Именование таблиц в базе данных напрямую влияет на читаемость схемы и удобство работы с SQL-запросами. Оптимальная практика – использовать однозначные и понятные имена, отражающие содержимое таблицы. Например, таблица с данными о клиентах должна называться customers, а не data1 или tbl_cl.
Следует придерживаться единого стиля: нижний регистр с подчеркиваниями для разделения слов (order_items) обеспечивает совместимость между различными СУБД и упрощает автоматическую генерацию кода. Избегайте пробелов, спецсимволов и кириллицы, так как это может вызвать ошибки при миграциях и интеграциях.
Использование множественного числа для названия таблицы (products вместо product) помогает сразу определить, что таблица хранит набор записей, а не одну сущность. Также важно не включать тип таблицы в имя, например tbl_users или view_orders, если это не требуется для специфики проекта.
Для улучшения поддержки и расширяемости базы данных применяйте префиксы и суффиксы осмысленно: archived_orders для архивных данных или temp_sessions для временных таблиц. Четкая структура имен позволяет разработчикам и аналитикам быстрее ориентироваться в сложных схемах с десятками таблиц.
Ключевой принцип – предсказуемость и консистентность. Любое отклонение от выбранного стиля увеличивает вероятность ошибок при join-операциях, импорте данных и поддержке кода. Строгое соблюдение правил именования снижает технический долг и ускоряет командную работу с базой данных.
Использование понятных и однозначных названий таблиц

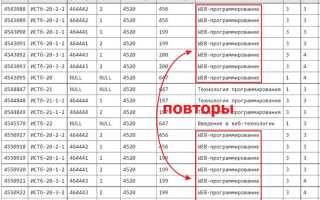
Названия таблиц должны отражать содержимое данных. Например, таблица с информацией о заказах клиентов должна называться orders или customer_orders, а не абстрактно вроде data1. Это снижает риск ошибок при написании SQL-запросов и упрощает поддержку базы данных.
Рекомендуется использовать единый стиль именования. Чаще всего применяются:
- snake_case: product_categories, user_profiles;
- camelCase: productCategories, userProfiles;
- PascalCase: ProductCategories, UserProfiles.
Выбор стиля зависит от стандартов проекта, но важно придерживаться его последовательно для всех таблиц.
Не используйте сокращения без необходимости. Таблица cust_ord менее информативна, чем customer_orders. Исключение составляют только общепринятые аббревиатуры, например id или qty, которые понятны всем разработчикам.
Если таблица содержит специализированные данные, уточняйте назначение через имя. Например, для хранения исторических цен используйте product_price_history, а для текущих – product_prices. Это предотвращает путаницу при интеграции с аналитикой или внешними системами.
Для комплексных систем создавайте иерархию названий через префиксы или категории. Примеры:
- auth_users, auth_roles – для модулей авторизации;
- sales_orders, sales_invoices – для финансового модуля;
- inventory_products, inventory_stock – для склада.
Такой подход повышает читаемость схемы базы и облегчает поиск таблиц в крупных проектах.
Применение единообразного стиля написания

Единообразный стиль именования таблиц облегчает навигацию по базе данных и ускоряет работу разработчиков. Рекомендуется выбрать один подход к регистру символов: либо все имена в нижнем регистре, либо использование CamelCase без пробелов. Например, `customer_orders` предпочтительнее, чем смешанный `Customer_Orders` и `customerOrders` в одной базе.
Для разделения слов в именах таблиц лучше использовать символ подчеркивания (`_`). Это делает имена более читаемыми и предотвращает ошибки при генерации SQL-запросов. Пример: `order_items_history` вместо `orderitemshistory`.
Использование префиксов для групп связанных таблиц повышает структурность базы. Таблицы, связанные с пользователями, могут начинаться с `user_`, например: `user_profiles`, `user_sessions`. Это упрощает поиск и документирование.
Необходимо избегать сокращений, которые неочевидны другим разработчикам. Сокращение `addr` может быть понято как `address` или `administrator`. Полные слова улучшают читаемость и сокращают время на разъяснение структуры.
Для временных таблиц и журналов операций рекомендуется единый постфикс или префикс. Например, `tmp_` для временных таблиц (`tmp_import_data`) и `log_` для логов (`log_error_events`). Это помогает отделять рабочие таблицы от вспомогательных и системных.
Документирование выбранного стиля важно: храните правила именования в внутренней документации проекта и используйте их при код-ревью. Любое отклонение должно быть согласовано, чтобы сохранить консистентность на уровне всей базы данных.
Ограничения по длине и допустимым символам
В разных системах управления базами данных (СУБД) максимальная длина имени таблицы варьируется. В MySQL она составляет 64 символа, в PostgreSQL – 63 символа, а в Oracle – 30 символов. Превышение этого лимита приведет к ошибке при создании таблицы, поэтому важно заранее планировать сокращения и стандартизированные префиксы.
Допустимые символы ограничены латинскими буквами (A–Z, a–z), цифрами (0–9) и символом подчеркивания (_). Начинать имя таблицы с цифры запрещено во всех популярных СУБД. Спецсимволы, пробелы и знаки пунктуации могут вызвать ошибки или потребовать использования кавычек/скобок, что снижает читаемость и переносимость кода.
Рекомендуется использовать строгие правила именования:
- Имя таблицы должно отражать содержимое или назначение.
- Использовать короткие, но понятные сокращения.
- Придерживаться одного регистра – обычно нижнего, чтобы избежать проблем при миграции между СУБД с чувствительностью к регистру.
- Избегать одиночных символов и слишком длинных цепочек, превышающих ограничение СУБД.
При проектировании сложных баз данных полезно заранее формализовать конвенцию имен: префиксы для модулей, отдельные таблицы через подчеркивание, ограничение длины до 30–50 символов для универсальной совместимости. Это минимизирует риск ошибок при переносе схемы между MySQL, PostgreSQL и Oracle, а также упрощает автоматизацию и документирование структуры базы данных.
Отражение содержания таблицы в имени

Имя таблицы должно прямо указывать на тип хранимых данных. Например, таблица с информацией о заказах клиентов может называться customer_orders, а не просто orders, чтобы сразу было понятно, что это за заказы. Использование множественного числа для сущностей повышает читаемость: products вместо product, employees вместо employee.
Если таблица содержит агрегированные или специализированные данные, это нужно отражать в имени. Таблица с суммарными продажами за месяц может быть названа monthly_sales_summary, а таблица с логами авторизации – auth_logs. Префиксы и суффиксы помогают обозначить контекст: temp_ для временных таблиц, archive_ для архивных, что упрощает поддержку базы и предотвращает путаницу.
При проектировании сложной базы данных стоит включать в имя таблицы ключевые атрибуты содержимого. Для таблицы, где хранятся контактные данные поставщиков с указанием страны, подходящим названием будет supplier_contacts_country. Такой подход сокращает необходимость обращения к документации и повышает скорость ориентирования разработчиков и аналитиков при работе с SQL-запросами.
Избежание конфликтов с ключевыми словами СУБД
Каждая СУБД имеет собственный список зарезервированных слов, таких как SELECT, TABLE, USER или INDEX. Использование этих слов в качестве имен таблиц приводит к синтаксическим ошибкам и нарушению работы запросов. Например, в PostgreSQL таблица с именем user потребует обязательного заключения имени в двойные кавычки: «user», что усложняет миграции и интеграцию с ORM.
Чтобы предотвратить конфликты, рекомендуется создавать имена таблиц с префиксами, отражающими предметную область: app_user вместо user, order_item вместо order. Этот подход не только устраняет риск пересечения с ключевыми словами, но и повышает читаемость схемы при объединении нескольких модулей.
Следует учитывать, что списки зарезервированных слов различаются между СУБД. MySQL запрещает использование key и index без экранирования, тогда как в Oracle ключевое слово DATE может стать причиной конфликтов. Поэтому перед созданием таблицы необходимо сверяться с официальной документацией выбранной СУБД и при необходимости использовать универсальные имена, не пересекающиеся с зарезервированными.
Автоматизация проверки имен помогает избежать ошибок на раннем этапе. Многие инструменты миграции и генераторы ORM позволяют валидировать имена таблиц и столбцов, предупреждая о совпадении с ключевыми словами. В долгосрочной перспективе такой подход сокращает технический долг и обеспечивает совместимость схемы с различными версиями СУБД без ручной доработки.
Применение префиксов и суффиксов для групп таблиц

Префиксы и суффиксы позволяют структурировать базы данных, особенно когда количество таблиц превышает сотни. Применение префикса `crm_` для всех таблиц, связанных с системой управления клиентами, упрощает идентификацию их в схеме и автоматизацию скриптов.
Суффиксы часто отражают функциональное назначение таблицы. Например, таблицы с историей изменений могут иметь суффикс `_log`, как в `orders_log` или `users_log`. Это сразу показывает, что таблица не хранит текущие данные, а является журналом изменений.
Для модульных систем рекомендуется сочетать префиксы и суффиксы. Таблица с продуктами маркетинга может называться `mkt_products_tmp`, где `mkt_` обозначает маркетинг, а `_tmp` указывает на временные данные, что снижает риск случайного использования в продакшене.
Ниже приведена типовая схема именования групп таблиц для проекта электронной коммерции:
| Группа | Префикс | Суффикс | Пример таблицы |
|---|---|---|---|
| Пользователи | usr_ | _profile | usr_profile |
| Заказы | ord_ | _log | ord_log |
| Маркетинг | mkt_ | _tmp | mkt_campaign_tmp |
| Инвентарь | inv_ | inv_stock |
Префиксы помогают избежать коллизий имен между модулями. Если два разных модуля имеют таблицы с одинаковым названием `settings`, использование `crm_settings` и `erp_settings` предотвращает ошибки при объединении схем или миграциях.
Суффиксы упрощают фильтрацию при работе с утилитами администрирования. SQL-запрос `SHOW TABLES LIKE ‘%_log’` вернёт все таблицы журналов, экономя время и уменьшая вероятность человеческой ошибки при управлении данными.
При разработке сложных систем важно согласовывать правила с командой. Например, префикс `tmp_` можно зарезервировать исключительно для временных таблиц, а `_hist` – для исторических архивов. Такая стандартизация ускоряет ревью кода и интеграцию новых разработчиков.
В больших проектах целесообразно документировать соглашения в отдельной таблице или Markdown-файле. Пример записи: `Префикс usr_ – таблицы пользователей, суффикс _log – лог изменений, префикс mkt_ – маркетинговые данные, суффикс _tmp – временные таблицы`. Это делает правила применимыми и прозрачными для всего проекта.
Вопрос-ответ:
Почему важно придерживаться правил именования таблиц в базе данных?
Соблюдение правил именования упрощает работу с базой данных, делает структуру понятной для других разработчиков и снижает вероятность ошибок при написании запросов. Четкие и логичные имена помогают быстро находить нужные таблицы и понимать их назначение без дополнительной документации.
Можно ли использовать пробелы или специальные символы в названиях таблиц?
Использование пробелов и большинства специальных символов не рекомендуется, так как это может вызвать проблемы при работе с SQL-запросами и интеграции с другими системами. Обычно применяют подчеркивания или верблюжью нотацию (camelCase) для разделения слов.
Как выбрать подходящее имя для таблицы, если она содержит данные о разных типах объектов?
Лучше выбрать имя, которое отражает основное содержание таблицы, например, если таблица содержит информацию о клиентах и их заказах, можно назвать её client_orders. Если таблица содержит несколько типов данных, стоит подумать о разделении её на несколько логически связанных таблиц, чтобы имена оставались ясными и однозначными.
Следует ли использовать сокращения в названиях таблиц?
Сокращения допустимы, но только если они общеизвестные и легко понимаемые другими членами команды. Непонятные или слишком длинные сокращения усложняют работу с базой, поэтому лучше отдавать предпочтение полным и информативным именам.
Какие правила применяются при работе с разными регистрами букв в именах таблиц?
Разные системы управления базами данных по-разному обрабатывают регистр букв. В некоторых регистра имеет значение, в других — нет. Чтобы избежать ошибок, рекомендуется выбрать один стиль — например, все имена в нижнем регистре с подчеркиваниями между словами — и использовать его во всей базе данных последовательно.
Почему важно соблюдать правила именования таблиц в базе данных?
Соблюдение правил именования таблиц помогает поддерживать порядок и читаемость структуры базы данных. Четкие и логичные названия позволяют разработчикам и аналитикам быстро понимать назначение таблицы без необходимости изучать её содержимое. Кроме того, это снижает риск ошибок при написании запросов и облегчает сопровождение проекта в будущем.