Содержание статьи

На практике /dev/urandom применяется для генерации паролей, токенов сессий, UUID, ключевых файлов и случайных заполнителей. Например, чтение 32 байтов (256 бит) считается достаточным для большинства токенов доступа. Для этого используются стандартные инструменты командной строки, что позволяет обойтись без внешних библиотек и сторонних утилит.
При работе с /dev/urandom стоит учитывать, что это символьное устройство, а не файл с фиксированным размером. Чтение данных без ограничения объема приведет к бесконечному потоку. Поэтому всегда задают точное количество байтов с помощью head, dd или параметров чтения в скриптах. Такой подход снижает риск зависаний и избыточного потребления ресурсов.
В современных ядрах Linux генератор, лежащий в основе /dev/urandom, инициализируется на раннем этапе загрузки. Это позволяет безопасно применять его сразу после старта системы, включая серверные и контейнерные окружения. При разработке скриптов и сервисов рекомендуется явно документировать места использования /dev/urandom, чтобы избежать подмены источника случайных данных и ошибок при переносе конфигураций.
Разница между /dev/urandom и /dev/random при генерации случайных данных

Оба устройства используют один и тот же пул энтропии ядра Linux, однако их поведение при чтении данных принципиально отличается. Это влияет на выбор источника случайных байтов в системных утилитах, скриптах и сервисах.
/dev/random контролирует уровень доступной энтропии. Если ядро считает, что ее недостаточно, чтение блокируется до поступления новых шумовых событий. Такое поведение напрямую связано с параметром entropy_avail, который можно проверить через /proc/sys/kernel/random/entropy_avail.
/dev/urandom не останавливает чтение при снижении энтропии. После начальной инициализации генератора данные продолжают выдаваться на основе криптографического PRNG, обновляемого по мере поступления новых источников шума.
- /dev/random подходит для сценариев, где допустимы задержки и требуется строгая привязка к текущему уровню энтропии
- /dev/urandom используется для сетевых сервисов, генерации токенов, ключевых файлов и автоматизации
- Оба устройства выдают байты одинакового формата без маркеров конца потока
Начиная с ядер Linux 5.6, криптографическая подсистема была переработана: инициализация генератора происходит раньше, а различия в качестве данных между устройствами были сведены к минимуму. На современных системах /dev/urandom считается безопасным для большинства криптографических задач, включая генерацию ключей.
Рекомендации для выбора источника:
- Для серверов, контейнеров и CI-систем используйте /dev/urandom во избежание блокировок
- Для редких операций, выполняемых вручную и допускающих ожидание, допустимо применение /dev/random
- Не смешивайте оба источника в одном процессе без явной причины
В пользовательских приложениях и скриптах предпочтительно явно указывать выбранное устройство, а не полагаться на значения по умолчанию сторонних инструментов.
Чтение байтов из /dev/urandom с помощью cat, head и dd
Для простых задач чаще используют head. Опция -c указывает точное число байтов, после чего процесс завершается без побочных эффектов.
Утилита dd дает полный контроль над размером блоков и общим объемом данных. Это удобно при записи в файл, на устройство или при тестировании пропускной способности.
| Команда | Пример | Назначение |
|---|---|---|
| cat | cat /dev/urandom | head -c 16 | Чтение через конвейер с внешним ограничением |
| head | head -c 32 /dev/urandom | Получение фиксированного числа байтов |
| dd | dd if=/dev/urandom of=key.bin bs=1 count=64 | Запись данных с заданным размером блока |
При использовании dd стоит учитывать, что параметр bs влияет на количество системных вызовов. Для небольших объемов обычно задают bs=1 и управляют итоговым размером через count, чтобы получить точное число байтов без округлений.
Создание паролей и токенов из /dev/urandom через стандартные утилиты
/dev/urandom часто применяют как источник байтов для генерации паролей и токенов, которые не должны повторяться и подбираться перебором. На практике результат почти всегда требуется привести к ограниченному набору символов или фиксированному формату.
Для текстовых паролей используют связку tr и head, отбрасывая все символы, кроме допустимых. Пример получения строки длиной 20 символов из латиницы и цифр: tr -dc ‘A-Za-z0-9’ < /dev/urandom | head -c 20. Такой подход подходит для учетных записей, где запрещены спецсимволы.
Токены для API и сессий чаще формируют в кодировке base64 или hex. Это снижает риск проблем при передаче через HTTP-заголовки и URL. Для base64 достаточно считать 32 байта и закодировать их: head -c 32 /dev/urandom | base64. Итоговая строка содержит 43–44 символа.
Для шестнадцатеричного формата применяют hexdump или xxd. Пример генерации 64-символьного токена: head -c 32 /dev/urandom | hexdump -v -e ‘/1 «%02x»‘. Такой формат удобен для конфигурационных файлов и журналирования.
Рекомендуемые размеры:
– не менее 16 байтов для временных паролей
– 32 байта для токенов доступа и ключей API
– 64 байта для долгоживущих секретов
Сгенерированные значения следует сразу сохранять или использовать в памяти процесса. Повторное чтение из /dev/urandom для проверки совпадений не имеет смысла, так как поток не детерминирован и не воспроизводим.
Использование /dev/urandom в bash-скриптах для случайных значений
В bash-скриптах /dev/urandom применяют вместо встроенной переменной $RANDOM, когда требуется получить непредсказуемые значения без привязки к состоянию оболочки. Чтение напрямую из устройства исключает повторяемость при параллельном запуске скриптов.
Для получения случайного целого числа часто читают несколько байтов и преобразуют их в десятичный вид. Пример: od -An -N4 -tu4 /dev/urandom возвращает 32-битное беззнаковое число, пригодное для идентификаторов и временных меток внутри сценариев.
Если значение должно попадать в заданный диапазон, результат нормализуют через арифметику bash. Типовой шаблон: чтение 4 байтов, затем применение операции % для ограничения диапазона, например от 0 до 9999. Это упрощает выбор случайных портов, имен файлов или индексов массивов.
Для генерации строк в скриптах используют фильтрацию потока. Конструкция tr -dc ‘a-z0-9’ < /dev/urandom | head -c 12 создает короткие идентификаторы, которые можно безопасно вставлять в пути, имена временных каталогов и переменные окружения.
При чтении из /dev/urandom в циклах рекомендуется ограничивать количество байтов за одну итерацию. Это снижает нагрузку на систему и упрощает отладку. Для повторного использования значений их сохраняют в переменные, а не перечитывают устройство несколько раз подряд.
В скриптах, запускаемых при старте системы или в контейнерах, стоит избегать любых проверок доступности энтропии. /dev/urandom доступен сразу, что позволяет выполнять генерацию без задержек и условной логики.
Применение /dev/urandom при создании криптографических ключей
/dev/urandom используется как источник начального материала при генерации симметричных и асимметричных ключей. Ядро Linux подает байты в криптографический PRNG, который далее применяется библиотеками OpenSSL, GnuTLS и инструментами вроде ssh-keygen.
Для симметричных ключей часто требуется фиксированный размер в байтах. Пример генерации 256-битного ключа для AES: head -c 32 /dev/urandom > aes.key. Полученный файл содержит ровно 32 байта и подходит для прямой загрузки в утилиты шифрования.
При создании ключей для OpenSSL можно явно указать источник случайных данных. Команда openssl rand -rand /dev/urandom 48 > secret.bin читает поток из устройства и формирует бинарный ключ без дополнительных преобразований.
Для SSH и GPG прямое чтение из /dev/urandom обычно не требуется, так как инструменты используют системный генератор. Однако при работе в минимальных окружениях или chroot-средах важно проверить, что устройство доступно и не подменено. Отсутствие /dev/urandom приводит к ошибкам и отказу генерации ключей.
Рекомендуемые размеры ключевого материала:
– 32 байта для AES-256
– 64 байта для HMAC-SHA512
– не менее 48 байт для секретов, используемых в KDF
Сгенерированные ключи следует хранить в бинарном виде без кодирования, если формат позволяет. Base64 и hex применяют только при необходимости передачи через текстовые интерфейсы. Права доступа к файлам с ключами задают сразу после создания, ограничивая чтение текущим пользователем.
Не рекомендуется комбинировать /dev/urandom с пользовательскими генераторами или ручным «усилением» случайности. Это усложняет аудит и может привести к снижению стойкости при ошибочной реализации.
Ограничение объема и скорости чтения данных из /dev/urandom
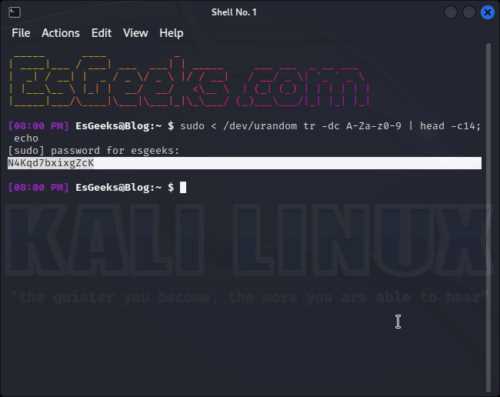
Поток из /dev/urandom бесконечный, поэтому контроль объема и скорости чтения необходим для предотвращения перегрузки системы и создания ненужной нагрузки на процессор.
Основные методы ограничения объема:
- Использование head -c для точного количества байтов: head -c 64 /dev/urandom вернет ровно 64 байта.
- Применение dd с параметрами bs и count: dd if=/dev/urandom of=file.bin bs=1 count=128.
- Конвейерная обработка через pipe и фильтры, ограничивающие поток, например tr или head.
Для контроля скорости чтения применяют:
- Утилиту pv с опцией —rate-limit для ограничения передачи байтов в секунду.
- Разделение чтения на блоки в цикле с паузами между итерациями через sleep.
- Использование буферов в dd с большим bs, чтобы уменьшить системные вызовы и стабилизировать нагрузку.
Рекомендации:
- Читать только необходимое количество байтов для конкретной задачи, не более нескольких сотен байтов за раз при скриптовой генерации.
- При непрерывной генерации токенов или паролей разбивать поток на блоки по 32–64 байта.
- Контролировать нагрузку на систему, особенно при одновременной работе нескольких процессов, использующих /dev/urandom.
Следуя этим правилам, можно безопасно использовать /dev/urandom без риска переполнения буферов или чрезмерного потребления ресурсов.
Типичные ошибки и риски безопасности при работе с /dev/urandom
Попытка смешивания /dev/urandom с самодельными генераторами случайных чисел снижает криптографическую стойкость. Любая непроверенная логика модификации потока может привести к повторяемым или коррелированным значениям.
Чтение слишком большого объема данных без ограничения создает высокую нагрузку на процессор и может приводить к блокировкам других сервисов. Использование cat /dev/urandom без фильтров или head – распространенная причина избыточного потребления ресурсов.
Передача бинарных данных напрямую в лог-файлы или терминал может раскрыть часть секретов или вызвать непредсказуемое поведение. Рекомендуется сразу использовать кодирование, например base64 или hexdump.
Риски при работе с правами доступа:
- Сохранение сгенерированных ключей или токенов в файлах с широкими правами чтения увеличивает вероятность компрометации.
- Работа в контейнерах без явного контроля /dev/urandom может позволить процессам изолированного окружения читать данные других приложений.
Рекомендации по снижению рисков:
- Использовать /dev/urandom только через стандартные утилиты и библиотеки, проверенные на безопасность.
- Ограничивать объем и частоту чтения байтов.
- Хранить секреты сразу в памяти или в защищенных файлах с минимальными правами доступа.
- Избегать ручного вмешательства в поток случайных данных.
Права доступа к /dev/urandom и работа в контейнерах
/dev/urandom представлен как символьное устройство с обычно установленными правами crw-rw-rw-, что позволяет всем пользователям читать данные. Запись в устройство не требуется и не используется в стандартных сценариях.
Для контейнеров важно проверять наличие /dev/urandom и его корректные права. В минимальных образах или chroot-окружениях устройство может отсутствовать, что приведет к сбоям при генерации ключей и токенов. В Docker и Podman /dev/urandom обычно монтируется автоматически из хоста, но стоит убедиться, что монтирование не ограничивает доступ.
Рекомендации при работе в контейнерах:
- Проверять наличие /dev/urandom на этапе запуска контейнера: test -r /dev/urandom.
- Не менять права на устройство внутри контейнера, чтобы не нарушить работу других процессов.
- При необходимости изолировать генерацию случайных чисел использовать отдельные процессы с ограниченными правами, а не изменять системное устройство.
- Для минимальных или специализированных образов создавать /dev/urandom через mknod с правами чтения для нужного пользователя.
Соблюдение этих правил гарантирует корректную генерацию случайных данных в контейнерах без риска нарушения безопасности и отказов приложений.
Вопрос-ответ:
В чем разница между /dev/random и /dev/urandom для генерации случайных данных?
/dev/random блокируется при недостатке энтропии, поэтому чтение больших объемов данных может задерживаться. /dev/urandom продолжает выдавать байты, используя криптографический генератор псевдослучайных чисел. Для большинства задач генерации токенов, ключей и паролей /dev/urandom безопасен и не вызывает задержек. /dev/random целесообразно применять только в ситуациях, когда важна абсолютная привязка к текущему уровню энтропии.
Как сгенерировать безопасный пароль длиной 16 символов через /dev/urandom?
Можно использовать команду tr -dc ‘A-Za-z0-9’ < /dev/urandom | head -c 16. Она читает поток байтов из /dev/urandom, отбрасывает все символы, кроме латинских букв и цифр, и выводит первые 16 символов. Такой метод подходит для учетных записей и временных паролей, не содержащих специальные символы.
Можно ли использовать /dev/urandom в контейнерах и как обеспечить доступ?
В Docker и Podman /dev/urandom обычно доступен автоматически, так как монтируется из хоста. В минимальных образах или chroot-окружениях устройство может отсутствовать, что вызывает сбои при генерации ключей. Если необходимо, /dev/urandom создают вручную через mknod с правами чтения для нужного пользователя. Изменять права на устройство внутри контейнера не стоит, чтобы не нарушить работу других процессов.
Как ограничить объем и скорость чтения данных из /dev/urandom в скриптах?
Для ограничения объема используют head -c или dd bs=<размер> count=<количество>, чтобы получать строго определенное число байтов. Скорость чтения контролируют с помощью утилиты pv —rate-limit или делением потока на блоки с паузами через sleep. Такой подход предотвращает высокую нагрузку на процессор и защищает другие сервисы от перебоев при одновременном чтении больших объемов данных.