Содержание статьи

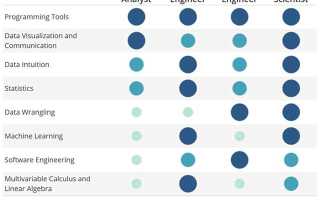
Дата саентисту требуется уверенная работа с данными: понимание структуры наборов, умение очищать значения, устранять пропуски, контролировать выбросы, собирать признаки и проверять их пригодность. На практике это означает владение pandas, NumPy, инструментами для профилирования данных, навыки построения пайплайнов преобразований и понимание того, как формируются разметки в реальных проектах.
Необходима база в статистике: распределения, дисперсия, корреляции, проверка гипотез, оценка доверительных интервалов, работа с перекрёстной проверкой. Эти знания позволяют выбрать модель, которая подходит под объём выборки, структуру признаков и требования к интерпретации.
Прикладные алгоритмы – ядро повседневной работы. Дата саентисту нужно разбираться в линейных и деревьях решений, регуляризации, методах отбора признаков, градиентном бустинге, методах оптимизации и базовых нейросетях. Важно понимать ограничения каждого подхода: чувствительность к шкалам, сложность обучения, требования к памяти и устройству целевой метрики.
Для реальных задач требуется инженерная дисциплина: уверенное владение Python, работа с виртуальными окружениями, понимание процессов развёртывания моделей, умение использовать Docker и базовые инструменты CI. В сочетании с практикой версионирования данных и моделей это позволяет переносить решения из ноутбука в стабильный сервис.
Дата саентист должен ориентироваться в инструментах визуализации данных и отладки моделей: графики распределений, матрицы ошибок, анализ важности признаков, оценка устойчивости предсказаний. Эти элементы помогают объяснять результаты команде и выявлять слабые места в данных и модели.
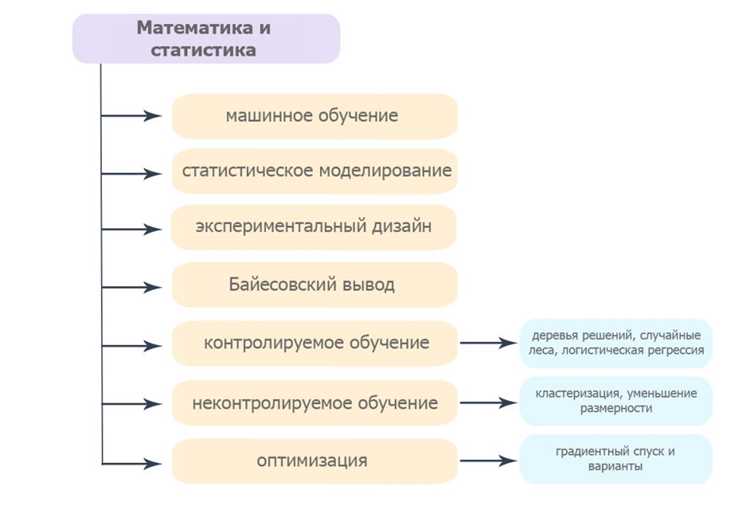
Базовые математические инструменты для моделирования
Линейная алгебра – основа большинства алгоритмов. Матрицы и векторы применяются при работе с градиентами, преобразованиями признаков, оптимизацией и разложениями. Минимальный набор включает операции умножения матриц, вычисление собственных значений, сингулярное разложение и работу с разреженными структурами данных. Для практических задач важно понимать, как масштаб признаков влияет на условность матрицы и устойчивость вычислений.
Математический анализ используется при настройке моделей через градиентные методы. Частные производные, якобианы и гессианы позволяют контролировать поведение функции потерь и выбирать подходящий шаг градиента. При обучении крупных моделей важно уметь оценивать скорость сходимости и обнаруживать точки, где функция меняет кривизну.
Теория вероятностей и статистика позволяют корректно интерпретировать данные и проверять гипотезы. Ключевые элементы: распределения (нормальное, бернуллиевское, биномиальное, пуассоновское), дисперсия, ковариация, доверительные интервалы, проверка статистической значимости. Эти инструменты нужны для выбора метрик, оценки риска переобучения и построения вероятностных моделей.
Для удобства систематизации ключевых инструментов можно использовать таблицу.
| Раздел | Что использовать в моделировании | Практическое применение |
|---|---|---|
| Линейная алгебра | Матрицы, разложения, собственные значения | PCA, факторизация, работа с признаками |
| Математический анализ | Градиенты, якобианы, гессианы | Оптимизация функции потерь, настройка шага обучения |
| Теория вероятностей | Распределения, дисперсии, ковариации | Оценка неопределенности, построение вероятностных моделей |
| Статистика | Гипотезы, доверительные интервалы, выборки | Проверка значимости, контроль качества данных |
Для подготовки дата саентисту достаточно владеть фундаментальными понятиями, но для работы с реальными задачами потребуются регулярные вычисления матричных операций, умение анализировать функции и уверенная работа с вероятностными моделями. Это ускоряет разработку и снижает риск ошибок при интерпретации результатов.
Ключевые методы машинного обучения для типовых задач
Линейные модели подходят для скоринговых систем, базовых прогнозов и задач с большим числом признаков. Регуляризация L1 помогает сокращать размерность за счёт обнуления весов, L2 уменьшает влияние шумовых признаков. Для бинарных задач применяется логистическая регрессия, для численных – линейная регрессия с контрольными метриками RMSE и MAE.
Деревья решений используются там, где важна интерпретация и работа с разнородными данными. Модели устойчивы к пропускам и не требуют масштабирования признаков. Для повышения точности применяются ансамбли: Random Forest уменьшает разброс, Gradient Boosting повышает качество на сложных зависимостях за счёт последовательного исправления ошибок.
Методы опорных векторов подходят для задач с ограниченными выборками и сложными разделяющими поверхностями. Ядровые функции позволяют моделировать нелинейные зависимости, но требуют аккуратного подбора параметров и масштабирования признаков.
Нейронные сети используются для обработки изображений, текста и табличных данных с большим количеством наблюдений. CNN применяются в классификации и сегментации изображений, RNN и трансформеры – в анализе текста. При работе с табличными данными MLP показывает стабильные результаты только при достаточном объёме данных и тщательной настройке гиперпараметров.
Кластеризация k-means востребована в сегментации клиентов, поиске аномалий и группировании документов. Алгоритм чувствителен к масштабу признаков и выбору k, поэтому требуется нормализация и анализ нескольких вариантов. DBSCAN используется при наличии выбросов и неоднородных кластеров без заранее заданного количества групп.
Методы снижения размерности, такие как PCA и t-SNE, помогают выявлять структуры в данных, ускорять обучение моделей и устранять мультиколлинеарность. PCA подходит для подготовки данных к моделированию, а t-SNE – для визуальной оценки скрытых групп.
Работа с данными: загрузка, очистка и подготовка

Дата саентисту требуется уверенно работать с источниками данных: SQL-базы, REST-API, файловые хранилища. Для табличных данных применяются pandas.read_csv, read_parquet, загрузка из PostgreSQL через SQLAlchemy, из S3 – через boto3. На этапе импорта важно контролировать типы столбцов, чтобы избежать автоматического приведения, и фиксировать схему набора.
Очистка начинается с выявления пропусков: подсчёт isna().sum(), анализ долей отсутствующих значений и принятие решения – удаление строк, заполнение константой или статистикой распределения. Для числовых признаков уместно заменять пропуски медианой, для категориальных – отдельной меткой или модой. При больших массивах данных полезно использовать dask или pyspark для распределённой обработки.
Следующий шаг – устранение выбросов. Применяются межквартильный размах, процентильные фильтры или логарифмирование при сильном перекосе распределения. В задачах прогнозирования временных рядов проверяется стабильность частоты наблюдений и корректность временной метки.
Подготовка включает нормализацию признаков (StandardScaler, MinMaxScaler), кодирование категорий (OneHotEncoder, TargetEncoder), генерацию новых переменных: частотные признаки, агрегаты по группам, скользящие статистики. Для ускорения обучения моделей удобно сохранять промежуточные результаты в Parquet с явной схемой и компрессией snappy.
Завершающий этап – контроль качества подготовки данных: проверка диапазонов, уникальностей, долей классов, корректности разбиения на обучающую и тестовую выборки. Это снижает риск ошибок в последующем моделировании и повышает воспроизводимость экспериментов.
Применение Python и основных библиотек анализа данных
Python используют для построения рабочих конвейеров обработки данных, быстрой проверки гипотез и разработки прототипов моделей. В реальных проектах язык удобен благодаря большому выбору библиотек и низкому порогу интеграции с системами хранения, потоковыми сервисами и инструментами оркестрации.
Pandas применяют для работы с табличными наборами: фильтрации, объединения, ресемплинга временных рядов, вычисления агрегатов и подготовки признаков. Ключевые приемы – работа с типами данных, оптимизация памяти через downcast, использование vectorized-операций вместо циклов и минимизация количества вызовов apply.
NumPy нужен для операций над массивами, линейной алгебры и построения быстрых вычислительных блоков. Важные навыки: знание broadcast-механики, умение собирать вычисления в единый векторный шаг, использование матричных разложений и методов оптимизации, реализованных на уровне C.
Matplotlib и Plotly используют для диагностики данных и моделей: поиск выбросов, анализ распределений, оценка стабильности признаков, сравнение результатов разных подходов. Практика – формировать графики, которые отражают конкретную задачу: указание шкал, логарифмирование осей, выведение статистик на графиках.
Scikit-learn применяют для решения стандартных задач: классификации, регрессии, кластеризации и отбора признаков. Важные элементы: корректное разделение выборки, настройка гиперпараметров через перекрестную проверку, использование Pipeline для исключения утечек данных и автоматизации обработки.
Для крупных наборов данных используют Dask или Polars. Первый масштабирует вычисления по нескольким ядрам и узлам, второй ускоряет операции с табличными структурами за счет колоночного формата и параллельного исполнения. На практике выбирают тот инструмент, который лучше подходит под объем и паттерн чтения.
Главная задача – строить воспроизводимые сценарии анализа: фиксировать версии библиотек, оформлять вычислительные шаги в функции, документировать преобразования и хранить артефакты обработки. Это снижает вероятность ошибок и упрощает перенос результатов между средами.
Построение и проверка моделей в реальных проектах
При построении моделей первоочередная задача – корректное разделение данных на обучающую, валидационную и тестовую выборки с учётом временной структуры и редких классов. Использование случайного разбиения без учёта этих факторов может привести к утечке информации и завышенной оценке качества.
Выбор алгоритмов зависит от задачи и объема данных. Для небольших наборов подходят логистическая регрессия и деревья решений, для высокоразмерных – градиентный бустинг, случайный лес, нейронные сети. Важно заранее определить метрики оценки: F1, ROC-AUC, RMSE, MAE или специализированные показатели бизнес-эффекта.
Гиперпараметры настраивают через кросс-валидацию, grid search или randomized search. Для больших моделей эффективнее использовать Bayesian optimization или optuna. Практика показывает, что правильная предобработка и подбор признаков часто дают больший прирост качества, чем сложная архитектура модели.
Регуляризация и контроль переобучения обязательны. Применяют L1/L2, dropout, early stopping, ограничение глубины деревьев. Важно фиксировать версию библиотек и random seed, чтобы результаты были воспроизводимыми.
Верификация модели включает тестирование на отложенной выборке, анализ ошибок по сегментам данных и визуализацию предсказаний. Выявление систематических сдвигов сигнализирует о необходимости пересмотра признаков или гиперпараметров.
Для интеграции модели в продукт создают пайплайны, которые объединяют подготовку данных, предсказания и сохранение результатов. Тестируют производительность и стабильность на реальных данных, контролируют drift признаков и качества модели в процессе эксплуатации.
Взаимодействие с хранилищами и потоками данных

Дата саентист должен уметь работать с различными типами хранилищ и потоков данных, понимая их особенности и ограничения. Основные категории включают реляционные базы данных, NoSQL-хранилища, объектные хранилища и стриминговые платформы.
Для реляционных баз данных (PostgreSQL, MySQL, MS SQL) важны навыки написания оптимизированных SQL-запросов, индексации, агрегации и работы с транзакциями. Опыт использования ORM (SQLAlchemy, Django ORM) ускоряет интеграцию моделей и аналитики.
NoSQL-хранилища (MongoDB, Cassandra, Redis) требуют понимания схем без жесткой структуры, горизонтального масштабирования и особенностей работы с ключ-значение, документами или графами. Для больших данных критично уметь строить запросы с учетом распределенности и согласованности.
Объектные хранилища (AWS S3, Google Cloud Storage, Azure Blob) применяются для хранения больших объемов файлов, логов и дампов. Дата саентист должен знать методы загрузки, версионирования и управления правами доступа, а также интеграцию с инструментами обработки данных (Spark, Dask, Pandas).
Работа с потоками данных включает платформы Kafka, RabbitMQ, Kinesis и Flink. Необходимы навыки настройки топиков, потребителей и продюсеров, понимание схем сериализации (Avro, Protobuf, JSON) и обеспечение надежной обработки сообщений при высокой нагрузке.
Рекомендации по практике:
- Осваивать SQL и оптимизацию запросов на реальных таблицах с миллионами строк.
- Пробовать интеграцию разных типов хранилищ с Python, используя библиотеки pandas, PySpark и Dask.
- Настраивать локальные или облачные кластеры Kafka и тестировать обработку потоков данных в реальном времени.
- Понимать особенности ACID и BASE моделей для правильного проектирования ETL и аналитических пайплайнов.
- Использовать мониторинг и логирование при работе с потоками для отслеживания задержек и потерь данных.
Вопрос-ответ:
Какие навыки работы с данными необходимы дата-сайентисту для первых проектов?
Дата-сайентист должен уверенно уметь загружать и обрабатывать данные из разных источников: CSV, базы данных, API. Важно владеть инструментами очистки данных, выявлением и исправлением пропусков и аномалий. Знание библиотек для работы с табличными данными, таких как pandas или SQL, позволяет быстро подготовить данные для анализа и моделей. Без этих навыков построение моделей и проведение аналитики будет затруднено.
Насколько важно понимание статистики и математики для практической работы с моделями?
Понимание статистики и базовой линейной алгебры помогает правильно интерпретировать результаты моделей и выявлять ошибки. Например, знание вероятностных распределений и метрик качества моделей позволяет оценивать их стабильность и точность. Даже при использовании готовых библиотек важно понимать, как работают алгоритмы, чтобы корректно настраивать параметры и анализировать прогнозы.
Какие языки программирования должен знать дата саентист для работы с данными?
Для работы с данными чаще всего используют Python и R. Python подходит для обработки больших объёмов данных, построения моделей машинного обучения и интеграции с другими системами. R чаще применяют для статистического анализа и визуализации данных. Важно также уметь работать с SQL для извлечения данных из баз, а знание Bash или командной строки полезно при автоматизации задач.
Насколько важны знания математических основ для работы дата саентиста?
Математика играет значительную роль в работе дата саентиста. Базовые знания линейной алгебры, вероятности и статистики позволяют понимать, как работают алгоритмы машинного обучения, правильно оценивать модели и интерпретировать результаты. Например, понимание регрессии или классификации требует представления о функциях, матрицах и вероятностных распределениях. Без этих знаний можно выполнять технические действия, но качество анализа и глубина выводов будут ограничены.