Работа с датафреймами в Python начинается с понимания структуры исходных данных. Новый датафрейм часто создается для фильтрации, агрегации или модификации информации без изменения оригинального объекта. Это позволяет сохранять исходные данные для последующего анализа.
Для выбора конкретных колонок или строк используется метод loc или iloc, а также логическая индексация. Например, можно сформировать датафрейм только с нужными столбцами или выбрать строки, где значения определенного столбца удовлетворяют условию.
Новый датафрейм можно создавать через копирование исходного с помощью copy(), чтобы изменения не отражались на оригинале. Это особенно важно при работе с большими наборами данных, где случайное изменение может привести к потере информации.
При необходимости объединения или объединения данных из нескольких источников применяются методы merge, concat и join. Они позволяют создавать новые структуры с сохранением связи между ключевыми столбцами.
Дополнительно для оптимизации памяти рекомендуется выбирать только нужные типы данных и исключать лишние колонки на этапе создания нового датафрейма. Это ускоряет обработку больших массивов данных и упрощает последующий анализ.
Копирование датафрейма с сохранением всех столбцов и строк
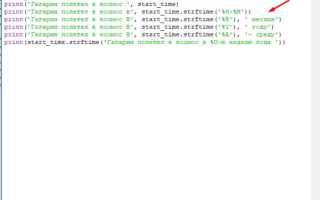
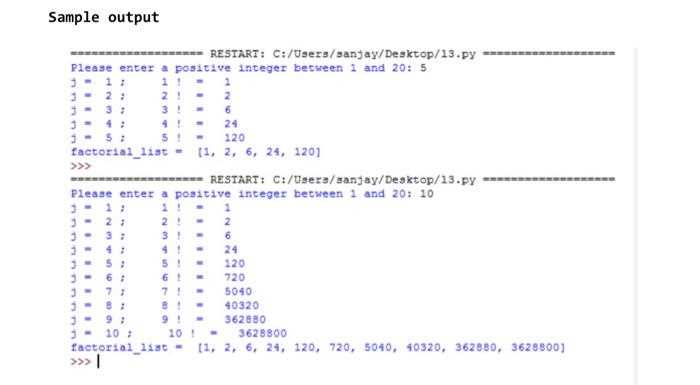
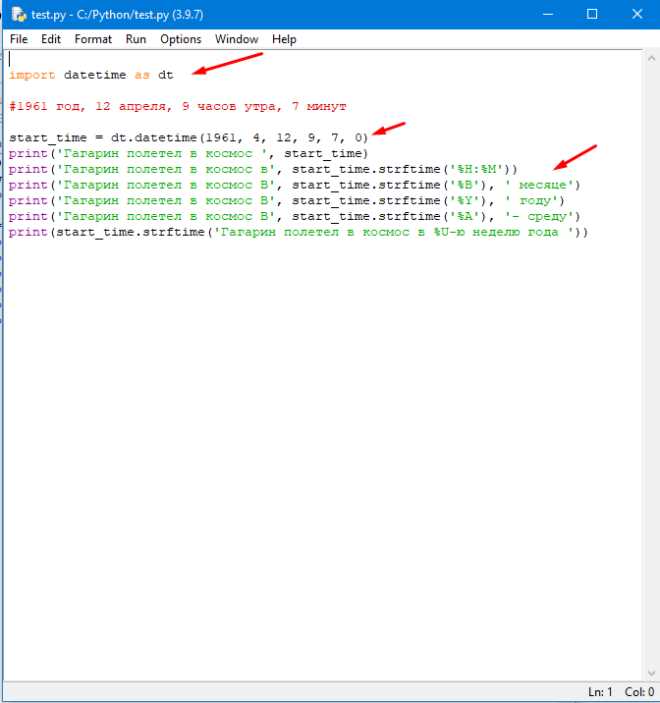
Для создания полного дубликата существующего датафрейма в Python используется метод copy() библиотеки pandas. Этот метод позволяет сохранить все столбцы, строки и типы данных без изменений. Пример:
import pandas as pd
df_original = pd.DataFrame({ 'Имя': ['Аня','Борис'], 'Возраст': [25, 30] })
df_copy = df_original.copy()
После выполнения copy() любые изменения в df_copy не затрагивают df_original. Это особенно важно при фильтрации, сортировке или добавлении новых столбцов, чтобы исходные данные оставались нетронутыми.
Проверка целостности копии может быть выполнена через equals():
df_copy.equals(df_original) вернёт True, если все строки и столбцы совпадают.
Пример проверки структуры датафрейма:
| Операция | Описание |
|---|---|
| df_copy.shape | Возвращает кортеж (число строк, число столбцов) |
| df_copy.columns | Список всех столбцов |
| df_copy.dtypes | Типы данных столбцов |
При необходимости глубокого копирования вложенных объектов внутри столбцов можно использовать df.copy(deep=True). Это создаёт полностью независимую копию, включая вложенные списки или словари.
Выбор определённых столбцов для нового датафрейма
Для формирования нового датафрейма с выбранными столбцами используют конструкцию `new_df = df[[‘col1’, ‘col2’]]`. Порядок в списке определяет порядок столбцов в новом объекте.
Чтобы выбрать столбцы по типу данных, применяют `df.select_dtypes(include=[‘number’])` для числовых или `include=[‘object’]` для текстовых. Это упрощает работу с большими наборами данных.
Для динамического выбора столбцов по части названия используют `df.filter(like=’pattern’)`. Например, `df.filter(like=’date’)` вернёт все столбцы с ‘date’ в названии.
Если есть риск отсутствия некоторых столбцов, применяют пересечение списков: `df[df.columns.intersection([‘col1′,’col2’])]`. Это предотвращает ошибки при формировании нового датафрейма.
Чтобы новый датафрейм был независимым от исходного, используют метод `.copy()`: `new_df = df[[‘col1’, ‘col2’]].copy()`. Это сохраняет данные при последующих изменениях исходного датафрейма.
Фильтрация строк по условию для создания подмножества данных
Для формирования нового датафрейма на основе существующего применяется фильтрация строк по заданным условиям. В pandas это реализуется через логические выражения внутри квадратных скобок. Например, чтобы выбрать все строки, где значение столбца «Возраст» больше 30, используется выражение: df[df['Возраст'] > 30].
Можно комбинировать несколько условий с помощью операторов & (и) и | (или). Например, выбрать строки, где «Возраст» больше 30 и «Город» равен «Москва»: df[(df['Возраст'] > 30) & (df['Город'] == 'Москва')]. Скобки обязательны для корректного вычисления выражения.
Для фильтрации по списку значений применяется метод isin(). Пример: выбрать строки, где «Отдел» находится в списке [«Продажи», «Маркетинг»]: df[df['Отдел'].isin(['Продажи','Маркетинг'])].
Фильтрация с использованием строковых методов позволяет создавать подмножества на основе текста. Например, строки, где «Фамилия» начинается с буквы «И»: df[df['Фамилия'].str.startswith('И')].
Результатом всех этих операций является новый датафрейм, содержащий только строки, соответствующие заданным условиям, без изменения исходного набора данных. Это позволяет проводить дальнейший анализ или подготовку данных для моделей, сохраняя оригинальный датафрейм нетронутым.
Создание нового датафрейма с изменёнными значениями столбцов
Для изменения значений отдельных столбцов при создании нового датафрейма в Pandas можно использовать метод assign() или прямое присваивание с помощью выражений. Например, если необходимо увеличить значения столбца ‘цена’ на 10%, используется следующий подход:
df_new = df.assign(цена = df['цена'] * 1.10)
Метод assign() возвращает новый датафрейм, оставляя исходный без изменений, что важно для сохранения оригинальных данных.
Для одновременного изменения нескольких столбцов удобно применять lambda-функции внутри assign:
df_new = df.assign(цена = lambda x: x['цена']*1.10, количество = lambda x: x['количество'] + 5)
Если требуется создать датафрейм с более сложными преобразованиями, можно использовать apply() с функцией для строки или столбца. Например, добавление категории в зависимости от цены:
df_new = df.copy()
df_new['категория'] = df_new['цена'].apply(lambda x: 'дорого' if x > 1000 else 'дешево')
При работе с текстовыми столбцами допустимо изменять регистр, удалять пробелы или заменять значения с помощью str-методов:
df_new = df.assign(название = df['название'].str.upper().str.strip())
Такой подход позволяет создавать новые датафреймы с нужными трансформациями, не затрагивая исходные данные, и обеспечивает гибкость при дальнейшей обработке или анализе.
Объединение нескольких датафреймов в новый
Для создания нового датафрейма на основе нескольких исходных можно использовать методы pandas.concat() и pandas.merge(). Выбор метода зависит от структуры данных и необходимого результата.
Метод pandas.concat() применяется для последовательного соединения датафреймов по строкам или столбцам:
- По умолчанию
concat([df1, df2])объединяет датафреймы по строкам (axis=0). - Для объединения по столбцам используется
concat([df1, df2], axis=1). - Если индексы пересекаются, можно использовать
ignore_index=Trueдля перенумерации строк в новом датафрейме.
Метод pandas.merge() позволяет объединять датафреймы по ключевым столбцам, аналогично SQL JOIN:
merge(df1, df2, on='id')создаёт новый датафрейм, объединяя строки с совпадающими значениями в столбцеid.- Тип объединения можно задать через параметр
how:'inner','left','right','outer'. - Для нескольких ключей используется список столбцов:
on=['id', 'date'].
При объединении нескольких датафреймов рекомендуется:
- Проверять совпадение типов данных в объединяемых столбцах.
- Обрабатывать дубликаты до объединения, если они нежелательны.
- Использовать
reset_index()послеconcatдля упорядочивания индексов.
Пример объединения трёх датафреймов по строкам с перенумерацией индексов:
import pandas as pd
df_new = pd.concat([df1, df2, df3], ignore_index=True)
Пример объединения двух датафреймов по ключевому столбцу с сохранением всех строк из обоих датафреймов:
df_merged = pd.merge(df1, df2, on='id', how='outer')
Сброс индексов и переиндексация нового датафрейма
При создании нового датафрейма на основе фильтрации или объединения исходных данных исходные индексы сохраняются по умолчанию. Это может привести к несоответствию порядковых номеров строк и затруднениям при последующей обработке.
Для сброса индекса используется метод reset_index(). Например, new_df = df_filtered.reset_index(drop=True) создаёт новый датафрейм с индексами от 0, игнорируя старые значения. Параметр drop=True предотвращает добавление старого индекса как отдельного столбца.
Если требуется сохранить старый индекс для анализа, его можно включить в новый датафрейм: new_df = df_filtered.reset_index(drop=False). В этом случае старые индексы становятся отдельным столбцом с названием index.
Для переиндексации по собственному набору меток применяется метод reindex(). Например, new_df = new_df.reindex([2, 0, 1]) изменяет порядок строк согласно заданному списку индексов. Это полезно для упорядочивания строк по внешним критериям.
При работе с большими датафреймами сброс и переиндексация ускоряют доступ к строкам и упрощают объединение с другими таблицами, так как гарантируют корректное соответствие индексов и предотвращают дублирование.
Вопрос-ответ:
Можно ли создать новый датафрейм, выбрав только некоторые столбцы из исходного?
Да, для этого используют выборку по именам столбцов. В pandas достаточно указать список столбцов: new_df = df[['столбец1', 'столбец2']]. Новый датафрейм будет содержать только выбранные столбцы, а исходный останется без изменений. Такой подход позволяет работать только с нужными данными, не создавая лишних копий всего набора.
Как создать новый датафрейм с изменёнными значениями определённых столбцов?
Для этого сначала делают копию исходного датафрейма с помощью df.copy(). Затем можно изменить отдельные столбцы: например, new_df['столбец'] = new_df['столбец'] * 2. При этом исходный датафрейм не изменяется, а новый содержит обновлённые данные. Такой метод полезен для расчётов и модификации данных без риска потерять исходные значения.
Как фильтровать строки по условию для создания нового датафрейма?
Используют булеву индексацию: new_df = df[df['столбец'] > значение]. Это создаёт датафрейм, включающий только строки, удовлетворяющие условию. Можно комбинировать несколько условий с помощью операторов & и |. Такой способ позволяет выделять подмножества данных для анализа без изменения исходного датафрейма.
Как объединить несколько датафреймов в один новый?
Для объединения используют функции pd.concat() или pd.merge(). concat() соединяет датафреймы по строкам или столбцам, сохраняя структуру, а merge() объединяет по ключевым столбцам, создавая объединённую таблицу по совпадению значений. После объединения можно сбросить индекс с помощью reset_index(drop=True), чтобы получить последовательный индекс.
Влияет ли создание нового датафрейма на исходный?
Если создавать новый датафрейм через простое присваивание, изменения будут отражаться в исходном. Чтобы сделать полностью независимый датафрейм, используют df.copy(). Новый объект не ссылается на исходный, и любые изменения не затрагивают исходные данные. Это важно при экспериментальной обработке данных, чтобы сохранить оригинальные значения.