В Python списки хранят элементы в упорядоченном виде, что позволяет обращаться к конкретным позициям с помощью индексов. Для поиска индекса определенного значения чаще всего используется метод list.index(), который возвращает позицию первого совпадения. Если элемент отсутствует, вызывается исключение ValueError, поэтому важно предусмотреть обработку ошибок.
Когда в списке присутствуют одинаковые элементы, метод index() возвращает только первый индекс. Чтобы получить все позиции значения, рекомендуется использовать функцию enumerate() в сочетании с генератором списка. Это позволяет быстро создавать список всех индексов без использования дополнительных циклов.
Для списков с вложенными структурами, например, списками или кортежами внутри списка, поиск индекса требует проверки элементов на соответствие заданному критерию. В таких случаях применяют условные выражения внутри генераторов и enumerate(), что дает возможность находить позиции элементов на любом уровне вложенности.
Использование этих подходов позволяет точнее управлять данными в списках и быстро получать информацию о расположении значений. В статье рассматриваются методы поиска индекса, обработка ошибок, работа с повторяющимися и вложенными элементами, что поможет применять Python списки в реальных задачах анализа и обработки данных.
Использование метода index() для поиска первого вхождения
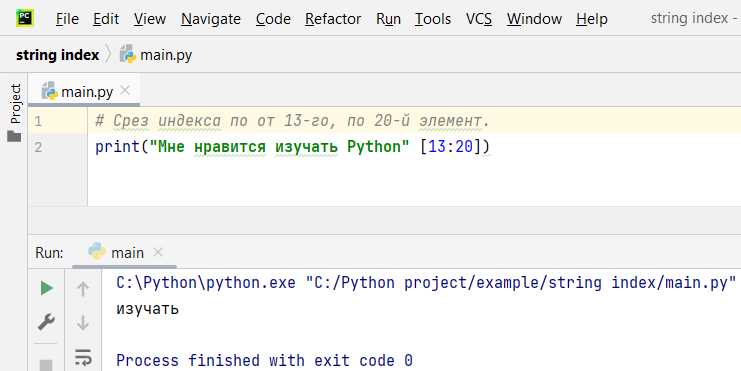
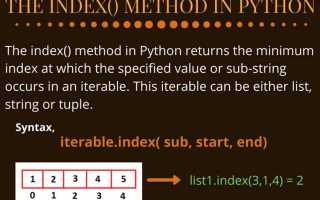
Метод list.index() возвращает индекс первого вхождения указанного значения в списке. Синтаксис метода: list.index(value, start, end), где value – элемент для поиска, start и end – необязательные параметры диапазона поиска.
Если элемент присутствует в списке, метод вернет его позицию в виде целого числа. Если значение отсутствует, Python вызовет исключение ValueError, поэтому рекомендуется использовать проверку наличия элемента перед вызовом метода.
Пример поиска первого вхождения:
| Список | Код | Результат |
|---|---|---|
| [10, 20, 30, 20, 40] | lst.index(20) | 1 |
| [‘apple’, ‘banana’, ‘apple’, ‘cherry’] | fruits.index(‘apple’) | 0 |
Использование параметров start и end позволяет ограничить поиск частью списка. Например, lst.index(20, 2) начнет поиск с индекса 2, что вернет индекс следующего вхождения значения, пропуская первые элементы.
Для безопасного использования метода в больших данных рекомендуется оборачивать вызов index() в блок try-except, чтобы избежать остановки программы при отсутствии элемента.
Поиск индекса при нескольких одинаковых значениях

Метод list.index() возвращает только первый индекс совпадения, что не подходит для списков с повторяющимися элементами. Чтобы получить все позиции значения, используют функцию enumerate() в сочетании с генератором списка или циклом.
Пример получения всех индексов числа 20 в списке:
lst = [10, 20, 30, 20, 40, 20]
indices = [i for i, x in enumerate(lst) if x == 20]
Результат: [1, 3, 5]
Использование enumerate() позволяет обходить список один раз, что экономит ресурсы при больших данных. Для больших массивов рекомендуется сразу формировать список индексов без дополнительных проверок и использовать встроенные функции фильтрации, чтобы избежать ручного перебора элементов.
Если необходимо найти индекс повторяющегося элемента начиная с конкретной позиции, можно комбинировать index() с параметром start в цикле до завершения всех вхождений. Такой подход упрощает обработку данных, когда важен порядок появления элементов.
Обработка ошибок при отсутствии элемента в списке
Метод list.index() вызывает ValueError, если запрашиваемого значения нет в списке. Для предотвращения остановки программы используют блок try-except, который позволяет обработать ошибку и задать альтернативное действие.
Пример безопасного поиска индекса:
lst = [5, 10, 15]
try:
index = lst.index(20)
except ValueError:
index = -1 # элемент не найден
Альтернативный способ – проверка наличия элемента с помощью in перед вызовом index(). Этот подход подходит, если требуется избежать использования исключений:
if 20 in lst:
index = lst.index(20)
else:
index = -1
При работе с динамическими или внешними данными рекомендуется комбинировать проверку с блоком try-except, чтобы гарантировать корректное выполнение кода независимо от содержимого списка.
Поиск индекса с помощью генераторов и enumerate()
Функция enumerate() позволяет обходить список с доступом к индексу и значению одновременно. В сочетании с генераторами можно быстро формировать список индексов, соответствующих определенному условию.
Пример поиска всех индексов элемента 30:
- Создаем список: lst = [10, 30, 20, 30, 40]
- Используем генератор: indices = [i for i, x in enumerate(lst) if x == 30]
- Результат: [1, 3]
Преимущества метода:
- Обход списка выполняется за один проход, экономя ресурсы.
- Позволяет включать сложные условия фильтрации прямо в генератор.
- Легко комбинируется с функциями map() и filter() для дальнейшей обработки данных.
Для поиска индекса первого совпадения с условием можно использовать встроенную функцию next() с генератором:
index = next((i for i, x in enumerate(lst) if x > 20), -1)
Результат: 1 – первый элемент, больше 20.
Такой подход удобен при работе с динамическими или большими списками, когда заранее неизвестно количество совпадений или порядок элементов.
Получение всех индексов заданного значения в списке
Для поиска всех позиций заданного значения в списке Python можно использовать цикл с функцией enumerate(). Этот метод возвращает индекс и значение элемента одновременно, что позволяет проверять каждый элемент на совпадение.
Пример реализации:
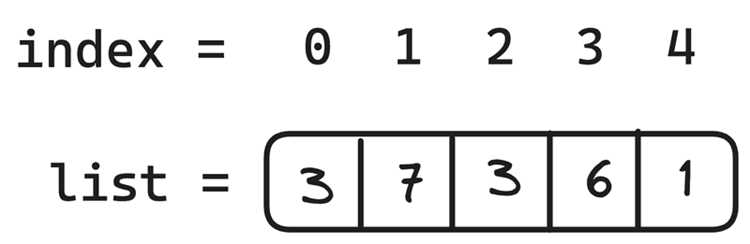
my_list = [3, 7, 2, 7, 5, 7]
value = 7
indices = [i for i, x in enumerate(my_list) if x == value]
print(indices) # Выведет [1, 3, 5]
Если список большой, генератор списка сохраняет производительность и экономит память, так как не требует создания промежуточных структур.
Альтернативный способ – использование функции numpy.where() для списков, преобразованных в массив NumPy. Это особенно удобно для числовых данных и позволяет получить индексы в виде массива:
import numpy as np
arr = np.array(my_list)
indices = np.where(arr == value)[0]
print(indices) # [1 3 5]
Для динамического поиска с возможностью многократного обновления списка можно использовать цикл с list.index(), двигаясь по списку с шагом:
indices = []
start = 0
while True:
try:
idx = my_list.index(value, start)
indices.append(idx)
start = idx + 1
except ValueError:
break
print(indices) # [1, 3, 5]
Выбор метода зависит от размера списка и требований к производительности: генератор списка подходит для большинства случаев, NumPy – для массивов с большим объемом данных, а list.index() удобен при необходимости последовательного поиска.
Применение поиска индекса в списках с вложенными элементами

Для списков, содержащих вложенные списки или кортежи, стандартный метод list.index() находит только первый уровень. Чтобы определить позицию элемента внутри вложенной структуры, требуется рекурсивный подход или обход с помощью циклов.
Пример поиска всех индексов для значения внутри вложенных списков:
nested_list = [[1, 2], [3, 4], [2, 5]]
value = 2
indices = [(i, j) for i, sublist in enumerate(nested_list) for j, x in enumerate(sublist) if x == value]
print(indices) # Выведет [(0, 1), (2, 0)]
Каждый элемент indices представляет кортеж (индекс_в_основном_списке, индекс_во_вложенном_списке). Такой подход позволяет точно идентифицировать местоположение значения в многомерных структурах.
Для произвольно вложенных списков рекомендуется использовать рекурсивную функцию:
def find_nested_indices(lst, val, path=()):
indices = []
for i, x in enumerate(lst):
current_path = path + (i,)
if isinstance(x, list):
indices.extend(find_nested_indices(x, val, current_path))
elif x == val:
indices.append(current_path)
return indices
nested_list = [[1, [2, 3]], [2, 4]]
print(find_nested_indices(nested_list, 2)) # [(0, 1, 0), (1, 0)]
Использование кортежей для хранения пути позволяет легко получить доступ к значению или заменить его, сохраняя структуру вложенности.
Для больших вложенных списков предпочтительно комбинировать генераторные выражения и рекурсию, чтобы минимизировать потребление памяти и обеспечить точный поиск индексов на всех уровнях.
Вопрос-ответ:
Как найти индекс первого вхождения значения в списке Python?
Для поиска первого вхождения используется метод list.index(). Он возвращает позицию первого совпадения. Например, my_list = [4, 7, 2, 7], my_list.index(7) вернёт 1. Если значения нет, возникает ValueError, поэтому рекомендуется использовать обработку исключений при неопределённом содержании списка.
Как получить все индексы заданного значения в списке?
Можно использовать генератор списка с enumerate(): indices = [i for i, x in enumerate(my_list) if x == value]. Этот метод возвращает список всех позиций элемента. Для больших списков он остаётся быстрым и не требует дополнительных библиотек.
Как искать значение в списках с вложенными элементами?
Стандартный list.index() работает только на первом уровне. Для вложенных списков применяется рекурсивная функция или двойной цикл с enumerate(). Каждый найденный индекс можно хранить в виде кортежа (индекс_основного_списка, индекс_вложенного_элемента) для точного указания позиции.
Можно ли использовать NumPy для поиска индексов в списках Python?
Да, если преобразовать список в массив NumPy, функция numpy.where() вернёт массив индексов всех вхождений значения. Пример: import numpy as np; arr = np.array(my_list); np.where(arr == value)[0]. Этот способ удобен для числовых данных и больших наборов, так как операции выполняются быстрее встроенных циклов.