Содержание статьи

При работе со списками и массивами в Python часто требуется определить позиции элементов, которые встречаются несколько раз. Это нужно при анализе данных, обработке логов, оптимизации структур или проверке корректности ввода.
Стандартный список в Python не предоставляет встроенного метода для получения индексов повторяющихся значений, однако задачу можно решить несколькими способами. Используются циклы, словари, модуль collections, а при работе с массивами – библиотеки numpy и pandas.
Для небольших списков достаточно базового цикла с проверкой через метод count() или сравнение по значениям. В больших наборах данных предпочтительнее применять группировку через словари или специализированные функции из внешних модулей, которые ускоряют поиск индексов.
Далее рассмотрены практические примеры и объяснено, как извлечь все индексы повторяющихся элементов, независимо от объёма и структуры исходных данных.
Поиск индексов дубликатов с помощью цикла и списка
Самый понятный способ найти индексы повторяющихся элементов – использовать цикл for и метод enumerate(), который возвращает пару индекс–значение. Такой подход не требует дополнительных библиотек и подходит для любых типов данных в списке.
Пример кода:
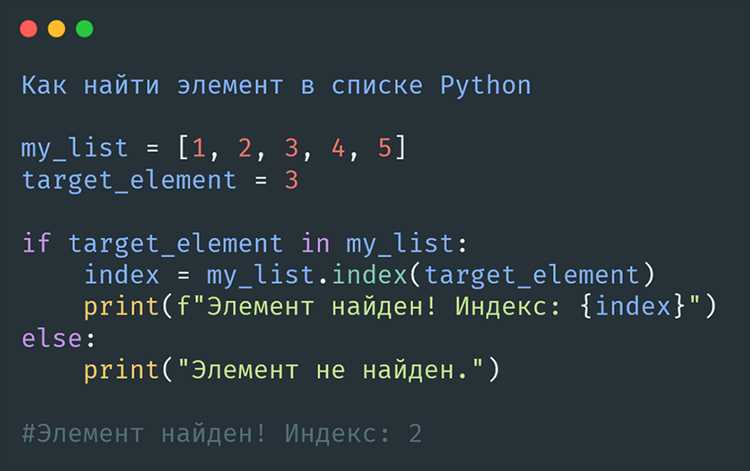
data = [3, 5, 2, 3, 7, 5, 3]
duplicates = {}
for index, value in enumerate(data):
duplicates.setdefault(value, []).append(index)
result = {k: v for k, v in duplicates.items() if len(v) > 1}
print(result)
В этом примере создаётся словарь, где каждому значению соответствует список его индексов. После завершения цикла остаётся отфильтровать только те элементы, у которых длина списка индексов больше одного.
Чтобы улучшить читаемость и гибкость, можно оформить поиск в виде функции:
def find_duplicate_indexes(seq):
duplicates = {}
for i, x in enumerate(seq):
duplicates.setdefault(x, []).append(i)
return {k: v for k, v in duplicates.items() if len(v) > 1}
print(find_duplicate_indexes(['a', 'b', 'a', 'c', 'b']))
# {'a': [0, 2], 'b': [1, 4]}
Практические советы:
- Для числовых и строковых списков используйте именно enumerate() – это надёжнее, чем list.index(), который возвращает только первый индекс.
- Если требуется получить только индексы без группировки по значениям, можно пройтись по списку ещё раз и собрать все позиции повторов в один массив.
- Такой метод удобен при отладке, когда важно видеть не только наличие повторений, но и их точные позиции.
Использование словаря для группировки индексов одинаковых значений

Словарь в Python позволяет удобно сопоставлять каждому значению список его индексов. Такой способ ускоряет поиск и делает структуру данных наглядной, особенно при обработке больших списков.
Реализация основывается на последовательном проходе по элементам с помощью enumerate(). При каждой итерации текущий индекс добавляется в список, связанный с конкретным ключом в словаре.
data = ['x', 'y', 'x', 'z', 'y', 'x']
index_map = {}
for i, value in enumerate(data):
if value not in index_map:
index_map[value] = []
index_map[value].append(i)
print(index_map)
# {'x': [0, 2, 5], 'y': [1, 4], 'z': [3]}
Для краткости можно использовать метод setdefault(), который создаёт список автоматически, если ключ встречается впервые.
index_map = {}
for i, value in enumerate(data):
index_map.setdefault(value, []).append(i)
Если нужно выделить только повторяющиеся значения, фильтруется словарь по длине списков индексов:
duplicates = {k: v for k, v in index_map.items() if len(v) > 1}
print(duplicates)
# {'x': [0, 2, 5], 'y': [1, 4]}
Подход с использованием словаря удобен, когда важно сохранить полную информацию о позициях каждого элемента. Он не требует дополнительных модулей и подходит для любых типов данных, включая строки, числа и кортежи.
Применение модуля collections для нахождения повторений
Модуль collections предоставляет удобные структуры данных для подсчёта и группировки элементов. Для поиска индексов повторяющихся значений удобно использовать defaultdict и Counter.
Пример с defaultdict для хранения списков индексов:
from collections import defaultdict
data = [4, 7, 4, 2, 7, 4]
index_map = defaultdict(list)
for i, value in enumerate(data):
index_map[value].append(i)
duplicates = {k: v for k, v in index_map.items() if len(v) > 1}
print(duplicates)
# {4: [0, 2, 5], 7: [1, 4]}
Если важно сначала определить, какие значения повторяются, можно использовать Counter:
from collections import Counter
counts = Counter(data)
repeated = [x for x, cnt in counts.items() if cnt > 1]
print(repeated)
# [4, 7]
После определения повторов с помощью Counter легко собрать индексы этих значений, используя enumerate() и фильтрацию по списку повторяющихся элементов. Такой подход ускоряет обработку больших массивов, поскольку сначала сокращается множество значений для анализа.
Рекомендации:
- Использовать defaultdict для прямого сопоставления элементов и их индексов.
- Сначала применить Counter для быстрого выявления повторяющихся значений при больших данных.
- Комбинировать оба инструмента для экономии памяти и времени при работе с длинными списками.
Работа с numpy: индексы повторяющихся элементов в массивах
Библиотека numpy позволяет работать с большими массивами чисел быстрее, чем стандартные списки Python. Для поиска индексов повторяющихся элементов используют функции np.where() и np.unique() с параметром return_counts и return_index.
Пример поиска всех индексов повторяющихся значений:
import numpy as np
arr = np.array([1, 2, 3, 2, 4, 1, 5])
unique_vals, counts = np.unique(arr, return_counts=True)
duplicates = unique_vals[counts > 1]
for val in duplicates:
indices = np.where(arr == val)[0]
print(f"Значение {val} встречается в индексах {indices}")
# Значение 1 встречается в индексах [0 5]
# Значение 2 встречается в индексах [1 3]
Использование np.unique() с return_counts=True позволяет быстро определить повторяющиеся значения без циклов по всему массиву. Затем np.where() возвращает массив всех индексов, где это значение встречается.
Практические рекомендации:
- Для больших числовых массивов numpy обеспечивает ускорение поиска по сравнению со стандартными списками.
- Если нужны только первые индексы повторов, можно использовать return_index=True в np.unique.
- Комбинирование np.unique и np.where упрощает фильтрацию и группировку повторяющихся элементов по индексу.
Определение повторов с помощью pandas и извлечение индексов
Библиотека pandas позволяет удобно работать с данными в виде Series или DataFrame. Для поиска повторяющихся значений применяется метод duplicated(), который возвращает булев массив, указывающий на повторные элементы.
Пример извлечения индексов повторов в Series:
import pandas as pd
data = pd.Series([10, 20, 10, 30, 20, 40])
duplicate_indices = data.index[data.duplicated()].tolist()
print(duplicate_indices)
# [2, 4]
Метод duplicated() можно использовать с параметром keep=False, чтобы отметить все вхождения повторяющихся элементов:
all_duplicates = data.index[data.duplicated(keep=False)].tolist()
print(all_duplicates)
# [0, 1, 2, 4]
Для наглядного представления индексов и значений удобно использовать DataFrame:
| Значение | Индексы повторов |
|---|---|
| 10 | [0, 2] |
| 20 | [1, 4] |
Рекомендации:
- Использовать duplicated(keep=False) для анализа всех повторов, а keep=’first’ или keep=’last’ для получения только повторных вхождений после первого или перед последним.
- Для больших наборов данных Series быстрее, чем списки Python, а DataFrame позволяет сразу сохранять результаты в таблицу.
- Комбинирование методов pandas с фильтрацией по индексам упрощает последующую обработку повторов и интеграцию с другими аналитическими задачами.
Фильтрация и сортировка найденных индексов по условию

После получения индексов повторяющихся элементов часто требуется выделить только те позиции, которые соответствуют конкретному условию, или упорядочить их для дальнейшей обработки. В Python это выполняется с помощью списковых включений и функции sorted().
Пример фильтрации индексов, больших 2:
indices = [0, 2, 5, 7]
filtered = [i for i in indices if i > 2]
print(filtered)
# [5, 7]
Сортировка индексов в обратном порядке:
sorted_indices = sorted(filtered, reverse=True)
print(sorted_indices)
# [7, 5]
Для нескольких значений можно использовать словарь с фильтрацией по условию:
index_map = {'a': [0, 3, 5], 'b': [1, 4]}
filtered_map = {k: sorted(v) for k, v in index_map.items() if any(i > 2 for i in v)}
print(filtered_map)
# {'a': [3, 5]}
Рекомендации:
- Использовать списковые включения для гибкой фильтрации по любому критерию.
- Функция sorted() позволяет упорядочить индексы как по возрастанию, так и по убыванию.
- Комбинирование фильтрации и сортировки облегчает дальнейшую обработку повторяющихся элементов и интеграцию с аналитикой.
Вопрос-ответ:
Как с помощью обычного списка в Python найти индексы повторяющихся элементов?
Для списков можно использовать цикл for с enumerate(), чтобы пройти по всем элементам и сохранить индексы каждого значения в словарь. После обхода фильтруются элементы, у которых список индексов содержит более одного значения. Такой способ работает с любыми типами данных и не требует сторонних библиотек.
Можно ли определить повторяющиеся значения в массиве numpy и сразу получить их индексы?
Да, используя np.unique() с параметром return_counts=True, можно выделить повторяющиеся значения. Затем функция np.where() возвращает все позиции этих значений в массиве. Такой подход экономит время при работе с большими массивами, так как сразу исключает уникальные элементы.
Как использовать pandas для поиска индексов повторов в серии данных?
Метод duplicated() в pandas возвращает булев массив, показывающий повторяющиеся элементы. Передав параметр keep=False, можно отметить все повторы. Затем с помощью атрибута index извлекаются позиции повторяющихся значений, что удобно при фильтрации и анализе данных.
В чем преимущество использования словаря для группировки индексов одинаковых элементов?
Словарь позволяет сопоставить каждому значению список всех его индексов, что упрощает фильтрацию и сортировку повторов. Такой способ удобен, когда нужно видеть не только наличие дубликатов, но и их точное расположение, особенно при больших объемах данных.
Как отфильтровать и отсортировать индексы повторяющихся элементов по условию?
После получения всех индексов можно использовать списковые включения для фильтрации по любому критерию, например, выбрать индексы больше определённого значения. Затем функция sorted() упорядочивает их по возрастанию или убыванию. Такой метод позволяет сразу подготовить данные для анализа или дальнейшей обработки.
Как найти все индексы повторяющихся элементов в списке Python без использования сторонних библиотек?
Можно пройтись по списку с помощью цикла for и функции enumerate(), добавляя каждый индекс к словарю, где ключом будет значение элемента. После обхода словаря остаются только те элементы, у которых список индексов содержит более одного значения. Этот способ работает с любыми типами данных и показывает точное расположение дубликатов.
Можно ли с помощью pandas сразу определить все позиции повторяющихся значений в серии?
Да, метод duplicated() для pandas Series возвращает булев массив, где True указывает на повторяющиеся элементы. Если указать keep=False, будут отмечены все повторы, включая первое появление. Затем через атрибут index извлекаются индексы этих значений, что позволяет легко использовать их для фильтрации, сортировки или дальнейшего анализа.