Содержание статьи

Стек и очередь – базовые структуры данных, которые определяют порядок обработки элементов и напрямую влияют на поведение алгоритмов. Ошибка в выборе между ними приводит к логическим сбоям: неверному порядку вычислений, зависаниям процессов, некорректной обработке событий. Поэтому важно понимать не абстрактные определения, а конкретные правила, по которым данные попадают в структуру и извлекаются из неё.
Стек работает по принципу последним пришёл – первым вышел. Это свойство используется там, где требуется строгая вложенность действий: обработка вызовов функций, отмена операций, разбор выражений, работа с рекурсией. Очередь, напротив, обслуживает элементы в порядке поступления. Такой подход лежит в основе планирования задач, сетевых буферов, систем очередей сообщений и обработки запросов пользователей.
Несмотря на внешнюю простоту, различия между стеком и очередью проявляются на уровне операций добавления и удаления, реакции на переполнение, а также поведения при параллельной обработке данных. В практической разработке это отражается в выборе контейнеров стандартных библиотек, проектировании алгоритмов и настройке потоков выполнения.
В статье подробно разбираются прикладные различия между стеком и очередью: как формируется порядок доступа к данным, какие задачи подходят для каждой структуры, и по каким признакам можно определить правильный вариант для конкретного сценария.
Как определяется порядок извлечения элементов в стеке
Порядок извлечения элементов в стеке задаётся правилом LIFO: доступен только последний добавленный элемент. Это означает, что структура не позволяет произвольно читать или удалять данные из середины или начала – операция извлечения всегда работает с вершиной стека. Любая попытка получить более ранний элемент требует предварительного удаления всех вышележащих.
На практике это реализуется через две базовые операции: push добавляет элемент на вершину, pop снимает верхний элемент и возвращает его вызывающему коду. Вершина смещается после каждой операции, поэтому последовательность извлечения полностью повторяет обратный порядок добавления. Если элементы A, B и C добавлены именно в таком порядке, то извлечены будут C, затем B, затем A.
Такое поведение напрямую влияет на логику программ. В стеке вызовов функций последней всегда завершается та функция, которая была вызвана последней. При разборе арифметических выражений сначала обрабатываются вложенные скобки. В механизме отмены действий возвращается состояние, сохранённое позже остальных.
При проектировании алгоритма стек подходит в ситуациях, где требуется строгий контроль над вложенностью операций и гарантированный возврат к предыдущему состоянию. Если порядок извлечения должен совпадать с порядком поступления данных, стек использовать нельзя – его модель доступа это исключает.
Как формируется порядок обработки данных в очереди
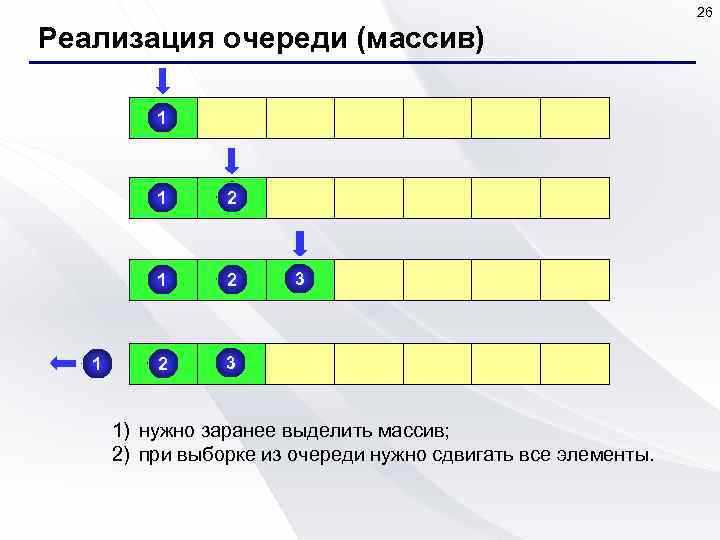
Очередь задаёт порядок обработки данных на основе правила FIFO, при котором каждый элемент обрабатывается строго после всех, кто был добавлен раньше. Последовательность фиксируется в момент добавления и не меняется до извлечения, что делает поведение структуры полностью детерминированным.
Добавление выполняется через операцию enqueue, которая помещает элемент в хвост очереди. Извлечение происходит с помощью dequeue и всегда затрагивает головной элемент. Если в очередь последовательно поступили задачи T1, T2 и T3, то они будут обработаны именно в этом порядке, независимо от их сложности или времени ожидания.
Такая модель применяется в системах, где важна корректная временная последовательность: обработка пользовательских запросов, выполнение заданий в очереди печати, передача пакетов по сетевому каналу. Очередь исключает ситуацию, при которой новые данные вытесняют ранее поступившие.
При выборе очереди следует учитывать её реализацию. Линейная очередь подходит для неограниченных потоков, кольцевая требует контроля размера, а структуры с приоритетами изменяют порядок извлечения. Для сценариев с жёстким соблюдением очередности следует использовать классическую очередь без дополнительных правил сортировки.
Операции добавления и удаления в стеке на практике
Работа со стеком сводится к двум операциям: добавлению элемента на вершину и удалению элемента с вершины. Эти действия не затрагивают остальные данные и не требуют их смещения, что делает поведение стека предсказуемым и удобным для сценариев с вложенной логикой.
Операция добавления помещает новый элемент поверх уже существующих. При этом вершина стека смещается и указывает на последний добавленный объект. Удаление всегда возвращает именно этот элемент и сразу же освобождает занимаемое им место. Попытка удалить элемент из пустого стека приводит к ошибке, которую необходимо обрабатывать на уровне кода.
На практике стек часто реализуется на основе массива или связного списка. В массиве требуется контроль выхода за пределы при добавлении, а в списке – корректное управление указателями. Выбор реализации влияет на ограничения по размеру и обработку переполнения.
| Операция | Описание | Практическое применение |
|---|---|---|
| push | Добавляет элемент на вершину стека | Сохранение состояния, запись вызова функции, помещение операнда |
| pop | Удаляет и возвращает верхний элемент | Возврат из функции, отмена действия, обработка выражений |
| peek | Читает верхний элемент без удаления | Проверка текущего состояния без изменения структуры |
При использовании стека важно заранее определить допустимую глубину и предусмотреть защиту от переполнения и попыток чтения из пустой структуры. Это снижает риск логических ошибок и сбоев во время выполнения программы.
Операции добавления и удаления в очереди на практике

Очередь реализует операции строго по принципу FIFO, где порядок обработки определяется временем добавления. Основные действия – добавление в конец и удаление с начала – обеспечивают последовательную обработку без вмешательства в середину структуры.
Ключевые операции и их использование на практике:
- enqueue – добавление элемента в конец очереди. Применяется для поступающих задач, сетевых пакетов или сообщений, чтобы они обрабатывались в порядке поступления.
- dequeue – удаление элемента из начала очереди с возвратом значения. Используется для последовательного выполнения задач, снятия запросов с обработки и передачи данных потребителям.
- peek/front – чтение первого элемента без удаления. Применяется для проверки следующей задачи в обработке без изменения состояния очереди.
При проектировании очереди учитываются следующие практические аспекты:
- Контроль размера: линейная очередь может быть ограничена памятью, кольцевая требует управления указателями.
- Обработка переполнения: при полном заполнении нужно выбирать стратегию – отклонение новых элементов или расширение структуры.
- Проверка пустой очереди: перед извлечением необходимо убедиться, что элементы присутствуют, иначе возможна ошибка выполнения.
Придерживаясь этих правил, разработчики получают предсказуемое поведение очереди, которое критично для планировщиков задач, обработки сетевых пакетов и систем очередей сообщений.
Типичные задачи программирования для использования стека
Стек применяется в задачах, где требуется контроль над последовательностью вложенных операций и возможность возврата к предыдущему состоянию. Основные сценарии включают:
- Обработка вызовов функций: стек вызовов сохраняет адреса возврата и локальные переменные, обеспечивая корректное завершение функций в обратном порядке вызова.
- Разбор выражений: при вычислении арифметических или логических выражений стек используется для хранения операторов и операндов, особенно в алгоритмах перевода инфиксной записи в постфиксную и её вычисления.
- Отмена действий в интерфейсах: стек сохраняет последовательность изменений состояния, позволяя реализовать функционал undo/redo.
- Обход структур данных: при обходе деревьев или графов стек хранит узлы для возврата к предыдущим уровням без рекурсивного вызова функций.
- Проверка корректности скобок: стек хранит открывающиеся скобки, что позволяет при встрече закрывающей скобки проверять правильность вложенности и последовательности.
При проектировании алгоритмов важно учитывать размер стека и возможное переполнение. Для больших объёмов данных рекомендуется реализовать динамическое расширение или контроль максимальной глубины, чтобы предотвратить ошибки выполнения.
Типичные задачи программирования для использования очереди

Очередь применяется в ситуациях, где требуется обработка элементов в порядке поступления. Основные задачи включают:
- Планирование задач: очередь используется в системах управления процессами и потоками для последовательного выполнения заданий без нарушения порядка поступления.
- Обработка сетевых пакетов: пакеты добавляются в очередь по мере поступления и извлекаются в том же порядке, что обеспечивает корректную передачу данных и минимизацию потерь.
- Системы очередей сообщений: сообщения между компонентами приложения обрабатываются строго по порядку, что предотвращает несогласованность состояния.
- Моделирование событий: события в симуляциях добавляются в очередь и обрабатываются по времени поступления, что позволяет воспроизводить последовательность действий в реальном времени.
При проектировании важно учитывать ограничения по размеру очереди и обрабатывать ситуации переполнения. Для интенсивных потоков данных рекомендуется использовать динамические очереди или кольцевые буферы с контролем указателей начала и конца, чтобы сохранять корректный порядок обработки.
Поведение структур данных при переполнении и опустошении

Переполнение и опустошение стека и очереди требуют внимательного контроля, так как нарушения этих условий приводят к ошибкам выполнения. В стеке переполнение возникает, когда добавляется элемент, превышающий максимальную глубину структуры. В таких случаях операции push должны либо генерировать исключение, либо инициировать расширение памяти при динамическом выделении.
Опустошение стека проявляется при попытке выполнения pop на пустой структуре. Практическое решение – проверка состояния с помощью функции isEmpty перед удалением элемента, чтобы избежать обращения к несуществующим данным.
Для очереди переполнение наступает при добавлении элемента в полностью заполненную структуру. В линейной реализации это ограничено размером массива, в кольцевой – необходимо следить за пересечением указателей начала и конца. При переполнении можно применять стратегию отклонения новых элементов или расширение очереди.
Опустошение очереди фиксируется при попытке извлечения через dequeue из пустой структуры. Рекомендуется проверять количество элементов с помощью isEmpty, чтобы избежать ошибок и некорректного поведения алгоритмов.
Для обеих структур данных критически важно реализовать контроль границ и предсказуемое поведение при переполнении и опустошении. Это обеспечивает стабильность работы алгоритмов и корректное управление памятью.
Выбор между стеком и очередью в прикладных сценариях

Выбор структуры данных определяется требуемым порядком обработки элементов и особенностями задач. Стек применяется там, где критично соблюдать обратную последовательность действий. Например, для хранения вызовов функций, реализации undo/redo в интерфейсах или обработки вложенных выражений предпочтительно использовать стек.
Очередь выбирается, когда важен порядок поступления данных. Она необходима для планирования задач, организации сетевых потоков, обработки сообщений между компонентами системы и моделирования событий во времени. FIFO-модель обеспечивает равное и последовательное обслуживание всех элементов.
При проектировании алгоритмов следует учитывать дополнительные условия:
- Объём данных: для больших потоков информации динамические структуры предпочтительнее фиксированных массивов.
- Возможность переполнения: стек требует контроля глубины вызовов, очередь – контроля длины буфера.
- Необходимость проверки состояния: перед извлечением элемента рекомендуется использовать функции isEmpty или аналогичные методы.
Выбор между стеком и очередью должен основываться на принципах обработки данных и особенностях конкретного сценария. Неправильный выбор приводит к логическим ошибкам и снижает предсказуемость работы программы.
Вопрос-ответ:
В чём основное отличие стека от очереди?
Стек работает по принципу LIFO — последний добавленный элемент извлекается первым. Очередь использует FIFO — первый добавленный элемент извлекается первым. Это определяет порядок обработки данных и подходит для разных задач: стек используется для вложенных операций, а очередь — для последовательного обслуживания поступающих элементов.
Как правильно реализовать операции добавления и удаления в стеке на практике?
В стеке для добавления используют операцию push, которая помещает элемент на вершину структуры, а для удаления — pop, которая снимает верхний элемент и возвращает его. Перед pop рекомендуется проверять, не пуст ли стек, чтобы избежать ошибок. Для больших объёмов данных допустимо использовать динамическое расширение массива или связный список.
В каких случаях очередь предпочтительнее стека?
Очередь применяется, когда важна обработка элементов в порядке поступления. Это встречается при планировании задач в системе, обработке сетевых пакетов или сообщений между компонентами приложения. FIFO-модель гарантирует, что новые элементы не будут обслужены раньше тех, что поступили раньше, что сохраняет корректную последовательность действий.
Что происходит при переполнении и опустошении стека или очереди?
Переполнение стека происходит, когда добавляется элемент сверх допустимой глубины; операции push в этом случае должны генерировать ошибку или расширять память при динамической структуре. Опустошение проявляется при pop на пустом стеке. В очереди переполнение наступает при добавлении элемента в заполненную структуру, а опустошение — при попытке dequeue без элементов. Рекомендуется всегда проверять состояние через isEmpty или контролировать размер, чтобы предотвратить ошибки.