Содержание статьи

Python предоставляет готовые инструменты для создания моделей без сложной ручной математики. Библиотеки TensorFlow и PyTorch позволяют собирать слои, подключать функции активации и запускать обучение даже на базовой конфигурации ноутбука. Для работы достаточно установить пакетный менеджер, подготовить виртуальное окружение и обновить зависимости.
Перед сборкой модели требуется подготовить данные. На практике это включает удаление пропусков, нормализацию числовых столбцов, преобразование категорий и проверку распределений. Эти операции влияют на результат сильнее, чем выбор архитектуры, поэтому важно заранее продумать формат входных признаков.
После подготовки данных можно формировать модель: определять количество слоев, типы нейронов, размер батча и шаг обучения. Для тестирования удобнее разбивать датасет на несколько частей и сохранять промежуточные веса. Такой подход позволяет отслеживать изменения метрик и корректировать параметры без полной переделки проекта.
Подготовка окружения и установка необходимых библиотек
Для работы с нейросетями удобнее использовать отдельное виртуальное окружение. В терминале выполняют команду python -m venv venv, затем активируют его и устанавливают только те пакеты, которые нужны проекту. Такой подход исключает конфликты версий и облегчает перенос проекта на другой компьютер.
После создания окружения устанавливают ключевые библиотеки: pip install tensorflow или pip install torch torchvision torchaudio. Если требуется ускорение на видеокарте, используют версии с поддержкой CUDA, проверяя совместимость драйверов и сборок Nvidia. Для обработки данных ставят pandas, numpy и scikit-learn, которые обеспечивают загрузку, преобразование и разбиение выборок.
Для удобства работы полезно добавить jupyter или jupyterlab. Они позволяют запускать код по ячейкам, фиксировать промежуточные результаты и быстро проверять гипотезы. После установки всех зависимостей проект готов к созданию модели и дальнейшим экспериментам.
Создание набора данных и его предварительная очистка

Набор данных формируют из готовых источников или собирают вручную. При загрузке таблиц в pandas используют функции read_csv или read_json, проверяют типы столбцов и приводят их к единому формату. Если данные собраны из нескольких файлов, выполняют их объединение через merge или concat, контролируя совпадение ключей.
Далее устраняют пропуски. Числовые значения заполняют медианой или предвычисленным ориентиром, а категории – наиболее частым значением. Если столбец содержит значительный процент пропусков, оценивают необходимость его удаления. Такой подход снижает количество некорректных образцов, которые могут исказить обучение.
После обработки пропусков проверяют выбросы. Для числовых полей строят интерквартильный диапазон и удаляют значения, выходящие за его пределы. Текстовые данные очищают от повторяющихся символов, html-меток и служебных токенов. Готовый датасет сохраняют в файл, чтобы избежать повторной подготовки при следующих запусках проекта.
Формирование тренировочных и тестовых выборок

Для разбиения набора данных используют функцию train_test_split из sklearn.model_selection. Перед запуском важно убедиться, что признаки и целевая переменная имеют одинаковое количество строк и не содержат несогласованных индексов.
Разбиение выполняют с учётом структуры данных:
- Для классификации полезно применять параметр stratify, чтобы доли классов в выборках совпадали.
- При работе с временными рядами используют последовательное разделение без перемешивания, чтобы избежать утечки будущих значений.
- Для изображений и аудио предварительно проверяют распределение размеров и длительности, исключая аномальные файлы.
После разбиения сохраняют полученные выборки в отдельные файлы. Это обеспечивает воспроизводимость экспериментов и помогает сравнивать варианты модели без повторной подготовки данных.
Построение базовой архитектуры нейросети на Keras или PyTorch
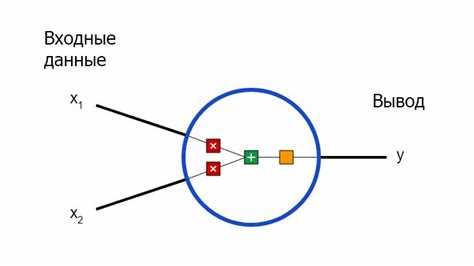
При создании модели на Keras используют последовательную схему через Sequential или функциональный API. Для начала определяют входной размер, затем добавляют плотные или сверточные слои. Параметры указывают явно: число нейронов, форму входа, необходимость нормализации. Такой подход облегчает контроль структуры.
В PyTorch архитектуру оформляют в виде класса, унаследованного от nn.Module. В конструкторе описывают слои, в методе forward – порядок вычислений. Это позволяет добавлять условные ветвления, остаточные блоки и собственные операции.
| Фреймворк | Ключевые элементы модели |
|---|---|
| Keras | Sequential, Dense, Conv2D, Flatten, Dropout, Model.compile |
| PyTorch | nn.Linear, nn.Conv2d, nn.ReLU, nn.Sequential, forward, optim |
При проектировании структуры учитывают характер задачи: для изображений применяют сверточные слои, для текста – рекуррентные или трансформеры, для табличных данных – плотные блоки с нормализацией. После определения слоев проверяют итоговую форму выходного тензора и убеждаются, что он совпадает с числом классов или размерностью регрессионной цели.
Настройка параметров модели и выбор функции активации
Параметры обучения задают до запуска первой эпохи. Базовый набор включает размер батча, число эпох и скорость обучения. В Keras используют model.compile с указанием оптимизатора, например Adam или SGD. В PyTorch параметры передают в optim.Adam или optim.SGD, контролируя значение lr и наличие момента.
Функцию активации выбирают в зависимости от входных данных и задачи. Для скрытых слоёв уместны ReLU, LeakyReLU или GELU, которые снижают риск затухания градиента. В задачах классификации с несколькими классами выход оформляют через softmax, а в бинарных – через sigmoid. Для регрессии выходной слой оставляют линейным без активации.
Перед запуском обучения проверяют, совпадает ли форма выходного тензора с выбранной функцией активации. Например, softmax требует число выходных нейронов, равное количеству классов. Если структура корректна, можно фиксировать параметры и переходить к циклу обучения.
Запуск обучения и отслеживание метрик
Обучение модели в Keras выполняют через model.fit, указывая тренировочные и валидационные данные, размер батча и количество эпох. Для PyTorch создают цикл обучения, в котором выполняют проход вперёд, вычисляют функцию потерь, делают обратное распространение и обновляют веса через оптимизатор.
Метрики отслеживают на каждой эпохе. Для классификации используют accuracy и f1-score, для регрессии – MAE или MSE. В Keras метрики передаются в compile, в PyTorch их вычисляют вручную после каждого батча или эпохи.
Для визуального контроля полезно строить графики динамики потерь и точности с помощью matplotlib или TensorBoard. Это помогает выявить переобучение, недообучение и корректировать параметры модели до завершения обучения.
Сохранение модели и проверка предсказаний на новых данных

После завершения обучения модель сохраняют для повторного использования. В Keras применяют model.save(«model.h5») или формат SavedModel. В PyTorch сохраняют словарь весов через torch.save(model.state_dict(), «model.pth»), а при загрузке создают экземпляр класса и используют load_state_dict.
Для проверки на новых данных предварительно выполняют те же преобразования, что и при обучении: нормализация чисел, кодирование категорий, изменение формы тензоров. После этого запускают предсказания с помощью model.predict в Keras или model(input_tensor) в PyTorch.
Результаты оценивают по метрикам, применяемым во время обучения, и визуализируют распределение предсказаний. При выявлении значительных отклонений проверяют корректность подготовки новых данных и соответствие формы входа, чтобы избежать ошибок в интерпретации результата.
Вопрос-ответ:
Какие библиотеки нужны для базовой нейросети на Python?
Для большинства проектов используют TensorFlow или PyTorch для построения и обучения моделей. Для подготовки данных применяют pandas и numpy, а для разбиения выборок и оценки метрик — scikit-learn. Если планируется работа с изображениями, подключают torchvision или tf.keras.preprocessing.image.
Как подготовить данные перед обучением нейросети?
Сначала проверяют наличие пропусков и некорректных значений, затем нормализуют числовые признаки и кодируют категориальные переменные. Для текстов используют токенизацию и векторизацию. После этого данные разделяют на тренировочную и тестовую выборки с сохранением структуры классов, чтобы обучаемая модель корректно отражала распределение признаков.
Как выбрать архитектуру нейросети для задачи классификации?
Для таблиц обычно используют плотные слои с ReLU и Dropout, чтобы избежать переобучения. Для изображений применяют сверточные слои с нормализацией, а для текста — рекуррентные сети или трансформеры. Важно согласовать количество выходных нейронов с числом классов и правильно подобрать функции активации, например softmax для многоклассовой классификации.
Каким образом проверяют работу модели на новых данных?
Сначала новые данные обрабатывают так же, как тренировочные: нормализуют, кодируют категории, меняют форму тензоров. После этого запускают предсказания через model.predict в Keras или вызов модели в PyTorch. Результаты сравнивают с реальными значениями с помощью тех же метрик, что использовались при обучении, чтобы оценить точность и стабильность модели.