Содержание статьи

Разделение списка на части – частая задача при обработке данных, работе с пакетной загрузкой, подготовке входных данных для функций и распределении вычислений. В Python список представляет собой упорядоченную коллекцию, поэтому разбиение почти всегда сводится к точному управлению индексами, длиной фрагментов и порядком элементов.
На практике применяются разные подходы: срезы, циклы, генераторы, стандартные модули. Каждый способ решает конкретную задачу – например, получить фрагменты фиксированного размера, разбить список на заданное число частей или корректно обработать остаток элементов. Неправильный выбор метода часто приводит к лишним копиям данных или ошибкам на границах.
В статье рассматриваются прикладные способы разбиения списков с примерами кода и пояснениями, когда и почему стоит использовать каждый из них. Отдельное внимание уделяется случаям, где длина списка заранее неизвестна, а также ситуациям, когда требуется поэлементная обработка без загрузки всех частей в память.
Материал ориентирован на работу с базовым типом list и стандартными возможностями Python без сторонних библиотек, что позволяет применять описанные приемы в скриптах, веб-приложениях и задачах автоматизации.
Разделение списка на равные части с помощью срезов
Срезы позволяют получить части списка по индексам без изменения исходных данных. При разбиении на равные фрагменты ключевым параметром становится длина каждой части, вычисляемая заранее на основе общего количества элементов.
Базовый подход строится на использовании шага в цикле range, где начальный индекс увеличивается на размер фрагмента. Каждый срез формируется выражением lst[i:i + size], что гарантирует сохранение порядка элементов.
lst = [1, 2, 3, 4, 5, 6, 7, 8]
size = 2
parts = [lst[i:i + size] for i in range(0, len(lst), size)]
В результате получается список частей одинаковой длины. Такой вариант подходит, если общее количество элементов кратно размеру фрагмента.
При разбиении на заданное число частей сначала рассчитывается длина одной части через целочисленное деление:
lst = list(range(10))
n = 5
size = len(lst) // n
parts = [lst[i * size:(i + 1) * size] for i in range(n)]
Этот способ требует проверки остатка элементов. Если длина списка не делится без остатка, последние элементы будут потеряны.
- Используйте срезы, когда нужен строгий контроль индексов
- Проверяйте кратность длины списка размеру части
- Для данных неизвестной длины добавляйте обработку остатка отдельно
Срезы возвращают новые списки, поэтому при работе с большими наборами данных стоит учитывать дополнительное потребление памяти.
Разбиение списка по фиксированному размеру шага
Фиксированный шаг применяется, когда список нужно разбить на последовательные фрагменты одинаковой длины без предварительного расчета количества частей. Шаг задается явно и определяет, сколько элементов попадает в одну часть.
На практике используется цикл с range, где третий аргумент задает шаг смещения индекса. Каждый проход формирует срез от текущей позиции до позиции, смещенной на заданное число элементов.
data = [10, 20, 30, 40, 50, 60, 70]
step = 3
chunks = [data[i:i + step] for i in range(0, len(data), step)]
Последний фрагмент может содержать меньше элементов, если длина списка не кратна шагу. Это поведение удобно при пакетной обработке, где важно не потерять данные.
- Шаг задается числом элементов в одной части
- Порядок элементов сохраняется без дополнительной логики
- Подходит для очередей задач, страниц результатов, пакетной отправки
При выборе размера шага стоит учитывать характер данных. Слишком малый шаг увеличивает количество частей, слишком большой усложняет последующую обработку.
Для читаемости кода рекомендуется выносить значение шага в отдельную переменную и не использовать «магические числа» прямо в выражении среза.
Деление списка на части разной длины по заданному шаблону

Шаблонное разбиение используется, когда структура данных заранее известна и каждая часть должна иметь строго определённую длину. В качестве шаблона выступает последовательность чисел, описывающая размеры фрагментов в том порядке, в котором они извлекаются из списка.
Алгоритм строится на последовательном сдвиге индекса. Начальная позиция обновляется после формирования каждой части, что позволяет точно контролировать границы срезов.
items = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
sizes = [1, 2, 3, 1]
parts = []
index = 0
for size in sizes:
parts.append(items[index:index + size])
index += size
Такой код читабелен и легко расширяется: изменение структуры данных требует правки только шаблона. При этом важно учитывать, что сумма значений шаблона напрямую влияет на результат.
Если шаблон превышает длину списка, срез вернёт меньше элементов без генерации исключений. Для явного контроля рекомендуется проверять остаток перед добавлением части.
remaining = len(items) - index
if remaining < size:
parts.append(items[index:])
break
Подход оправдан при работе с форматами данных, где каждая секция имеет фиксированный размер, а вычисление длины частей на лету усложняет код и повышает риск ошибок.
Использование цикла for для пошагового разбиения списка
Цикл for позволяет последовательно формировать части списка, управляя индексами вручную. Такой подход удобен, когда требуется гибкий контроль над длиной фрагментов и обработкой остатка элементов.
Для разбиения используется переменная-счетчик, которая указывает текущую позицию в списке. На каждом шаге формируется срез фиксированной длины, после чего индекс увеличивается на размер фрагмента.
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
chunk_size = 3
chunks = []
index = 0
for _ in range((len(data) + chunk_size - 1) // chunk_size):
chunks.append(data[index:index + chunk_size])
index += chunk_size
Метод автоматически корректно обрабатывает последний фрагмент, даже если в нём меньше элементов, чем заданный размер. Это исключает потерю данных и ошибки при доступе к индексам.
Рекомендуется использовать такой цикл, когда заранее неизвестна длина списка или необходимо динамически менять размер частей в процессе обработки.
Преимущество подхода в том, что код легко адаптировать под разные правила разбиения: можно изменять размер фрагмента на каждом шаге, добавлять условия для пропуска или объединения элементов.
Применение функции range для управления границами частей
Функция range позволяет точно задавать начальные и конечные индексы для срезов списка при его разбиении на части. Это даёт полный контроль над длиной фрагментов и количеством итераций цикла.
На практике используют третий аргумент range(start, stop, step), где step определяет размер каждого фрагмента. Такой подход исключает необходимость вручную обновлять индекс после каждого среза.
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
chunk_size = 4
parts = [numbers[i:i + chunk_size] for i in range(0, len(numbers), chunk_size)]
Если длина списка не делится на размер фрагмента, последний элемент обрабатывается автоматически: срез возвращает оставшиеся элементы без ошибок. Это удобно при работе с потоковыми данными или пакетной обработке.
При необходимости динамического изменения размеров частей можно вычислять step на каждом проходе цикла и подставлять его в range, что делает код более гибким.
Использование range рекомендуется, когда важен контроль границ срезов и порядок элементов. Метод прост в реализации и совместим со стандартными функциями Python для работы с последовательностями.
Разделение списка на N частей с учетом остатка элементов
Задача разделения списка на N частей часто требует учета остатка элементов, когда длина списка не делится нацело на количество частей. Правильное распределение гарантирует, что все элементы попадут в результат без потерь.
Один из подходов – вычислить размер каждой части через целочисленное деление и определить остаток с помощью оператора %. Остаток распределяется по первым частям, чтобы разница в длине фрагментов была минимальной.
data = [1, 2, 3, 4, 5, 6, 7]
n = 3
base_size = len(data) // n
remainder = len(data) % n
parts = []
start = 0
for i in range(n):
end = start + base_size + (1 if i < remainder else 0)
parts.append(data[start:end])
start = end
Этот метод обеспечивает равномерное распределение элементов: первые части получают по одному дополнительному элементу до исчерпания остатка. Такой подход полезен при пакетной обработке, параллельных вычислениях и генерации страниц с одинаковым количеством элементов.
При реализации стоит контролировать переменные start и end, чтобы исключить выход за границы списка. Код легко адаптируется под динамическое изменение N и под различные структуры данных.
Создание генератора для поочередного получения частей списка
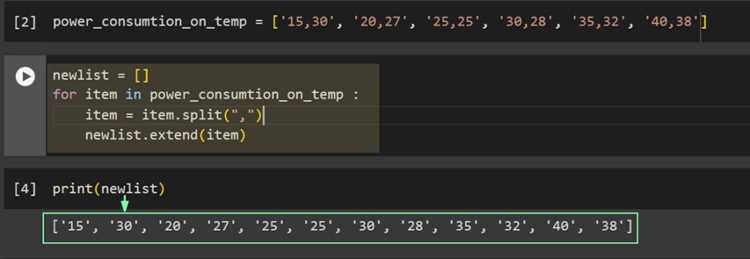
Генератор позволяет получать части списка по запросу, не создавая все фрагменты сразу в памяти. Это удобно при работе с большими массивами данных и потоковой обработке.
Для реализации используют функцию с yield, которая возвращает очередной срез и сохраняет состояние между вызовами.
def chunk_generator(lst, size):
for i in range(0, len(lst), size):
yield lst[i:i + size]
data = list(range(10))
gen = chunk_generator(data, 3)
for part in gen:
print(part)
Генератор экономит память, особенно если список содержит тысячи или миллионы элементов. Каждый вызов next() возвращает следующую часть без необходимости хранить весь набор фрагментов.
Для визуального анализа распределения элементов можно использовать таблицу, показывающую индекс фрагмента и его содержимое:
| Номер части | Элементы |
|---|---|
| 1 | [0, 1, 2] |
| 2 | [3, 4, 5] |
| 3 | [6, 7, 8] |
| 4 | [9] |
Генераторы удобно комбинировать с условной логикой, фильтрацией и динамическим изменением размера частей, что делает их универсальным инструментом для последовательной обработки данных.
Разбиение списка с помощью стандартных модулей Python
Стандартные модули Python предоставляют готовые инструменты для разбиения списков, что снижает количество ручного кода и повышает читаемость. Один из таких модулей – itertools, который позволяет работать с итераторами и создавать генераторы фрагментов.
Например, функция islice из itertools позволяет извлекать части списка по индексам без копирования всего набора данных:
from itertools import islice
def chunk_itertools(lst, size):
it = iter(lst)
while True:
part = list(islice(it, size))
if not part:
break
yield part
data = list(range(8))
for chunk in chunk_itertools(data, 3):
print(chunk)
Результат аналогичен срезам и генераторам, но использование islice делает обработку больших списков более экономной по памяти и удобной для потоковой передачи данных.
Кроме itertools, модуль math полезен для вычисления размеров частей, если нужно разделить список на N фрагментов с учетом остатка элементов:
import math
data = list(range(10))
n = 3
chunk_size = math.ceil(len(data) / n)
parts = [data[i:i + chunk_size] for i in range(0, len(data), chunk_size)]
Стандартные модули позволяют создавать компактные и понятные решения для различных сценариев разбиения списков без сторонних библиотек. Это повышает переносимость кода и упрощает его поддержку.
Вопрос-ответ:
Как разделить список на равные части в Python?
Для разбиения списка на равные части можно использовать срезы и цикл. Сначала вычисляют размер части, затем формируют новые списки через выражение lst[i:i + size] с шагом в цикле. Это сохраняет порядок элементов и подходит для списков, длина которых кратна размеру части. Если длина не кратна, последний фрагмент может быть короче.
Можно ли разделить список на N частей с учетом остатка элементов?
Да, для этого сначала вычисляют базовый размер части через целочисленное деление длины списка на N и остаток через оператор %. Остаток распределяют по первым частям, чтобы разница в длине между фрагментами была минимальной. Такой подход гарантирует, что все элементы попадут в результат.
Как использовать генератор для поочередного получения частей списка?
Генератор создается через функцию с yield, которая возвращает очередной срез списка. Это позволяет экономить память: фрагменты формируются по мере обращения к генератору и не хранятся все сразу. Генераторы удобны при работе с большими данными или потоковой обработке.
Какие стандартные модули Python помогают при разбиении списка?
Модуль itertools предоставляет функции для работы с итераторами, например islice, позволяющий получать срезы без копирования всего списка. Модуль math полезен для вычисления размера частей при делении на N фрагментов, особенно если нужно учесть остаток элементов. Эти модули сокращают код и упрощают обработку больших данных.
Как разделить список на части разной длины по заданному шаблону?
Шаблон задают в виде списка чисел, где каждое значение определяет размер очередной части. С помощью цикла и переменной-счетчика формируют срезы от текущего индекса на длину, указанную в шаблоне, после чего индекс сдвигается. Такой метод позволяет точно контролировать границы фрагментов и сохранить порядок элементов.
Как можно разделить список на несколько частей в Python, чтобы все элементы остались и части были примерно одинакового размера?
Для такого разбиения сначала вычисляют базовый размер части через целочисленное деление длины списка на количество фрагментов. Остаток элементов распределяют по первым частям, чтобы длина частей отличалась не более чем на один элемент. Например, если список из 10 элементов нужно разделить на 3 части, базовый размер будет 3, а остаток 1. Первые 1 часть получит 4 элемента, оставшиеся по 3 элемента. В Python это можно реализовать через цикл, формируя срезы от текущего индекса до индекса плюс размер части, и обновляя индекс после каждой итерации. Такой подход гарантирует, что ни один элемент не будет потерян, и все части будут максимально равномерными.