Содержание статьи

Сетевые очереди образуются, когда поток данных превышает доступную пропускную способность канала. При этом пакеты временно помещаются в буфер, что влияет на задержку и стабильность соединения. Мониторинг очередей позволяет выявлять перегруженные участки сети и определять причины снижения производительности.
На практике отслеживаются показатели длины очереди, времени ожидания пакетов и частоты их потерь. Эти данные показывают, где именно возникает узкое место – на интерфейсе маршрутизатора, в коммутаторе или на уровне приложений. Анализ таких метрик помогает своевременно корректировать конфигурацию сети и распределение трафика.
Цель мониторинга не только в фиксации перегрузок, но и в предотвращении их появления. Своевременная оценка состояния очередей обеспечивает стабильное качество связи, равномерное распределение нагрузки и предсказуемое время отклика сервисов.
Назначение мониторинга сетевых очередей в корпоративных системах

В корпоративных сетях контроль состояния очередей необходим для поддержания стабильной передачи данных между серверами, рабочими станциями и удалёнными филиалами. Нагрузка на каналы связи распределяется неравномерно, и без постоянного наблюдения возможно накопление пакетов, что приводит к задержкам и потере производительности бизнес-приложений.
Мониторинг очередей используется для решения следующих практических задач:
- Определение участков сети, где происходит накопление пакетов и рост времени ожидания.
- Своевременное выявление перегрузок маршрутизаторов и коммутаторов.
- Оценка влияния приоритетных политик (QoS) на распределение пропускной способности.
- Проверка соответствия текущей конфигурации сети требованиям SLA и внутренним стандартам.
- Подготовка аналитических данных для планирования модернизации сетевой инфраструктуры.
Для повышения точности анализа применяются системы, собирающие данные с SNMP-агентов, NetFlow и sFlow-экспортеров. Они формируют детализированные отчёты по каждому интерфейсу и типу трафика, что позволяет администратору оценивать реальную картину загрузки в динамике и корректировать правила маршрутизации или приоритезации пакетов.
Какие параметры отслеживаются при контроле сетевых очередей
Контроль состояния очередей основан на сборе точных показателей, которые характеризуют работу сетевых устройств и уровень загрузки каналов. От выбранных метрик зависит достоверность анализа и своевременность реакции на перегрузки.
Основные параметры, подлежащие мониторингу:
- Длина очереди – количество пакетов, ожидающих обработки интерфейсом. Позволяет определить степень загруженности устройства и необходимость балансировки трафика.
- Среднее время ожидания пакета – интервал между поступлением и передачей данных. Рост показателя указывает на необходимость оптимизации пропускной способности.
- Частота сброса пакетов – процент данных, удалённых из очереди из-за переполнения буфера. Служит индикатором перегрузки и ошибок конфигурации QoS.
- Использование буфера – объём памяти, задействованный для хранения временных данных. Контролируется для предотвращения внезапных обрывов соединений.
- Пропускная способность интерфейса – фактическая скорость передачи данных относительно номинальной. Помогает выявлять участки с ограниченной производительностью.
Регулярный сбор этих параметров с маршрутизаторов, коммутаторов и сетевых шлюзов позволяет формировать динамическую картину состояния сети. На основе данных создаются автоматические правила перераспределения трафика и уведомления при достижении критических значений.
Как задержки в очереди влияют на пропускную способность сети
Задержка в очереди возникает при превышении объёма входящих пакетов над скоростью обработки интерфейса. Даже кратковременное накопление данных снижает общую пропускную способность, так как ресурсы буфера расходуются на хранение, а не на передачу пакетов. Увеличение времени ожидания ведёт к росту латентности и нестабильности TCP-сессий.
Связь между задержками и пропускной способностью можно описать следующими зависимостями:
| Показатель | Влияние на сеть | Рекомендации администратора |
|---|---|---|
| Среднее время ожидания более 50 мс | Заметное снижение скорости отклика приложений | Проверить загрузку интерфейсов и параметры QoS |
| Переполнение буфера более 10% | Потеря пакетов и повторные передачи данных | Снизить приоритет низкочастотного трафика или увеличить объём буфера |
| Рост латентности в часы пик | Падение пропускной способности при стабильной загрузке | Настроить адаптивное распределение трафика между каналами |
| Неравномерная задержка (jitter) | Нарушения в работе VoIP и потоковых сервисов | Применить политику приоритезации реального времени |
Анализ задержек позволяет точно определить, на каком этапе сети возникают узкие места. Контроль этих параметров в режиме реального времени помогает поддерживать устойчивое соединение и гарантировать стабильную передачу данных при изменяющихся нагрузках.
Инструменты для анализа загрузки сетевых очередей
Для точного анализа загрузки сетевых очередей применяются специализированные решения, собирающие статистику о передаче пакетов и загрузке интерфейсов в реальном времени. Они позволяют контролировать динамику трафика, фиксировать переполнения буферов и отслеживать распределение нагрузки между узлами сети.
На практике используются следующие категории инструментов:
- SNMP-мониторы – Zabbix, PRTG Network Monitor, The Dude. С их помощью можно получать метрики длины очередей и процента использования буфера с маршрутизаторов и коммутаторов.
- Системы потокового анализа – NetFlow, sFlow, IPFIX. Они предоставляют детальные данные о типах трафика, источниках перегрузок и объёмах передаваемых пакетов.
- Протоколы активного тестирования – iPerf, OWAMP, PingPlotter. Позволяют измерять задержки, потери пакетов и джиттер, влияющие на состояние очередей.
- Решения для централизованной визуализации – Grafana, Prometheus, Elastic Stack. Используются для построения графиков загрузки и автоматической генерации уведомлений при превышении пороговых значений.
Для повышения точности диагностики рекомендуется комбинировать пассивный и активный сбор данных. Такой подход обеспечивает полноту анализа: SNMP и NetFlow показывают фактическую загрузку интерфейсов, а тестовые пакеты выявляют влияние задержек на качество соединений.
Настройка пороговых значений и уведомлений при росте очереди

Настройка пороговых значений необходима для своевременного обнаружения перегрузок и предотвращения потерь пакетов. Чётко определённые границы позволяют системе мониторинга реагировать на отклонения до того, как они начнут влиять на производительность сети.
Оптимальные пороги зависят от типа оборудования и характера трафика. Для маршрутизаторов среднего уровня длина очереди более 70–80% от ёмкости буфера уже считается критической. При этом следует учитывать время пиковых нагрузок и допускать временные колебания без ложных срабатываний.
Рекомендуемая схема настройки:
- Предупреждающий уровень (warning) – 50–60% использования буфера, уведомление в систему мониторинга без автоматических действий.
- Критический уровень (critical) – превышение 80–90%, генерация уведомления и запуск корректирующего сценария (снижение приоритета фонового трафика или перераспределение потоков).
- Аварийный уровень (alert) – 95% и выше, запись события в журнал, уведомление администратора по e-mail или через мессенджер.
Для настройки уведомлений используются встроенные механизмы Zabbix, PRTG, Nagios или Grafana Alerting. Они позволяют задавать условия срабатывания, частоту повторных оповещений и формат сообщений. Практика показывает, что оптимально использовать разные каналы оповещения для различных уровней критичности, чтобы ускорить реакцию и исключить пропуск инцидентов.
Регулярная проверка корректности порогов обязательна при изменении структуры сети или объёмов трафика. Это гарантирует, что система сигнализирует только о реальных проблемах, а не о штатных колебаниях нагрузки.
Методы обнаружения узких мест с помощью мониторинга очередей
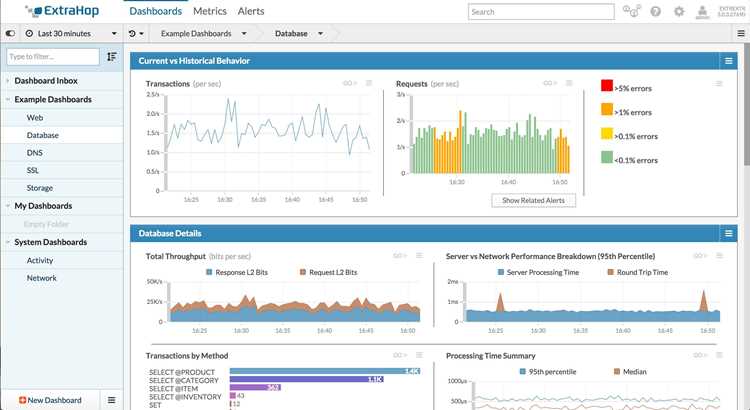
Обнаружение узких мест в сети требует точного анализа загрузки интерфейсов и поведения пакетов в очередях. Основная цель – выявить участки, где задержки и потери пакетов существенно ограничивают пропускную способность и нарушают работу бизнес-приложений.
Основные методы выявления узких мест:
- Анализ длины очереди и использования буфера
- Регулярный сбор данных о количестве пакетов в очереди.
- Сравнение с номинальной ёмкостью буфера для определения перегрузки.
- Мониторинг времени ожидания пакетов
- Замер средних и пиковых задержек для каждого интерфейса.
- Идентификация маршрутов с высокой латентностью, где требуется перераспределение трафика.
- Отслеживание потерь пакетов
- Фиксация повторных передач и сброшенных пакетов.
- Выявление сегментов сети с недостаточной пропускной способностью.
- Анализ типов и приоритетов трафика
- Определение, какой вид трафика создаёт перегрузку (VoIP, видео, фоновые обновления).
- Корректировка правил QoS для оптимального распределения ресурсов.
- Использование визуализации и графиков
- Построение графиков загрузки интерфейсов и длины очередей во времени.
- Выявление периодических пиков и повторяющихся узких мест.
Комплексное применение этих методов позволяет точно локализовать проблемные участки, определить источник перегрузок и принять меры по балансировке нагрузки и перераспределению трафика.
Использование данных мониторинга для оптимизации маршрутизации
Данные мониторинга сетевых очередей дают возможность корректировать маршруты передачи трафика на основе реальной загрузки интерфейсов. Информация о длине очередей, задержках и потерях пакетов позволяет выявлять перегруженные сегменты и перераспределять потоки для снижения латентности.
Практические подходы к оптимизации маршрутизации:
- Перенаправление трафика с перегруженных интерфейсов на менее загруженные маршруты с учётом приоритетов приложений.
- Динамическое изменение весов маршрутов в протоколах OSPF и BGP на основе метрик времени ожидания пакетов и использования буферов.
- Применение политик QoS для критических сервисов, чтобы обеспечить минимальные задержки и исключить потери пакетов на узких местах.
- Анализ исторических данных для выявления повторяющихся пиковых нагрузок и планирование резервных маршрутов заранее.
Регулярный сбор и обработка метрик позволяет формировать автоматические сценарии перераспределения трафика, снижать риск перегрузок и поддерживать стабильную пропускную способность сети без ручного вмешательства администраторов.
Автоматизация мониторинга очередей в распределённых сетях

В распределённых сетях ручной контроль состояния очередей становится сложным из-за большого числа узлов и разнообразия трафика. Автоматизация позволяет централизованно собирать метрики, анализировать их и реагировать на перегрузки без задержек.
Основные подходы к автоматизации:
- Развертывание агентов на маршрутизаторах и коммутаторах для непрерывного сбора данных о длине очередей, задержках и потерях пакетов.
- Использование систем центрального мониторинга (Zabbix, Prometheus, Grafana) для агрегации и визуализации показателей всех узлов сети.
- Настройка автоматических уведомлений и сценариев перераспределения трафика при достижении критических порогов.
- Применение машинного обучения для анализа исторических данных и прогнозирования перегрузок в пиковые часы.
- Интеграция с системами управления сетью для автоматической корректировки маршрутов и QoS-политик без вмешательства администратора.
Автоматизация снижает риск человеческой ошибки, ускоряет реакцию на перегрузки и обеспечивает равномерное распределение нагрузки в масштабируемых корпоративных сетях.
Вопрос-ответ:
Зачем нужен мониторинг сетевых очередей в корпоративной сети?
Мониторинг сетевых очередей позволяет отслеживать перегрузку каналов и буферов на маршрутизаторах и коммутаторах. Это помогает выявлять узкие места, где задержки пакетов и потери данных могут снижать производительность приложений. Своевременный контроль очередей позволяет перенаправлять трафик, корректировать приоритеты и предотвращать снижение качества работы критических сервисов.
Какие метрики следует контролировать для анализа очередей?
Основными показателями являются длина очереди, среднее время ожидания пакета, частота потерь и использование буфера. Эти метрики дают понимание загрузки интерфейсов и помогают определить, где возникает задержка передачи данных. Например, рост времени ожидания выше 50 мс может указывать на перегруженный канал, требующий перераспределения трафика или изменения правил приоритезации.
Какие инструменты подходят для анализа состояния сетевых очередей?
Для мониторинга используют SNMP-системы (Zabbix, PRTG), потоковый анализ (NetFlow, sFlow) и тестирование задержек (iPerf, OWAMP). Эти инструменты собирают детализированные данные о загрузке интерфейсов, распределении пакетов и типах трафика. Централизованная визуализация через Grafana или Prometheus позволяет наглядно оценивать состояние очередей и автоматически уведомлять о превышении порогов.
Как данные мониторинга помогают оптимизировать маршрутизацию?
На основе показателей длины очередей, задержек и потерь пакетов можно выявлять перегруженные маршруты и перераспределять трафик на менее загруженные каналы. Использование таких данных позволяет настраивать динамические маршруты в OSPF или BGP, корректировать политики QoS для критических сервисов и планировать резервные маршруты для предотвращения падения пропускной способности в пиковые часы.