Содержание статьи

Работа с повторяющимися данными – частая задача при анализе баз данных. SQL предоставляет инструменты для выделения уникальных записей, что позволяет сокращать объем выборки и повышать точность отчетов. На практике это особенно важно при построении списков клиентов, товаров или транзакций, где повторяющиеся записи искажают результаты.
Основной инструмент для получения уникальных значений – оператор DISTINCT. Он позволяет сразу исключить дубликаты из результата запроса по одной или нескольким колонкам. Например, SELECT DISTINCT city FROM customers; вернет все города, в которых есть клиенты, без повторов.
Для сложных случаев применяют GROUP BY, который группирует строки по указанным колонкам и дает возможность использовать агрегатные функции. Это удобно, когда необходимо одновременно получить уникальные комбинации полей и подсчитать количество повторов.
Особое внимание стоит уделить значениям NULL. В некоторых СУБД они учитываются как отдельные уникальные записи, что может влиять на результаты анализа. Планируя выборку, важно проверять, как конкретная база данных обрабатывает такие значения.
Использование подзапросов и соединений расширяет возможности работы с уникальными данными. Например, можно отфильтровать уникальные записи, основываясь на сложных условиях или связанных таблицах, что делает запросы более точными и прикладными для аналитики.
Использование DISTINCT для одной колонки
Оператор DISTINCT позволяет выбрать уникальные значения из одной колонки без дубликатов. Он применяется в конструкции SELECT DISTINCT column_name FROM table_name;. Например, запрос SELECT DISTINCT department FROM employees; вернет список всех отделов компании без повторяющихся записей.
При использовании DISTINCT важно учитывать размер таблицы. На больших наборах данных оператор может замедлять выполнение запроса, так как требуется сортировка или хеширование для выявления уникальных значений. В таких случаях стоит проверять наличие индекса на колонке, чтобы ускорить выборку.
DISTINCT игнорирует повторяющиеся строки только по указанной колонке. Если в таблице есть NULL значения, они учитываются как уникальные записи, что может повлиять на анализ. Для исключения NULL можно добавить условие WHERE column_name IS NOT NULL.
Практическая рекомендация: использовать DISTINCT для быстрого получения справочных списков, например, городов, категорий товаров или идентификаторов пользователей, когда важно убрать дубли и сразу получить чистый набор данных.
Выбор уникальных комбинаций нескольких колонок
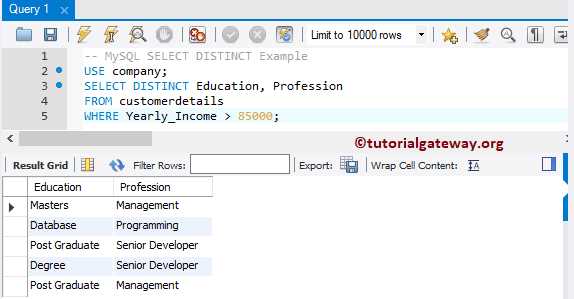
Для получения уникальных комбинаций нескольких колонок также используется оператор DISTINCT. Запрос строится так: SELECT DISTINCT column1, column2 FROM table_name;. Например, SELECT DISTINCT city, department FROM employees; вернет все уникальные пары «город–отдел».
Особенности применения:
- Каждая комбинация считается уникальной, даже если отдельные значения колонок повторяются.
- NULL значения в любой из колонок учитываются как отдельные уникальные записи.
- При больших таблицах рекомендуется использовать индексы по колонкам, участвующим в DISTINCT, для ускорения выборки.
Практические рекомендации:
- Использовать для анализа связей между полями, например, распределения сотрудников по отделам и городам.
- Применять при построении отчетов, где требуется исключить повторяющиеся комбинации признаков.
- Для сложных фильтров можно сочетать DISTINCT с WHERE или подзапросами, чтобы выбрать только нужные уникальные пары.
Фильтрация дубликатов с помощью GROUP BY
Оператор GROUP BY используется для группировки строк по одному или нескольким столбцам. Это позволяет фильтровать дубликаты, особенно в тех случаях, когда необходимо сгруппировать данные по определенному признаку и выполнить агрегатные функции.
Пример запроса, который группирует сотрудников по отделам, чтобы отобразить уникальные комбинации отдел–город:
SELECT department, city FROM employees GROUP BY department, city;В отличие от DISTINCT, GROUP BY позволяет также применять агрегатные функции, такие как COUNT(), SUM(), AVG(), для вычислений по каждой группе. Например, запрос, который подсчитывает количество сотрудников в каждом отделе:
SELECT department, COUNT(*) FROM employees GROUP BY department;Особенности:
- GROUP BY группирует строки по указанным колонкам, а не по всем строкам сразу.
- В запросах с GROUP BY всегда необходимо использовать агрегатные функции для колонок, не входящих в группировку.
- Использование HAVING позволяет фильтровать результаты группировки, например, отобрать только те группы, где количество сотрудников больше 10:
SELECT department, COUNT(*) FROM employees GROUP BY department HAVING COUNT(*) > 10;Пример таблицы с результатами запроса:
| Отдел | Город |
|---|---|
| Маркетинг | Киев |
| Продажи | Одесса |
| Разработка | Харьков |
Для фильтрации дубликатов в сложных запросах с несколькими колонками GROUP BY эффективно использовать вместе с агрегатными функциями и HAVING.
Применение подзапросов для уникальных значений

Подзапросы – мощный инструмент для получения уникальных значений, когда требуется более сложная фильтрация или агрегация данных. Подзапрос может быть использован для извлечения уникальных записей на основе вычислений или сравнений, которые невозможно выполнить в одном основном запросе.
Пример использования подзапроса для выборки уникальных значений в сочетании с агрегатной функцией:
SELECT city
FROM employees
WHERE department IN (SELECT DISTINCT department FROM employees);В этом примере основной запрос выбирает уникальные города, где работают сотрудники, чьи отделы также являются уникальными по отношению к исходной таблице.
Подзапросы могут быть полезны при необходимости получить уникальные значения, которые зависят от сложных условий. Например, для выбора уникальных значений в зависимости от конкретных условий:
SELECT name
FROM products
WHERE price > (SELECT AVG(price) FROM products);Этот запрос вернет уникальные имена товаров, чья цена выше средней по всем товарам в базе данных. Использование подзапроса позволяет более точно фильтровать данные на основе динамически вычисленных значений.
Особенности применения подзапросов для уникальных значений:
- Подзапросы могут быть использованы как в WHERE, так и в FROM, в зависимости от цели выборки.
- Подзапросы, используемые в WHERE, позволяют работать с уникальными значениями на уровне фильтрации, что может быть полезно при сравнении данных из разных таблиц или наборов данных.
- При использовании подзапросов важно учитывать их производительность, так как вложенные запросы могут увеличить время выполнения при работе с большими объемами данных.
Удаление повторов с JOIN и подзапросами
Для удаления дубликатов при объединении таблиц удобно использовать JOIN в сочетании с подзапросами. Такой подход позволяет выбрать уникальные записи по ключевым колонкам, исключив повторяющиеся строки, возникающие при соединении.
Пример: необходимо получить список уникальных клиентов с их последними заказами:
SELECT c.customer_id, c.name, o.order_id, o.order_date
FROM customers c
JOIN (
SELECT customer_id, MAX(order_date) AS last_order
FROM orders
GROUP BY customer_id
) o_max ON c.customer_id = o_max.customer_id
JOIN orders o ON o.customer_id = o_max.customer_id AND o.order_date = o_max.last_order;Здесь подзапрос выбирает последний заказ каждого клиента, что исключает повторяющиеся записи при JOIN с основной таблицей клиентов.
Рекомендации при использовании JOIN и подзапросов для удаления повторов:
- Использовать агрегатные функции (MAX, MIN) внутри подзапросов для определения уникальной записи.
- Обеспечивать точное соответствие ключей между подзапросом и основной таблицей, чтобы исключить множественные совпадения.
- Для больших таблиц добавлять индексы по колонкам соединения, чтобы снизить нагрузку на выполнение запроса.
Такой метод позволяет контролировать, какие дубликаты удаляются, и обеспечивает точную выборку уникальных записей даже при сложных связях между таблицами.
Использование функций агрегирования для уникальных записей
Функции агрегирования позволяют работать с уникальными значениями после группировки данных с помощью GROUP BY. Основные функции: COUNT, SUM, AVG, MIN, MAX. Они помогают подсчитывать, суммировать или анализировать уникальные записи.
Пример: подсчет количества уникальных клиентов по каждому городу:
SELECT city, COUNT(DISTINCT customer_id) AS unique_customers
FROM customers
GROUP BY city;В этом случае COUNT(DISTINCT customer_id) исключает повторяющиеся идентификаторы, возвращая точное количество уникальных клиентов.
Для суммирования уникальных значений можно использовать SUM(DISTINCT column):
SELECT department, SUM(DISTINCT salary) AS total_unique_salary
FROM employees
GROUP BY department;Такой подход исключает повторные суммы по одинаковым зарплатам в одном отделе.
Рекомендации:
- Использовать агрегатные функции с DISTINCT только по необходимым колонкам, чтобы не увеличивать нагрузку на базу.
- Комбинировать с GROUP BY для анализа уникальных комбинаций данных.
- Проверять наличие индексов по колонкам, участвующим в агрегатах, чтобы ускорить выполнение запросов.
Особенности работы с NULL при поиске уникальных значений
Значения NULL в SQL представляют отсутствие данных и рассматриваются как уникальные при использовании операторов DISTINCT и GROUP BY. Это означает, что несколько строк с NULL в одной колонке считаются разными уникальными записями.
Пример: выбор уникальных городов, включая NULL:
SELECT DISTINCT city
FROM customers;Если в таблице несколько клиентов не указали город, каждая строка с NULL будет отображена один раз как уникальное значение.
Для исключения NULL можно добавить фильтр:
SELECT DISTINCT city
FROM customers
WHERE city IS NOT NULL;Это позволяет получать только действительные значения и корректно подсчитывать уникальные записи без учета пустых полей.
Особенности использования с агрегатными функциями:
- COUNT(column) не учитывает NULL, тогда как COUNT(*) включает все строки.
- При группировке NULL формирует отдельную группу, что может влиять на подсчет и агрегацию.
- Рекомендуется явно фильтровать NULL при построении отчетов, чтобы избежать искажений данных.
Сравнение результатов DISTINCT и GROUP BY на практике
Операторы DISTINCT и GROUP BY часто используются для получения уникальных значений, но их применение и результат могут различаться в зависимости от задачи.
Особенности DISTINCT:
- Исключает дубликаты по указанным колонкам без группировки.
- Не требует использования агрегатных функций.
- Подходит для быстрого получения списка уникальных значений одной или нескольких колонок.
- Пример: SELECT DISTINCT department FROM employees; – вернет все уникальные отделы.
Особенности GROUP BY:
- Группирует строки по колонкам и позволяет использовать агрегатные функции для каждой группы.
- Возвращает уникальные комбинации колонок, но дополнительно предоставляет возможность вычислений, например, подсчет или сумма.
- Пример: SELECT department, COUNT(*) FROM employees GROUP BY department; – вернет уникальные отделы и количество сотрудников в каждом.
Практические рекомендации:
- Использовать DISTINCT, если нужно просто убрать повторяющиеся записи без дополнительных вычислений.
- Применять GROUP BY, если требуется анализировать данные с агрегатными функциями или фильтрацией по группам.
- На больших таблицах проверять наличие индексов по колонкам для ускорения работы обоих операторов.
- Сравнивать результаты на тестовых выборках, чтобы убедиться, что логика выборки уникальных значений соответствует задаче.
Вопрос-ответ:
В чем разница между DISTINCT и GROUP BY при выборе уникальных значений?
DISTINCT удаляет дубликаты по указанным колонкам и возвращает уникальные строки, не применяя агрегатные функции. GROUP BY группирует строки по колонкам и позволяет применять агрегатные функции к каждой группе, например, COUNT или SUM. Для простого списка уникальных значений достаточно DISTINCT, а для анализа с подсчетами или суммами лучше использовать GROUP BY.
Как учитывать NULL значения при поиске уникальных записей?
Значения NULL считаются уникальными при использовании DISTINCT и GROUP BY. Если несколько строк имеют NULL в одной колонке, каждая такая запись учитывается как отдельная уникальная. Чтобы исключить NULL, можно использовать условие WHERE column IS NOT NULL, что позволит получать только действительные значения без пустых полей.
Можно ли использовать агрегатные функции для подсчета уникальных значений?
Да, например, COUNT(DISTINCT column) позволяет посчитать количество уникальных значений в колонке. Также SUM(DISTINCT column) суммирует только разные значения, игнорируя повторяющиеся. Такие функции удобно использовать при анализе распределения данных или суммировании уникальных показателей.
Как удалять дубликаты при объединении нескольких таблиц?
Для этого можно применять JOIN вместе с подзапросами. Подзапросы позволяют выбрать уникальные ключи или последние записи, после чего соединять их с основной таблицей. Например, можно получить список клиентов с последними заказами, исключая повторяющиеся строки, используя подзапрос с MAX(order_date) и JOIN по customer_id.