Содержание статьи

Выбор правильного типа данных для ключей в таблицах критически влияет на производительность и целостность базы данных. Наиболее распространённые типы включают целочисленные значения, строки фиксированной длины и универсальные уникальные идентификаторы (UUID). Целые числа занимают меньше памяти и обеспечивают быстрый доступ при индексировании, что делает их оптимальными для автоинкрементных первичных ключей.
Строковые ключи применяются, когда требуется человекочитаемый идентификатор, например, код продукта или серийный номер. Важно заранее определить фиксированную длину строки, чтобы снизить фрагментацию индексов и ускорить операции поиска. Использование переменной длины допустимо, но оно может увеличить нагрузку на память и время выполнения запросов.
UUID представляют собой 128-битные значения, которые гарантируют глобальную уникальность. Они полезны в распределённых системах, где ключи создаются на разных серверах. Однако при использовании UUID стоит учитывать, что индексирование таких ключей может быть менее эффективным из-за их случайной природы, и иногда рекомендуется применять сортировку или комбинированные ключи для оптимизации производительности.
При проектировании базы данных следует также оценивать возможность использования составных ключей, где уникальность обеспечивается комбинацией нескольких полей. Такой подход подходит для сложных сущностей, но требует внимательного анализа индексов и типов данных каждого компонента, чтобы избежать избыточного потребления ресурсов и замедления операций.
Использование числовых типов для первичных ключей
Использование автоинкрементных числовых ключей упрощает добавление новых записей. Автоинкремент гарантирует уникальность ключа без необходимости ручного контроля, а также минимизирует вероятность конфликтов при одновременном доступе нескольких пользователей.
При выборе типа ключа следует учитывать максимальный объем данных:
- SMALLINT – до 32 767 записей (2 байта);
- INT – до 2 147 483 647 записей (4 байта);
- BIGINT – до 9 223 372 036 854 775 807 записей (8 байт).
Числовые ключи позволяют оптимизировать работу индексов и соединений таблиц. Сравнение чисел всегда быстрее, чем строк, а последовательные значения повышают эффективность B-деревьев индексов. Это критично для таблиц с большим количеством JOIN-операций.
Рекомендуется использовать числовые типы для всех таблиц, где ключи не должны содержать семантическую информацию. В случаях, когда требуется распределение данных по нескольким серверам, целесообразно выбирать BIGINT с определенными масками для разделения диапазонов, чтобы избежать коллизий при масштабировании.
Строковые ключи: когда применять и как хранить

Строковые ключи оптимальны для идентификации сущностей, когда значения имеют естественное уникальное представление, например, email пользователя, VIN автомобиля или UUID в текстовом формате. Их использование оправдано, если числовой код не несет семантической информации и создание отдельного автоинкрементного идентификатора усложнит логику.
При выборе строкового ключа важно учитывать длину значения. Короткие ключи до 16–32 символов сохраняют эффективность индексации, тогда как длинные строки свыше 128 символов замедляют поиск и увеличивают нагрузку на хранение. Для длинных текстовых идентификаторов лучше использовать хеш-функции с фиксированной длиной, сохраняя при этом возможность обратной идентификации.
Хранение строковых ключей в базах данных следует оптимизировать через типы данных, поддерживающие точную длину, например CHAR для фиксированных и VARCHAR для переменных. Для часто изменяемых ключей VARCHAR предпочтительнее, так как уменьшает фрагментацию страниц и снижает накладные расходы на хранение.
Для индексации строковых ключей рекомендуется использование B-деревьев или hash-индексов. B-деревья подходят для диапазонных запросов и сортировки, hash-индексы обеспечивают быстрый точечный поиск, но не поддерживают эффективное сравнение диапазонов.
В распределенных системах ключи строкового типа удобны для шардирования. При использовании UUID или хешей от значений можно равномерно распределять записи между узлами без конфликтов и горячих точек, что минимизирует дисбаланс нагрузки.
При проектировании схемы стоит учитывать стандартизацию формата ключа и избегать смешанных регистров, пробелов и специальных символов, так как это повышает вероятность коллизий и ошибок при синхронизации. В ряде случаев полезно хранить ключи в виде хешей вместе с оригиналом для ускорения поиска и проверки уникальности.
UUID как уникальный идентификатор записей
UUID (Universally Unique Identifier) представляет собой 128-битное число, предназначенное для глобальной уникальной идентификации объектов. Его основное преимущество – практически нулевая вероятность коллизий даже при распределённых системах.
Структура UUID делится на пять групп шестнадцатеричных чисел, разделённых дефисами, например: 550e8400-e29b-41d4-a716-446655440000. Каждый сегмент несёт информацию о версии UUID и случайной или основанной на времени генерации части.
Существует несколько стандартных версий UUID:
- Версия 1 – основана на времени и MAC-адресе устройства.
- Версия 3 и 5 – создаются на основе хеширования имени и пространства имён с MD5 или SHA-1.
- Версия 4 – полностью случайная генерация, самая распространённая для баз данных.
В базах данных UUID часто используют как первичный ключ вместо автоинкрементного целого числа. Это особенно полезно, если требуется синхронизация данных между разными серверами или распределёнными приложениями без конфликта идентификаторов.
Рекомендации при использовании UUID:
- Использовать тип данных native UUID, если СУБД поддерживает (например, PostgreSQL `uuid`).
- При генерации версии 4 обеспечить криптографически стойкий источник случайных чисел.
- Избегать строковых представлений для индексации в больших таблицах из-за увеличения размера индекса.
- Для распределённых систем сочетать UUID с коротким локальным идентификатором для оптимизации производительности.
UUID сохраняет уникальность даже при экспорте данных в другие системы и позволяет создавать ссылки на записи без зависимости от структуры таблиц или сервера. Это упрощает миграцию и интеграцию.
Недостатки UUID:
- Больший размер по сравнению с обычными целыми ключами (16 байт против 4–8 байт).
- Случайная генерация версии 4 приводит к хаотичной структуре индекса, что может замедлять вставку больших объёмов данных.
Использование UUID оправдано там, где важна глобальная уникальность и независимость от конкретной базы данных, а также при проектировании распределённых приложений и микросервисов, где стандартные автоинкременты создают ограничения и риски конфликтов.
Составные ключи: выбор нескольких столбцов
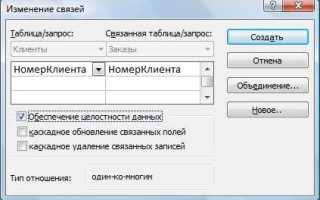
Составной ключ формируется из двух и более столбцов таблицы, когда отдельные поля не обеспечивают уникальности записей. Например, в таблице заказов комбинация OrderID и ProductID гарантирует, что каждая позиция заказа уникальна, даже если один заказ включает несколько товаров.
При выборе столбцов для составного ключа важно учитывать стабильность данных. Нельзя использовать поля, значения которых часто меняются, такие как статус заказа или дата последнего обновления, иначе целостность ссылок нарушится и индексы станут неэффективными.
Лучше всего включать в составной ключ комбинацию числовых и строковых идентификаторов с ограниченной длиной. Это ускоряет поиск и уменьшает нагрузку на индексацию. Например, комбинация CustomerID и InvoiceNumber в системе биллинга обеспечивает высокую производительность при выборках по клиентам и счетам.
При проектировании важно минимизировать количество столбцов в ключе. Слишком длинные составные ключи затрудняют JOIN-операции и увеличивают размер внешних ключей. Практика показывает, что двух-трех столбцов обычно достаточно для большинства сценариев, а дополнительные уникальные идентификаторы лучше вынести в отдельное поле.
Для обеспечения удобства использования составных ключей рекомендуется документировать их назначение и ограничения. Это помогает разработчикам корректно строить запросы, избегать дублирования данных и упрощает поддержку сложных связей между таблицами, особенно при масштабировании базы данных.
Дата и время в качестве ключей: ограничения и риски
Использование полей типа DATETIME или TIMESTAMP в качестве первичных ключей может привести к проблемам с уникальностью. Даже миллисекундные различия могут не гарантировать уникальность при массовой записи данных, особенно если транзакции выполняются параллельно на высоконагруженных системах. Рекомендуется применять дополнительные идентификаторы или комбинированные ключи, чтобы исключить коллизии.
Еще одним ограничением является точность хранения. В MySQL, например, стандартный TIMESTAMP хранит время с точностью до секунды, а DATETIME – до секунд с возможностью микросекунд только в версиях 5.6+. Это значит, что при попытке использовать эти поля как уникальные ключи для событий, происходящих чаще одного раза в секунду, возникает риск дублирования.
При использовании временных полей в качестве ключей важно учитывать часовые пояса и переход на летнее/зимнее время. Неправильная нормализация времени может привести к ошибкам при сопоставлении ключей и неконсистентности данных. Лучшей практикой считается хранение времени в UTC и преобразование в локальное только при отображении.
Также существует риск проблем с производительностью. Индексирование поля DATETIME увеличивает размер индекса и замедляет операции вставки и обновления, особенно на больших таблицах с миллионами строк. Комбинированные ключи с автоинкрементным идентификатором позволяют сохранить уникальность без существенного влияния на скорость запросов.
В качестве рекомендации, если временные данные нужны для идентификации записей, лучше создавать отдельное поле с уникальным идентификатором, а временной столбец использовать только для фильтрации и сортировки. Это снижает вероятность коллизий, упрощает масштабирование и делает структуру таблицы более предсказуемой при миграциях и репликации.
Булевы значения и их пригодность для идентификации

Булевы значения представляют собой два состояния: true и false. В контексте ключей таблиц они обладают высокой экономичностью по памяти, занимая минимальный объем, но одновременно крайне ограничены в уникальности. Использование булевых полей в качестве первичных ключей эффективно только при очень малом наборе записей.
Главный недостаток булевых ключей – невозможность однозначного различения более двух строк. Для таблиц с количеством записей больше двух булевый ключ полностью теряет идентифицирующую ценность, что делает его непригодным для стандартных операций связывания с другими таблицами.
Однако булевы значения могут быть полезны в составе составного ключа. Например, объединение булевого поля с числовым идентификатором или строковым кодом повышает уникальность, позволяя сохранять компактность хранения и при этом обеспечивать однозначное распознавание каждой строки.
При проектировании схемы базы данных следует учитывать, что индексация булевых полей часто неэффективна. Диапазон значений слишком узок, что приводит к частым сканированиям таблиц вместо прямого поиска по индексу, особенно в крупных базах данных с миллионами записей.
Булевы ключи могут быть оправданы для служебных или вспомогательных таблиц с ограниченным числом записей. Например, таблицы конфигураций или флагов состояния, где количество строк не превышает двух-трех, и требуется минимальный объем хранения.
Резюмируя, булевы значения не подходят для одиночной идентификации в массовых таблицах, но сохраняют практическую ценность в комбинации с другими полями. Рекомендовано использовать их как часть составного ключа или для малых справочников, где уникальность легко гарантируется.
Вопрос-ответ:
Какие типы данных чаще всего используются для ключей в таблицах?
Для ключей таблиц обычно применяются числовые и символьные типы. Наиболее распространены целые числа, так как они занимают мало места и позволяют быстро индексировать строки. Также часто используют строки фиксированной или переменной длины, особенно если ключ должен содержать код или уникальное обозначение объекта. Реже встречаются комбинированные ключи, которые объединяют несколько полей разных типов.
Можно ли использовать текстовые поля большого объёма в качестве ключей?
Использовать длинные текстовые поля для ключей не рекомендуется. Во-первых, они занимают много памяти, что замедляет операции поиска и сортировки. Во-вторых, вероятность ошибок при вводе и дублирования увеличивается. Если уникальность нужно обеспечить текстом, лучше создать отдельное короткое поле, например числовой идентификатор, и использовать его как основной ключ, а текст оставлять для описания.
В чём преимущества использования числовых идентификаторов вместо строк для первичных ключей?
Числовые идентификаторы позволяют ускорить поиск и соединение таблиц, так как операции с числами выполняются быстрее, чем с текстом. Они занимают меньше памяти и легче индексируются. Кроме того, генерация последовательных числовых значений упрощает добавление новых записей и снижает риск случайных дубликатов. Это особенно важно для больших баз данных, где производительность напрямую зависит от структуры ключей.
Что учитывать при выборе типа данных для составного ключа?
При выборе типов для составного ключа важно учитывать совместимость и размер каждого поля. Если одно поле большое и текстовое, а другое — маленькое числовое, это может повлиять на скорость поиска и хранения. Также нужно учитывать частоту изменений данных: поля, которые часто обновляются, делают поддержку ключа более сложной. Оптимально сочетать короткие и стабильные поля, чтобы ключ оставался уникальным и лёгким для индексирования.