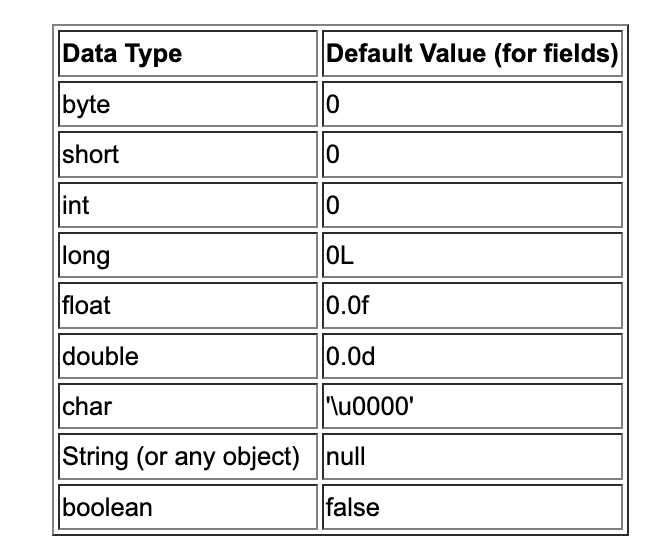
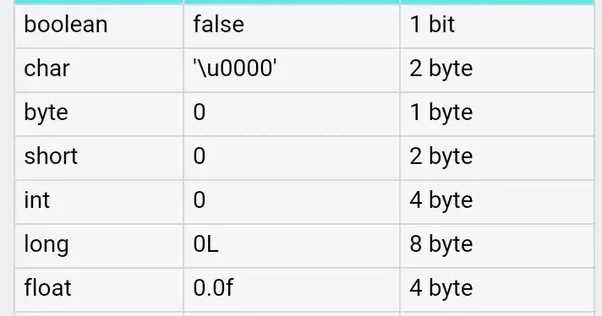
Примитивные типы данных в Java включают восемь базовых категорий: byte, short, int, long, float, double, char и boolean. Каждый из них имеет фиксированный размер памяти и диапазон значений, что напрямую влияет на производительность и корректность вычислений. Например, int занимает 4 байта и поддерживает значения от -2 147 483 648 до 2 147 483 647, тогда как byte ограничен диапазоном от -128 до 127 и может использоваться для хранения небольших числовых данных в массивах, экономя память.
При работе с дробными числами важно понимать различие между float и double. Float занимает 4 байта и обеспечивает точность примерно до 7 значащих цифр, тогда как double использует 8 байт и позволяет работать с 15–16 значащими цифрами. Неправильный выбор типа может привести к накоплению ошибок при сложных вычислениях, особенно в финансовых или научных приложениях.
Тип char хранит один 16-битный символ Unicode, что позволяет корректно работать с многоязычными текстами. Для логических условий используется boolean, который может принимать только значения true или false, и его правильное применение критично при построении условных операторов и циклов. Понимание особенностей каждого типа позволяет не только оптимизировать использование памяти, но и избегать ошибок переполнения, неточных расчетов и неожиданных преобразований типов.
Помимо размеров и диапазонов, важно учитывать механизм автоупаковки и распаковки примитивов, когда объекты обертки автоматически конвертируются в соответствующие примитивные типы и обратно. Неправильное использование этих механизмов может создавать лишние объекты и увеличивать нагрузку на сборщик мусора, особенно при работе с большими коллекциями данных.
Изучение особенностей примитивных типов данных позволяет принимать обоснованные решения при проектировании алгоритмов и структур данных, снижая риск ошибок и обеспечивая предсказуемое поведение программы в разных условиях выполнения.
Когда использовать byte и short вместо int
Тип byte занимает 1 байт и хранит значения от -128 до 127, а short использует 2 байта с диапазоном от -32 768 до 32 767. Их применение оправдано в ситуациях, когда объем данных велик, а значения не превышают указанные пределы. Например, при работе с массивами для хранения миллионов небольших чисел использование byte или short позволяет существенно снизить потребление памяти по сравнению с int, который занимает 4 байта.
Применение byte эффективно при обработке бинарных данных, таких как сетевые пакеты или файлы изображений, где каждый элемент представляет собой одно значение в пределах 0–255. Для хранения небольших числовых показателей, например, возраста пользователей или количества товаров на складе, short обеспечивает баланс между диапазоном и экономией памяти.
Важно учитывать, что при арифметических операциях byte и short автоматически приводятся к int, что может создавать необходимость явного приведения типов при присваивании результата. Невнимательное обращение к этим особенностям может привести к ошибкам компиляции или неожиданным результатам при переполнении диапазона.
Использование byte и short оправдано там, где критична экономия памяти и значения остаются в пределах допустимого диапазона. В остальных случаях предпочтительнее int, так как он обеспечивает более безопасные вычисления и совместимость с большинством стандартных библиотек Java.
| Тип | Размер | Диапазон значений | Применение |
|---|---|---|---|
| byte | 1 байт | -128…127 | Массивы больших объемов, обработка бинарных данных, маленькие счетчики |
| short | 2 байта | -32 768…32 767 | Массивы чисел среднего диапазона, показатели, где int избыточен |
| int | 4 байта | -2 147 483 648…2 147 483 647 | Стандартные вычисления, безопасные арифметические операции, большинство библиотек |
Отличия float и double при вычислениях с дробными числами
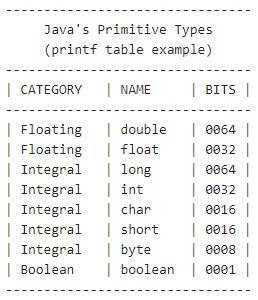
Тип float занимает 4 байта и обеспечивает точность примерно до 7 значащих цифр, тогда как double использует 8 байт с точностью до 15–16 значащих цифр. При вычислениях с большими или очень маленькими числами float может давать заметные погрешности, особенно при последовательных арифметических операциях.
Выбор между float и double определяется требованиями к точности и объемом памяти. Float подходит для графики, игр и других задач, где небольшие ошибки не критичны и важна экономия памяти. Double необходим в финансовых, научных и инженерных вычислениях, где накопление ошибок недопустимо.
При сравнении дробных чисел необходимо учитывать ограничение точности. Например, выражение (0.1 + 0.2 == 0.3) может вернуть false при использовании float из-за округления, тогда как double уменьшает вероятность таких ошибок. Для безопасного сравнения рекомендуется использовать диапазон допустимой погрешности.
Следует учитывать, что арифметические операции между float и double автоматически приводят результат к типу double. Это важно при присваивании значения переменной float, так как требуется явное приведение типа, иначе возникнет ошибка компиляции.
Использование float оправдано при ограниченных ресурсах памяти и допустимой погрешности, double – при необходимости высокой точности и надежных расчетов. Понимание этих различий позволяет избежать неожиданных ошибок при работе с дробными числами и оптимально распределять ресурсы приложения.
Правила работы с char и Unicode символами
Тип char в Java занимает 2 байта и хранит один символ в формате UTF-16, что позволяет представлять все стандартные символы Unicode, включая латиницу, кириллицу и специальные знаки. Каждый char фактически хранит числовой код символа, что позволяет выполнять арифметические операции и сравнения на уровне кодов.
При работе с текстом важно учитывать, что некоторые символы Unicode представлены парой char (суррогатная пара). Это означает, что длина строки методом length() может быть больше, чем количество визуально отображаемых символов. Для корректной обработки таких символов рекомендуется использовать методы класса Character или String.codePointAt().
Присваивание символов выполняется через одинарные кавычки, например: char c = ‘A’;. Символы также можно задавать через числовой код Unicode: char c = ‘\u0410’; – это кириллическая буква А. Такой способ удобен для работы с международными текстами и при необходимости явного указания кодов символов.
Сравнение char осуществляется напрямую по их числовым кодам. Это позволяет сортировать символы, проверять диапазоны и выполнять математические операции. Для проверки типа символа (цифра, буква, пробел) рекомендуется использовать статические методы класса Character, такие как isDigit(), isLetter() и isWhitespace().
Правильное использование char и понимание структуры Unicode предотвращает ошибки при работе с многоязычными строками и обеспечивает корректное отображение символов в интерфейсе и при обработке данных.
Использование boolean в условных выражениях и циклах
Тип boolean в Java принимает только два значения: true и false. Он используется для управления потоками выполнения программы, таких как условные операторы if, else и логические циклы while и for. Применение boolean позволяет явно задавать условия и исключает необходимость использовать числовые значения для логики.
При построении сложных условий рекомендуется комбинировать boolean-переменные с логическими операторами && (и), || (или) и ! (не). Это упрощает чтение кода и снижает риск ошибок при проверке нескольких условий одновременно. Например, if (isActive && hasPermission) четко отражает смысл проверки, избегая лишних числовых сравнений.
В циклах boolean часто используется для организации повторяющихся операций до наступления определенного состояния. Например, переменная found может контролировать завершение поиска в массиве или списке: while (!found) { … }. Такой подход делает код предсказуемым и легко масштабируемым.
При работе с boolean важно избегать избыточных сравнений с true или false. Выражение if (flag == true) можно заменить на if (flag), а if (flag == false) на if (!flag). Это упрощает код и уменьшает вероятность ошибок при чтении или модификации программы.
Использование boolean-переменных в условных выражениях и циклах повышает прозрачность логики программы, обеспечивает точный контроль над ветвлением и позволяет легко масштабировать и поддерживать код.
Автоупаковка и распаковка примитивов в Java
Автоупаковка и распаковка упрощают работу с коллекциями, такими как ArrayList или HashMap, которые могут хранить только объекты. Это позволяет хранить примитивы без явного создания объектов и конверсии вручную, но требует внимания к производительности: каждая упаковка создает объект в памяти, что увеличивает нагрузку на сборщик мусора при больших объемах данных.
При арифметических операциях с объектами-обертками Java автоматически выполняет распаковку. Например, выражение Integer a = 10; Integer b = 20; int sum = a + b; сначала распакует a и b в int, выполнит сложение и присвоит результат переменной sum. Это облегчает использование примитивов в сложных вычислениях без явного вызова методов intValue() или doubleValue().
Следует учитывать, что частая автоупаковка больших массивов или коллекций может приводить к замедлению программы из-за создания множества временных объектов. В таких случаях лучше использовать примитивные массивы или специализированные коллекции, поддерживающие примитивы напрямую, например IntStream или сторонние библиотеки.
Понимание механизмов автоупаковки и распаковки позволяет безопасно использовать примитивы с объектами, оптимизировать память и избегать скрытых накладных расходов при работе с коллекциями и арифметикой.
Особенности переполнения и ограничения числовых типов
Все числовые примитивные типы Java имеют фиксированный размер и диапазон значений. При выходе за пределы этого диапазона возникает переполнение, которое не вызывает ошибок компиляции, но изменяет результат арифметической операции. Например, int x = 2_147_483_647 + 1; даст значение -2_147_483_648.
При работе с переполнением важно учитывать следующие моменты:
- Переполнение byte и short происходит быстрее, чем int или long, но диапазон значений намного меньше: byte -128…127, short -32 768…32 767.
- Для long переполнение наступает при превышении ±9 223 372 036 854 775 807, что редко встречается в стандартных приложениях, но важно для финансовых вычислений с большими суммами.
- Типы с плавающей точкой float и double также имеют ограничения по диапазону и точности. Слишком большие или слишком маленькие значения приводят к Infinity или NaN.
Рекомендации при работе с числовыми типами:
- Использовать тип с запасом диапазона, если возможны большие значения или накопление чисел.
- Для критичных вычислений применять проверки переполнения: сравнивать с MAX_VALUE и MIN_VALUE перед операциями.
- При последовательных вычислениях с дробными числами выбирать double для уменьшения ошибок округления.
- Для массивов или больших коллекций чисел учитывать память и переполнение при выборе byte, short или int.
Понимание переполнения и ограничений числовых типов позволяет создавать надежные вычислительные алгоритмы, предотвращать неожиданные ошибки и контролировать точность результатов.
Сравнение числовых типов и приведение типов
В Java числовые примитивы различаются по размеру и точности: byte, short, int, long, float, double. При сравнении разных типов компилятор автоматически приводит значения к более широкому типу, чтобы избежать потери данных. Например, при сравнении int и double int преобразуется в double.
Явное приведение типов (casting) необходимо, когда требуется присвоить значение более широкого типа переменной с меньшим диапазоном. Например, int x = (int) 3.7; приводит к усечению дробной части. Неправильное приведение может вызвать потерю данных или переполнение.
При арифметических операциях соблюдаются следующие правила:
- Если хотя бы один операнд типа double, результат будет double.
- Если операнды float и long, результат преобразуется к float, так как float способен хранить больше значащих цифр с плавающей точкой.
- Операции с byte и short автоматически повышаются до int.
Для безопасного сравнения дробных чисел рекомендуется учитывать погрешность, создаваемую float или double, и использовать диапазон допустимого отклонения вместо прямого сравнения на равенство.
Понимание правил приведения и сравнения числовых типов позволяет контролировать точность вычислений, предотвращать переполнение и избегать неожиданных результатов при смешанных операциях.
Выбор примитивного типа для памяти и производительности

Выбор подходящего примитивного типа в Java влияет на потребление памяти и скорость выполнения программы. Типы меньшего размера занимают меньше памяти и ускоряют работу с массивами и коллекциями, но ограничены диапазоном значений.
Рекомендации по выбору:
- Использовать byte для хранения чисел в диапазоне -128…127, например, флаги или коды состояния.
- Short подходит для небольших числовых данных, где требуется экономия памяти при больших массивах (например, температуры или счетчики до 32 767).
- Для большинства целочисленных операций применять int, так как он обеспечивает оптимальный баланс между диапазоном и производительностью на современных процессорах.
- Выбирать long только при работе с большими значениями, превышающими предел int (например, финансовые расчеты, метки времени в миллисекундах).
- Для дробных чисел использовать float при ограниченной памяти и допустимой погрешности, а double – для точных вычислений с накоплением ошибок.
- При работе с массивами больших объемов и коллекциями учитывать, что автоупаковка примитивов в объекты снижает производительность, поэтому предпочтительнее использовать примитивные массивы.
Оптимальный выбор типа позволяет снизить нагрузку на память, ускорить арифметические операции и уменьшить накладные расходы на преобразование типов и сборку мусора.
Вопрос-ответ:
В каких случаях имеет смысл использовать byte или short вместо int?
Byte и short занимают меньше памяти, чем int, поэтому их стоит применять при работе с большими массивами небольших чисел. Например, для хранения флагов, кодов состояния, счетчиков до 127 или 32 767 использование byte или short позволяет экономить память и ускоряет работу с массивами. При этом важно учитывать автоматическое приведение этих типов к int в арифметических операциях, чтобы избежать ошибок компиляции.
Почему результаты сложения float и double могут отличаться от ожидаемых?
Float и double имеют ограниченную точность. Float хранит около 7 значащих цифр, double — около 15–16. При сложении дробных чисел могут возникать погрешности, особенно если сумма чисел сильно отличается по порядку величины. Например, выражение 0.1f + 0.2f может дать не точное 0.3 из-за округления. Double уменьшает вероятность ошибки, но полностью исключить ее нельзя. Для сравнения дробных чисел лучше использовать диапазон допустимой погрешности.
Как правильно работать с символами Unicode в Java?
Тип char хранит один 16-битный символ UTF-16, что позволяет представлять большинство символов Unicode. При работе с редкими символами, которые занимают два char (суррогатные пары), методы типа length() могут возвращать большее число, чем визуальных символов. Для корректной обработки таких символов используют методы класса Character или String.codePointAt(). Присваивать символы можно через одинарные кавычки или через Unicode-коды, например, char c = ‘\u0410’.
Как влияет автоупаковка и распаковка примитивов на производительность программы?
Автоупаковка превращает примитив в объект-обертку, распаковка делает обратное. При работе с коллекциями это упрощает код, но создает дополнительные объекты в памяти. Если массив или коллекция содержит миллионы элементов, частая автоупаковка может увеличить нагрузку на сборщик мусора и замедлить выполнение. Для больших наборов данных лучше использовать примитивные массивы или специализированные структуры, поддерживающие примитивы напрямую.
Что нужно учитывать при сравнении числовых типов и приведении их к другому типу?
При смешанных операциях Java автоматически повышает тип к более широкому, чтобы сохранить точность. Например, int и double в операции будут приведены к double. Явное приведение требуется, если нужно присвоить результат более узкому типу, например, double к int. При этом дробная часть отбрасывается. Также важно учитывать переполнение при уменьшении диапазона и возможное накопление ошибок при операциях с числами с плавающей точкой.
В чем разница между float и double при точных вычислениях?
Float хранит числа с плавающей точкой в 4 байта и обеспечивает точность примерно до 7 значащих цифр, а double использует 8 байт и сохраняет около 15–16 значащих цифр. При сложении или делении чисел float могут возникать заметные ошибки округления, особенно при работе с числами разного порядка величины. Double снижает вероятность таких ошибок, но арифметические операции с ним занимают больше памяти и могут быть медленнее на старых процессорах.
Какие ошибки могут возникнуть при переполнении числовых типов?
Переполнение происходит, когда значение переменной превышает допустимый диапазон типа. Например, int хранит числа от -2 147 483 648 до 2 147 483 647. Если результат сложения выходит за эти пределы, число «оборачивается» в отрицательное или положительное значение, что может привести к некорректным расчетам. Подобное может произойти с byte, short и long. Чтобы избежать ошибок, перед операциями с большими числами рекомендуется проверять диапазон и при необходимости использовать тип с большим размером.