
Содержание статьи

В Python списки часто используются для хранения данных, которые могут повторяться. Например, список заказов клиентов может содержать одинаковые товары, а журнал посещений сайта – одинаковые IP-адреса. Выявление таких повторов помогает оптимизировать обработку данных, проводить анализ частоты и очищать коллекции от лишних элементов.
Для обнаружения дубликатов можно использовать встроенные структуры данных. Множества (set) позволяют быстро определить уникальные элементы, а модуль collections предлагает класс Counter для подсчета повторений. Эти подходы помогают сразу понять, какие элементы встречаются чаще всего и сколько раз они повторяются.
Выбор метода зависит от задачи: если важно сохранить порядок элементов, стоит применять списковые включения и условные проверки; если приоритет – только уникальность, достаточно операций с множеством. Практическая работа с небольшими списками до 10 000 элементов обычно не требует сложной оптимизации, но для больших данных полезно учитывать сложность алгоритма и использование памяти.
Использование множества для выявления дубликатов
Множество (set) в Python хранит только уникальные элементы, что позволяет быстро выявлять дубликаты. Если преобразовать список в множество, повторяющиеся значения будут автоматически удалены. Например, для списка data = [1, 2, 2, 3, 4, 4, 4, 5] преобразование set(data) вернет {1, 2, 3, 4, 5}.
Для определения, какие элементы повторяются, можно сравнить длину исходного списка и множества: элементы, исчезнувшие при преобразовании, встречались более одного раза. В больших коллекциях до миллиона элементов операция set() выполняется за время O(n), что делает метод подходящим для первичной фильтрации повторов.
Если важно сохранить порядок оригинального списка, используют дополнительный проход: создают пустое множество для контроля уникальности и формируют новый список, добавляя элементы только при первом вхождении. Этот подход объединяет преимущества множества и сохранение последовательности элементов.
Множества также позволяют выполнять пересечения списков: set(list1) & set(list2) вернет только общие элементы, что удобно при анализе повторов между разными наборами данных.
Счетчики из модуля collections для подсчета повторов
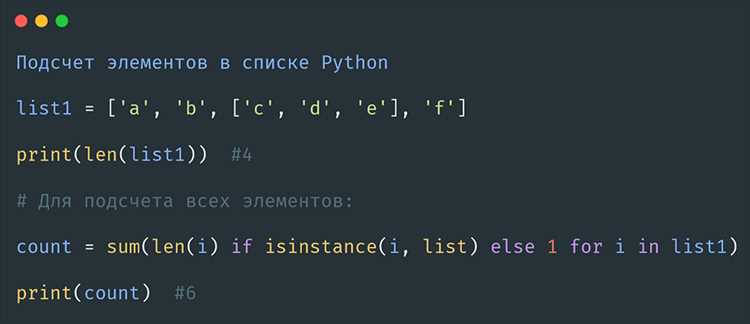
Класс Counter из модуля collections позволяет подсчитывать количество вхождений каждого элемента списка без необходимости ручного перебора. Для списка items = [‘apple’, ‘banana’, ‘apple’, ‘orange’, ‘banana’, ‘apple’] вызов Counter(items) вернет объект с парами элемент:количество.
Пример структуры данных в виде таблицы:
| Элемент | Количество |
|---|---|
| apple | 3 |
| banana | 2 |
| orange | 1 |
Методы most_common(n) позволяют получить n наиболее часто встречающихся элементов, а прямой доступ к ключам через индексацию возвращает количество повторов. Для фильтрации повторяющихся элементов достаточно оставить только элементы с количеством больше одного: [item for item, count in Counter(items).items() if count > 1].
Counter сохраняет порядок первого появления элементов в Python 3.7+, что упрощает анализ списков, где важна последовательность данных. Для больших списков класс подходит для агрегирования повторов с минимальными затратами кода и памяти.
Списковые включения для фильтрации повторяющихся элементов

Списковые включения позволяют создавать новый список с элементами, удовлетворяющими определенному условию, в одной строке кода. Для удаления повторов можно использовать вспомогательное множество для контроля уникальности. Например, seen = set(); result = [x for x in data if not (x in seen or seen.add(x))] формирует список result с первыми вхождениями каждого элемента, сохраняя порядок.
Этот метод подходит, когда нужно одновременно фильтровать повторяющиеся значения и обрабатывать элементы. Например, список data = [5, 3, 5, 2, 3, 4] после фильтрации через списковое включение с множеством даст [5, 3, 2, 4].
Списковые включения эффективны для списков средней длины до десятков тысяч элементов. Для больших коллекций следует учитывать, что операция x in seen выполняется за O(1), но создание нового списка и добавление в множество требует памяти пропорционально числу уникальных элементов.
Также их можно комбинировать с условиями для выделения только повторяющихся элементов: [x for x, y in Counter(data).items() if y > 1], что позволяет сразу получить элементы, встречающиеся более одного раза.
Сравнение элементов с помощью циклов и условий
Для выявления повторов можно использовать вложенные циклы, сравнивая каждый элемент списка с остальными. Например, для списка data = [1, 2, 3, 2, 4, 1] внешний цикл перебирает элементы, а внутренний проверяет, встречается ли текущий элемент дальше в списке. При совпадении элемент добавляется в отдельный список повторов.
Пример кода: duplicates = []; for i in range(len(data)): for j in range(i + 1, len(data)): if data[i] == data[j] and data[i] not in duplicates: duplicates.append(data[i]). В результате duplicates будет [1, 2].
Этот метод подходит для небольших списков до нескольких сотен элементов, так как сложность O(n²) растет быстро с увеличением размера данных. Для ускорения проверки можно использовать вспомогательное множество для уже найденных повторов, чтобы исключить повторное добавление.
Циклы и условия позволяют одновременно учитывать дополнительные критерии, например, проверять только определенные типы данных или значения в заданном диапазоне, что делает метод гибким для кастомной фильтрации повторяющихся элементов.
Применение функции set.intersection для пересечения списков
Метод set.intersection позволяет быстро определить элементы, которые встречаются одновременно в нескольких списках. Для двух списков list1 = [1, 2, 3, 4] и list2 = [3, 4, 5, 6] выражение set(list1).intersection(list2) вернет {3, 4}.
Для проверки повторяющихся элементов между тремя и более списками можно использовать цепочку пересечений: set(list1).intersection(list2, list3). Метод сохраняет только уникальные значения, встречающиеся во всех наборах.
Применение intersection эффективно для анализа данных из разных источников, например, сравнения списков заказов разных магазинов или идентификаторов пользователей, чтобы быстро выделить общие элементы без необходимости писать сложные циклы.
Если требуется результат в виде списка с сохранением исходного порядка одного из списков, после пересечения множество можно преобразовать обратно в список и использовать фильтрацию по исходной последовательности: [x for x in list1 if x in set(list2)].
Удаление дубликатов и сохранение порядка элементов

Для удаления повторяющихся элементов из списка без потери исходного порядка удобно использовать множество для контроля уникальности и формировать новый список через цикл или списковое включение.
Пример подхода:
- Создать пустое множество seen.
- Перебирать элементы исходного списка.
- Добавлять элемент в новый список только если его нет в seen.
- Одновременно добавлять элемент в seen для контроля уникальности.
Реализация через списковое включение:
- seen = set()
- result = [x for x in data if not (x in seen or seen.add(x))]
Этот метод позволяет:
- Сохранять порядок элементов, как в исходном списке.
- Удалять дубликаты без изменения размера оригинального списка в памяти.
- Обрабатывать списки любых типов элементов, включая строки и числа.
Для больших списков стоит учитывать, что каждая проверка x in seen выполняется за O(1), а создание нового списка требует дополнительной памяти, пропорциональной числу уникальных элементов.
Вопрос-ответ:
Как с помощью множества выявить повторяющиеся элементы в списке Python?
Множество (set) хранит только уникальные значения, поэтому его можно использовать для обнаружения дубликатов. Для списка data = [1, 2, 2, 3] преобразование set(data) даст {1, 2, 3}. Чтобы определить, какие элементы повторяются, сравните исходный список и множество: элементы, исчезнувшие при преобразовании, встречались несколько раз. Для сохранения порядка используют дополнительное множество и формируют новый список через цикл или списковое включение, добавляя элемент только при первом вхождении.
Чем удобен Counter из модуля collections для подсчета повторов?
Класс Counter позволяет получить количество каждого элемента без ручного перебора. Например, для items = [‘apple’, ‘banana’, ‘apple’] вызов Counter(items) вернет {‘apple’: 2, ‘banana’: 1}. Можно использовать метод most_common(n), чтобы получить n самых часто встречающихся элементов, а также фильтровать повторяющиеся элементы через условие count > 1. Counter сохраняет порядок первого появления элементов в Python 3.7+, что удобно для анализа последовательностей.
Как фильтровать повторяющиеся элементы с помощью списковых включений?
Списковые включения позволяют формировать новый список с условием проверки уникальности. Создают пустое множество seen и добавляют элемент в новый список только если его нет в seen. Пример: seen = set(); result = [x for x in data if not (x in seen or seen.add(x))]. Для фильтрации только повторяющихся элементов можно использовать Counter: [x for x, y in Counter(data).items() if y > 1]. Этот подход сохраняет порядок и подходит для средних по размеру списков.
Когда лучше использовать циклы и условия для поиска повторов?
Циклы и условия подходят для небольших списков, когда важно проверять дополнительные условия или фильтровать элементы по типу или диапазону. Пример: два вложенных цикла перебирают элементы и сравнивают их друг с другом, а найденные повторы добавляются в отдельный список. Сложность такого метода O(n²), поэтому его применяют для списков до нескольких сотен элементов. Вспомогательное множество помогает исключить повторное добавление дубликатов.
Как использовать set.intersection для поиска общих элементов между списками?
Метод set.intersection позволяет получить уникальные значения, встречающиеся во всех списках. Для list1 = [1, 2, 3] и list2 = [2, 3, 4] выражение set(list1).intersection(list2) вернет {2, 3}. Для нескольких списков можно указать их через запятую: set(list1).intersection(list2, list3). Если нужно сохранить порядок элементов одного из списков, после пересечения множество преобразуют в список и фильтруют по исходной последовательности: [x for x in list1 if x in set(list2)].
Как удалить дубликаты из списка Python, сохранив порядок элементов?
Чтобы удалить повторяющиеся элементы и сохранить исходный порядок, создают пустое множество для контроля уникальности и новый список для результата. При обходе исходного списка каждый элемент проверяют: если его нет в множестве, добавляют в результат и одновременно в множество. Пример: seen = set(); result = [x for x in data if not (x in seen or seen.add(x))]. Такой способ подходит для списков разных типов данных и сохраняет последовательность первых вхождений каждого элемента.
Можно ли с помощью Python определить, какие элементы встречаются одновременно в нескольких списках?
Да, для этого используется метод set.intersection. Он возвращает множество элементов, присутствующих во всех указанных списках. Например, для list1 = [1, 2, 3] и list2 = [2, 3, 4] выражение set(list1).intersection(list2) даст {2, 3}. Для нескольких списков их передают через запятую: set(list1).intersection(list2, list3). Если нужно сохранить порядок элементов одного из списков, после пересечения можно фильтровать исходный список по множеству пересечения: [x for x in list1 if x in set(list2)].





