?
DOMDocument строит дерево узлов даже на некорректной HTML-разметке, но для подавления предупреждений применяют libxml_use_internal_errors(true). После загрузки документа рекомендуется очищать ошибки через libxml_clear_errors(). Для стабильной работы стоит указывать кодировку документа и использовать опции LIBXML_HTML_NOIMPLIED и LIBXML_HTML_NODEFDTD при необходимости исключения автоматически добавленных тегов и
.Какие XPath-запросы лучше применять для извлечения данных из сложных страниц?
Для точного выбора элементов используют условия по тегам, классам, атрибутам и вложенности. Примеры запросов: //div[@class=»price»] для блока с ценой, //img[contains(@src,».jpg»)] для изображений, .//span[@class=»title»] относительно контейнера. Относительные запросы внутри найденных блоков снижают зависимость от структуры и упрощают обновление парсера при изменении верстки.
Как обрабатывать текст и атрибуты элементов после парсинга?
Текст узла извлекают через nodeValue, атрибуты — через getAttribute. Для правильной работы с кириллицей и спецсимволами применяют html_entity_decode и проверяют кодировку UTF-8. Перед сохранением данные очищают от лишних пробелов, переводов строк, нестандартных символов и нормализуют числовые значения.
Какие способы сохранения данных после парсинга наиболее удобны для последующей обработки?
Для временного хранения используют массивы, где каждый элемент представляет собой ассоциативный массив с полями: название, цена, ссылка, изображение. Для постоянного хранения применяют базы данных MySQL, PostgreSQL или SQLite. Используют подготовленные запросы через PDO или MySQLi, создают уникальные индексы для предотвращения дублирования и применяют транзакции при массовой вставке данных.