Содержание статьи

Сокрытие логики кода применяется для защиты интеллектуальной собственности и предотвращения несанкционированного анализа программ. Простейший способ – обфускация: изменение имён переменных и функций на бессмысленные последовательности символов. Важно сохранять работоспособность программы, так как чрезмерная обфускация может вызвать ошибки исполнения.
Для усложнения потоков выполнения используют условные конструкции, циклы и рекурсию с непредсказуемыми ветвлениями. Практический совет: вставляйте дополнительные проверки и промежуточные вычисления, которые не меняют итогового результата, но затрудняют чтение логики.
Данные внутри программы можно маскировать через кодирование и шифрование. Хранение чувствительных значений в виде закодированных массивов или шифрованных строк снижает риск их прямого извлечения при декомпиляции. Рекомендуется комбинировать несколько методов, чтобы повысить устойчивость к анализу.
Создание ложных точек входа и неявных вызовов функций позволяет запутать структуру программы. На практике: функции с именами, схожими с ключевыми, могут возвращать значения, не влияющие на работу приложения, отвлекая внимание от основной логики.
Использование обфускации для скрытия структуры функций

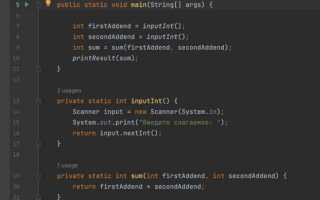
Обфускация изменяет имена функций и переменных на бессмысленные последовательности символов, что затрудняет анализ кода. Например, функция calculateTax() может быть переименована в a1B2C3(), а локальные переменные – в короткие случайные комбинации. Такой подход сохраняет работоспособность программы, но скрывает её внутреннюю структуру.
Помимо переименования, применяют перестановку блоков кода и вставку лишних инструкций. Циклы, условия и вызовы функций можно перемещать так, чтобы логика оставалась корректной, но последовательность выполнения была сложна для понимания. Рекомендация: тестировать каждый этап обфускации отдельно, чтобы избежать нарушений функциональности.
Автоматические инструменты обфускации позволяют задавать правила для конкретных частей кода. Можно исключить критические функции из переименования и применить обфускацию только к вспомогательным модулям. Такой подход снижает риск ошибок и делает анализ сторонними разработчиками более трудоемким.
Обфускация также поддерживает маскировку структуры вызовов через генерацию промежуточных функций. Вместо прямого вызова mainFunction() создают цепочку вызовов через несколько оберток, каждая из которых выполняет часть работы. Это усложняет трассировку и повышает защиту ключевых алгоритмов.
Запутывание потоков выполнения через условные операторы

Условные конструкции позволяют создавать альтернативные ветвления, которые не влияют на конечный результат, но усложняют анализ кода. Например, можно вставлять проверки с константными значениями или сравнения переменных, которые всегда возвращают истинное значение, создавая иллюзию сложной логики.
Для повышения запутанности используют вложенные условия и комбинации логических операторов. Ветвления можно строить через AND и OR, а также включать тернарные операторы для однострочных решений, что усложняет чтение последовательности выполнения.
Практическая рекомендация – чередовать реальные и ложные проверки, интегрируя их с циклами и функциями. Например, цикл может выполняться несколько раз без изменения состояния программы, создавая ложное ощущение нагрузки и усложняя анализ потоков данных.
Также полезно разделять проверку условий на несколько функций, каждая из которых возвращает промежуточные результаты. Это затрудняет трассировку основной логики и повышает устойчивость к обратной разработке, сохраняя при этом корректность выполнения программы.
Маскировка данных с помощью шифрования и кодирования
Шифрование позволяет скрыть содержимое переменных и конфигурационных данных, делая их недоступными при простом просмотре кода. Например, строки с паролями или ключами API можно хранить в виде AES-шифрованного массива байтов и расшифровывать только при необходимости.
Кодирование применяют для преобразования данных в непрямой формат, который не меняет их смысл, но усложняет чтение. Популярные методы – Base64, URL-encoding или custom-алгоритмы замены символов. Рекомендация: комбинировать кодирование и шифрование для разных уровней данных.
Для повышения устойчивости к декомпиляции используют динамическое расшифрование. Значения хранятся в зашифрованном виде и преобразуются в читаемый формат только в момент исполнения, после чего очищаются из памяти. Такой подход минимизирует риск извлечения конфиденциальной информации из бинарника.
Важно контролировать производительность: слишком сложные алгоритмы шифрования или частое расшифрование могут замедлить работу приложения. Оптимальный вариант – применять быстрые алгоритмы для часто используемых данных и более стойкие для критически важных секретов.
Создание ложных точек входа и скрытых вызовов

Ложные точки входа создают иллюзию структуры программы, отвлекая внимание от реальных функций. Например, можно добавить функции с очевидными именами, которые возвращают фиксированные значения и не влияют на основную логику.
Скрытые вызовы реализуют цепочку промежуточных функций, которые вызывают друг друга, прежде чем достигнуть основной функции. Такой подход затрудняет трассировку и анализ потоков выполнения.
Для наглядного планирования используют таблицу распределения функций:
| Функция | Тип | Роль | Влияние на основной результат |
|---|---|---|---|
| authCheck | Ложная | Возвращает всегда true | Нет |
| processDataWrapper | Промежуточная | Вызов нескольких функций перед основной | Нет |
| mainProcessing | Основная | Выполняет критическую обработку | Да |
| loggerStub | Ложная | Имитация логирования | Нет |
Рекомендуется сочетать ложные и промежуточные вызовы с обфускацией и условными конструкциями. Это повышает сложность обратного анализа, при этом функциональность приложения сохраняется.
Разделение логики на мелкие модули с неочевидными связями

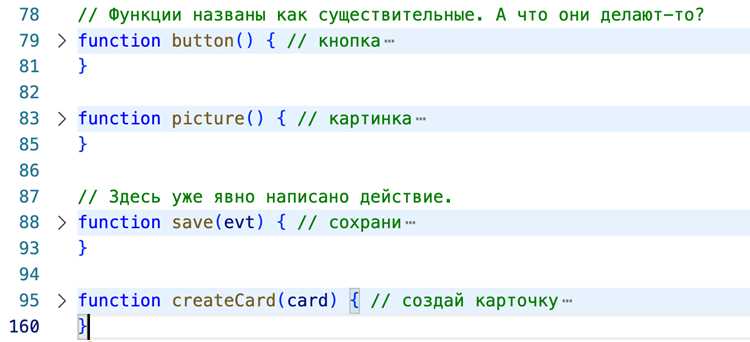
Разделение кода на небольшие модули позволяет скрыть последовательность выполнения и усложнить анализ программы. Каждая функция выполняет узкую задачу и возвращает промежуточные результаты, которые далее используются другими модулями. Практический совет: избегайте очевидных имен функций, чтобы не раскрывать их назначение.
Связи между модулями можно сделать неявными через передачу данных через массивы, объекты или глобальные переменные. На практике: функция может изменять состояние объекта, которое используется несколькими другими функциями, создавая сложную сеть зависимостей.
Для повышения устойчивости к анализу рекомендуется чередовать реальные вычисления с бесполезными операциями внутри модулей. Это создаёт видимость сложной логики, но не влияет на итоговый результат программы.
Также полезно внедрять случайные вызовы модулей в разных последовательностях в зависимости от условий исполнения. Такой подход делает обратное проектирование трудоемким и снижает возможность быстрого понимания структуры кода.
Автоматическая генерация и вставка бессмысленного кода
Вставка бессмысленного кода усложняет анализ программы и создает видимость сложной логики без изменения функциональности. Генерация таких блоков может выполняться автоматически с помощью скриптов или специализированных инструментов.
Рекомендации по реализации:
- Использовать случайные циклы и условия, которые не влияют на результат.
- Вставлять функции-заглушки с бессмысленными вычислениями.
- Комбинировать реальные и ложные переменные для создания ложной зависимости.
Пример структуры вставки:
- Создать функцию с уникальным именем, которая возвращает константу.
- Вставить вызовы этой функции в разных местах кода.
- Перемешивать порядок выполнения с другими функциями через промежуточные вызовы.
Практический совет: контролировать нагрузку на процессор и память, чтобы вставка не снижала производительность приложения. Рекомендуется тестировать сгенерированные блоки отдельно, чтобы избежать ошибок выполнения.
Вопрос-ответ:
Что такое обфускация кода и как она помогает скрывать логику программы?
Обфускация — это процесс изменения структуры и имен функций, переменных и классов на бессмысленные или случайные последовательности символов. Она не изменяет работу программы, но затрудняет анализ кода сторонними разработчиками. Например, функция calculateTax() может быть переименована в a1B2C3(), а переменные заменены на короткие наборы символов. Это делает чтение и понимание алгоритмов значительно сложнее.
Как использование условных операторов может усложнить потоки выполнения?
Вставка дополнительных условий и ветвлений создаёт сложные последовательности выполнения. Можно добавлять проверки с постоянными значениями или логические конструкции, которые не влияют на результат, но создают иллюзию сложной логики. Вложенные условия и комбинированные логические операторы затрудняют трассировку программы, особенно при смешивании реальных и ложных проверок.
Какие методы маскировки данных наиболее подходят для защиты конфиденциальной информации?
Для защиты чувствительных данных применяют шифрование и кодирование. Строки с паролями, ключами API или конфигурационными параметрами можно хранить в виде зашифрованных массивов или использовать Base64 для кодирования. Динамическое расшифрование только во время исполнения программы снижает риск извлечения информации из бинарного файла. Рекомендуется комбинировать методы и применять разные алгоритмы для критических и менее важных данных.
Как создание ложных точек входа и скрытых вызовов помогает защитить код?
Ложные точки входа представляют собой функции с очевидными именами, которые не влияют на реальную логику. Скрытые вызовы — это цепочки промежуточных функций, которые вызывают основную функцию через несколько уровней. Такое построение запутывает структуру программы, затрудняя трассировку потоков и анализ поведения кода сторонними разработчиками. Рекомендуется комбинировать эти методы с обфускацией и запутанными условиями.
Почему разделение логики на мелкие модули с неочевидными связями повышает защиту кода?
Разделение на мелкие модули создаёт сеть зависимостей, которые неочевидны при первом взгляде. Каждая функция выполняет узкую задачу и возвращает промежуточные результаты, которые используются другими модулями. Передача данных через объекты или глобальные переменные делает связи между модулями неявными. Добавление бесполезных операций и случайных вызовов функций усложняет обратное проектирование без изменения конечного результата программы.
Как обфускация и вставка ложного кода влияют на читаемость и поддержку программного обеспечения?
Обфускация изменяет имена функций и переменных на бессмысленные последовательности символов, что затрудняет понимание структуры программы. Вставка ложного кода, циклов и условных проверок создаёт видимость сложной логики без изменения результата. Это усложняет анализ кода сторонними разработчиками и защиту интеллектуальной собственности, но повышает сложность сопровождения: новые разработчики тратят больше времени на разбор модулей, а тестирование требует внимания к цепочкам промежуточных вызовов. Рекомендуется документировать критические модули и выделять отдельные блоки для реальных вычислений, чтобы снизить риск ошибок при изменениях.