Содержание статьи

Подсчет уникальных значений в таблице SQL часто необходим для анализа данных, выявления дубликатов и подготовки отчетов. Самый прямой метод – использование функции COUNT(DISTINCT column_name), которая возвращает количество различных значений в указанной колонке. Например, запрос SELECT COUNT(DISTINCT user_id) FROM orders; покажет количество уникальных пользователей, сделавших заказы.
Если требуется подсчет уникальных комбинаций нескольких колонок, стандартный COUNT DISTINCT можно использовать с перечислением нескольких полей через запятую: SELECT COUNT(DISTINCT user_id, product_id) FROM orders;. Такой подход помогает оценить, сколько различных пар «пользователь–продукт» встречается в таблице.
Для более сложного анализа удобны GROUP BY и HAVING. Они позволяют подсчитывать уникальные значения в разбивке по категориям или фильтровать группы по количеству уникальных элементов. Например, SELECT category_id, COUNT(DISTINCT product_id) FROM products GROUP BY category_id; покажет количество уникальных продуктов в каждой категории.
Подзапросы и оконные функции открывают возможности для подсчета уникальных значений в рамках динамических выборок или скользящих окон. Использование ROW_NUMBER() с PARTITION BY позволяет выявить первые уникальные записи по заданным критериям, что полезно при формировании отчетов без дубликатов.
Выбор метода подсчета зависит от объема данных и целей анализа. Для больших таблиц прямой COUNT(DISTINCT) может быть медленным, тогда стоит рассматривать агрегированные подзапросы или временные таблицы для снижения нагрузки на сервер.
Использование COUNT DISTINCT для одной колонки
Функция COUNT(DISTINCT column_name) позволяет подсчитать количество уникальных значений в одной колонке без необходимости дополнительной фильтрации. Например, SELECT COUNT(DISTINCT email) FROM users; покажет число различных адресов электронной почты в таблице пользователей.
Если колонка содержит NULL значения, COUNT(DISTINCT) их игнорирует. Для учета всех записей, включая пустые значения, следует использовать комбинацию COUNT и CASE: SELECT COUNT(CASE WHEN email IS NOT NULL THEN 1 END) FROM users;.
Для ускорения подсчета уникальных значений в больших таблицах рекомендуется создавать индекс на колонку. Например, CREATE INDEX idx_email ON users(email); значительно сокращает время выполнения COUNT(DISTINCT email) при миллионах записей.
При необходимости получить список уникальных значений вместе с их количеством можно использовать GROUP BY с COUNT: SELECT email, COUNT(*) FROM users GROUP BY email;. Этот подход помогает сразу видеть распределение повторяющихся значений.
Подсчет уникальных комбинаций нескольких колонок
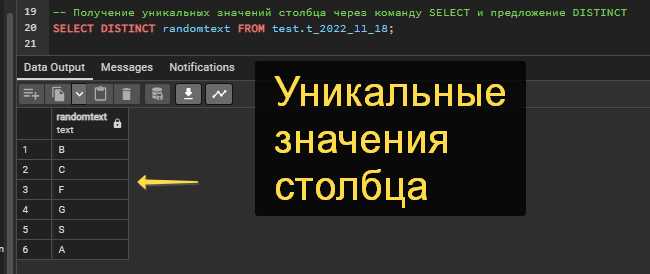
Для определения количества уникальных сочетаний нескольких колонок используют два подхода: прямой COUNT(DISTINCT column1, column2) в СУБД, которые поддерживают такую запись, и GROUP BY с подзапросом для остальных систем.
Примеры запросов:
- В PostgreSQL или MySQL 8+: SELECT COUNT(DISTINCT user_id, product_id) FROM orders;
- В SQL Server или MySQL до версии 8: SELECT COUNT(*) FROM (SELECT user_id, product_id FROM orders GROUP BY user_id, product_id) AS sub;
Фильтрация уникальных комбинаций выполняется через WHERE или HAVING:
- SELECT COUNT(*) FROM (SELECT user_id, product_id FROM orders WHERE status=’completed’ GROUP BY user_id, product_id HAVING COUNT(*) > 0) AS sub;
Рекомендации по оптимизации:
- Создавайте составной индекс на колонки: CREATE INDEX idx_user_product ON orders(user_id, product_id);
- Используйте подзапрос с GROUP BY для больших таблиц, чтобы уменьшить нагрузку на сервер.
- Избегайте сортировки перед подсчетом уникальных комбинаций, если СУБД автоматически группирует данные при GROUP BY.
Применение GROUP BY для группировки и подсчета уникальных записей
Оператор GROUP BY используется для объединения строк с одинаковыми значениями в одной или нескольких колонках и последующего подсчета уникальных записей с помощью агрегатных функций.
Примеры практического использования:
- Подсчет уникальных пользователей по статусу заказов: SELECT status, COUNT(DISTINCT user_id) FROM orders GROUP BY status;
- Количество заказов каждого продукта: SELECT product_id, COUNT(*) FROM orders GROUP BY product_id;
Фильтрация сгруппированных данных выполняется через HAVING, так как WHERE работает до группировки:
- Показать продукты с более чем 10 заказами: SELECT product_id, COUNT(*) FROM orders GROUP BY product_id HAVING COUNT(*) > 10;
Рекомендации по использованию:
- Создавайте индексы на колонках, участвующих в GROUP BY, чтобы ускорить агрегацию.
- Используйте COUNT(DISTINCT column) внутри GROUP BY для подсчета уникальных значений по категориям.
- Для больших таблиц предварительно фильтруйте данные через WHERE, чтобы уменьшить объем группировки.
Фильтрация уникальных значений с WHERE и HAVING

Для ограничения выборки перед подсчетом уникальных значений используют WHERE. Она фильтрует строки до применения агрегатных функций и группировки. Пример:
- SELECT COUNT(DISTINCT user_id) FROM orders WHERE status=’completed’; – подсчет уникальных пользователей с завершенными заказами.
Фильтрация после группировки выполняется через HAVING. Она применяет условия к агрегатам, например:
- SELECT product_id, COUNT(DISTINCT user_id) FROM orders GROUP BY product_id HAVING COUNT(DISTINCT user_id) > 5; – продукты, заказанные более чем 5 уникальными пользователями.
Рекомендации по применению:
- Используйте WHERE для сокращения объема данных перед подсчетом уникальных значений.
- Применяйте HAVING для фильтрации по результатам агрегации, например по количеству уникальных элементов.
- Комбинируйте WHERE и HAVING для сложных выборок, чтобы минимизировать нагрузку на сервер и ускорить выполнение запросов.
Подсчет уникальных значений в подзапросах
Подзапросы позволяют сначала сформировать выборку, а затем подсчитать уникальные значения на ее основе. Это полезно, когда требуется фильтровать или агрегировать данные до подсчета.
Пример подсчета уникальных пользователей, совершивших заказы только за последний месяц:
SELECT COUNT(DISTINCT user_id) FROM (SELECT user_id FROM orders WHERE order_date >= ‘2025-12-01’) AS recent_orders;
Можно комбинировать подзапросы с группировкой для анализа уникальных комбинаций:
SELECT COUNT(*) FROM (SELECT user_id, product_id FROM orders WHERE status=’completed’ GROUP BY user_id, product_id) AS completed_pairs;
Рекомендации по использованию подзапросов для уникальных значений:
- Используйте подзапросы, если нужно предварительно отфильтровать или агрегировать данные перед подсчетом уникальных значений.
- Применяйте COUNT(DISTINCT …) внутри подзапроса или снаружи в зависимости от структуры данных и требований отчета.
- Для больших таблиц создавайте индексы на колонках, участвующих в подзапросах, чтобы уменьшить время выполнения запроса.
Использование оконных функций для анализа уникальных данных
Оконные функции позволяют выполнять агрегацию без группировки всей таблицы, сохраняя исходные строки. Для анализа уникальных данных часто используют ROW_NUMBER(), RANK() и DENSE_RANK().
Пример подсчета первой покупки каждого пользователя:
SELECT user_id, product_id, order_date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_date) AS row_num FROM orders;
Фильтрация первой уникальной покупки:
SELECT user_id, product_id, order_date FROM (
SELECT user_id, product_id, order_date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_date) AS row_num
FROM orders
) AS ranked_orders WHERE row_num = 1;
Для анализа повторяющихся значений и частоты используют DENSE_RANK():
SELECT user_id, product_id, DENSE_RANK() OVER (PARTITION BY product_id ORDER BY order_date) AS purchase_rank FROM orders;
Пример визуального отображения уникальных и ранжированных данных:
| user_id | product_id | order_date | row_num |
|---|---|---|---|
| 101 | 2001 | 2025-12-01 | 1 |
| 101 | 2003 | 2025-12-05 | 2 |
| 102 | 2001 | 2025-12-02 | 1 |
Рекомендации:
- Используйте ROW_NUMBER() для выявления первой уникальной записи в каждой группе.
- DENSE_RANK() помогает определить уникальные позиции и частоту появления значений.
- Комбинируйте оконные функции с фильтрацией, чтобы анализировать уникальные данные без потери строк исходной таблицы.
Сравнение производительности разных методов подсчета уникальных значений

Разные методы подсчета уникальных значений имеют существенные различия по скорости выполнения, особенно на больших таблицах.
COUNT(DISTINCT column):
- Прямой подсчет уникальных значений в одной колонке.
- Высокая нагрузка при миллионах строк без индекса.
- Оптимизация: создание индекса на колонку сокращает время выполнения.
GROUP BY:
- Подходит для подсчета уникальных комбинаций нескольких колонок.
- Эффективнее при наличии составных индексов на используемые колонки.
- Объем данных для группировки напрямую влияет на производительность.
Подзапросы с агрегацией:
- Используются, если СУБД не поддерживает COUNT(DISTINCT несколько колонок).
- Производительность зависит от фильтрации внутри подзапроса.
Оконные функции:
- Позволяют анализировать уникальные значения без удаления исходных строк.
- При больших таблицах с миллионами записей могут быть медленнее обычного COUNT(DISTINCT), особенно без индексов.
Рекомендации по выбору метода:
- Для одной колонки используйте COUNT(DISTINCT) с индексом.
- Для нескольких колонок предпочтителен GROUP BY с составным индексом.
- Подзапросы эффективны при сложных фильтрах и выборках.
- Оконные функции применяйте для анализа уникальных данных без потери строк, когда важен контекст каждой записи.
Вопрос-ответ:
Как посчитать количество уникальных пользователей в таблице заказов?
Для подсчета уникальных пользователей используется функция COUNT(DISTINCT user_id). Пример запроса: SELECT COUNT(DISTINCT user_id) FROM orders;. Этот запрос вернет число различных идентификаторов пользователей, которые сделали хотя бы один заказ. Если в колонке user_id есть NULL значения, они будут игнорироваться. Для ускорения запроса на больших таблицах можно создать индекс на колонку user_id.
Можно ли подсчитать уникальные комбинации двух колонок в MySQL до версии 8?
В MySQL до версии 8 нельзя использовать COUNT(DISTINCT column1, column2) напрямую. Вместо этого нужно создать подзапрос с GROUP BY, который сформирует уникальные пары, а затем посчитать их количество. Например: SELECT COUNT(*) FROM (SELECT user_id, product_id FROM orders GROUP BY user_id, product_id) AS sub;. Такой подход позволяет получить число уникальных сочетаний пользователя и продукта.
В чем разница между фильтрацией через WHERE и HAVING при подсчете уникальных значений?
WHERE фильтрует строки до агрегирования, поэтому используется для ограничения исходного набора данных. Например: SELECT COUNT(DISTINCT user_id) FROM orders WHERE status=’completed’;. HAVING применяется после группировки и позволяет фильтровать по результатам агрегатных функций: SELECT product_id, COUNT(DISTINCT user_id) FROM orders GROUP BY product_id HAVING COUNT(DISTINCT user_id) > 5;. Таким образом, WHERE и HAVING дополняют друг друга, решая разные задачи.
Когда стоит применять оконные функции для анализа уникальных данных?
Оконные функции, такие как ROW_NUMBER() и DENSE_RANK(), полезны, когда нужно сохранить все исходные строки таблицы и при этом выделить уникальные записи или определить их порядок. Например, чтобы получить первую покупку каждого пользователя: SELECT user_id, product_id, order_date FROM (SELECT user_id, product_id, order_date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_date) AS row_num FROM orders) AS ranked_orders WHERE row_num = 1;. Этот метод удобен для анализа повторяющихся данных без удаления строк из исходной таблицы.