Содержание статьи

Медленные запросы в MySQL могут стать узким местом при работе с таблицами свыше миллиона записей. На выборку влияет структура таблиц, наличие индексов и количество соединений. Добавление индексов на часто используемые столбцы может снизить время выполнения запроса в 5–10 раз, особенно при использовании фильтров в WHERE и JOIN.
Использование EXPLAIN помогает определить, какие части запроса создают наибольшую нагрузку. Анализ плана выполнения показывает, какие индексы MySQL использует, а какие игнорирует, что позволяет целенаправленно улучшать производительность без увеличения нагрузки на сервер.
Для больших таблиц применение LIMIT и пагинации сокращает объем данных, передаваемых клиенту, и уменьшает потребление памяти. Разделение таблиц на партиции по дате или другим критериям позволяет ускорить выборку, ограничивая поиск только актуальными сегментами.
Кэширование результатов запросов и использование временных таблиц при сложных вычислениях сокращает повторное выполнение тяжелых операций. Сочетание индексов, оптимизированных условий выборки и кэширования дает заметное снижение времени отклика даже при интенсивной нагрузке.
Использование индексов для ускорения запросов SELECT

Индексы уменьшают количество строк, которые MySQL просматривает при выполнении SELECT. Для столбцов с высокой селективностью, таких как идентификаторы, даты или уникальные значения, создание BTREE индексов ускоряет поиск до 10–15 раз. Для текстовых полей с частичным совпадением применяют FULLTEXT индексы.
Составные индексы полезны, если запрос фильтрует несколько столбцов одновременно. Например, индекс на (category_id, created_at) позволяет ускорить выборку по категории и дате, минимизируя полное сканирование таблицы. Порядок столбцов в индексе критичен: MySQL использует только левую часть индекса для поиска.
Необходимо избегать создания избыточных индексов, так как каждый индекс увеличивает нагрузку при INSERT, UPDATE и DELETE. Использование EXPLAIN позволяет проверять, какие индексы задействованы и корректировать структуру таблицы для максимальной производительности SELECT.
Индексы для диапазонных запросов (BETWEEN, >=, <=) также сокращают количество просматриваемых строк, но при частых обновлениях данных их стоит балансировать с нагрузкой на запись. Индексирование часто используемых JOIN-ключей ускоряет объединение таблиц без полного сканирования.
Оптимизация WHERE и JOIN условий для снижения нагрузки

Фильтры в WHERE и условия объединений в JOIN напрямую влияют на скорость выполнения SELECT. Правильная формулировка запросов позволяет уменьшить количество обрабатываемых строк и снизить нагрузку на сервер.
Рекомендации по оптимизации WHERE:
- Использовать точные совпадения и диапазоны вместо функций, например, `created_at >= ‘2025-01-01’` вместо `DATE(created_at) >= ‘2025-01-01’`.
- Применять индексы на столбцы, участвующие в фильтрах, чтобы MySQL мог быстро находить подходящие записи.
- Избегать использования операторов `LIKE ‘%значение%’`, так как они блокируют использование индекса. Лучше применять полнотекстовый поиск.
- Стараться использовать булевы значения и ENUM для часто фильтруемых колонок.
Рекомендации по оптимизации JOIN:
- Всегда указывать условия соединения по индексируемым столбцам.
- Использовать INNER JOIN вместо LEFT JOIN, если не требуется включать строки без совпадений.
- Сортировать таблицы по размеру: сначала соединять меньшие таблицы, чтобы уменьшить промежуточные результаты.
- Для больших объединений проверять EXPLAIN, чтобы убедиться, что MySQL использует индексы и не делает полное сканирование.
Оптимизация условий WHERE и JOIN в совокупности с правильными индексами снижает время выборки на десятки процентов и уменьшает потребление памяти при работе с крупными таблицами.
Применение LIMIT и пагинации для больших таблиц

При работе с таблицами свыше миллиона строк передача всех данных за один запрос сильно нагружает сервер и сеть. Ограничение выборки с помощью LIMIT уменьшает объем возвращаемых строк и ускоряет отклик.
Примеры оптимальной пагинации:
- Использовать `LIMIT offset, count` для небольших смещений. Например, `LIMIT 0, 1000` возвращает первые 1000 строк.
- Для больших смещений применять «keyset pagination», используя индексируемый столбец вместо OFFSET: `WHERE id > last_id LIMIT 1000` снижает нагрузку на MySQL и ускоряет выборку.
- Сортировать данные по индексируемым столбцам, чтобы MySQL мог быстро находить диапазон строк.
- Для пользовательских интерфейсов загружать данные порциями, например, по 500–1000 строк, чтобы сократить время отклика и уменьшить потребление памяти.
Комбинация LIMIT, правильной сортировки и keyset-пагинации позволяет эффективно обрабатывать большие таблицы без полного сканирования и значительно сокращает нагрузку на базу данных.
Анализ и оптимизация медленных запросов через EXPLAIN
Команда EXPLAIN в MySQL отображает план выполнения запроса, включая порядок чтения таблиц, тип соединений, использование индексов и предполагаемое количество обрабатываемых строк.
- id – идентификатор запроса или подзапроса.
- select_type – тип SELECT (SIMPLE, PRIMARY, SUBQUERY и др.).
- table – таблица, к которой применяется операция.
- type – тип соединения: ALL (полный перебор), ref, eq_ref. Наиболее эффективны ref и eq_ref.
- possible_keys – доступные индексы.
- key – индекс, который реально используется.
- rows – количество строк, предполагаемых для чтения.
- Extra – дополнительные операции, например Using temporary или Using filesort, которые замедляют запрос.
Для ускорения запросов через EXPLAIN применяются следующие подходы:
1. Использование индексов. Проверка, какие индексы доступны и применяются. Если key пустой при наличии possible_keys, стоит добавить индекс по колонкам фильтрации или соединения.
2. Минимизация полного перебора (type = ALL). Полный перебор таблицы сильно увеличивает время выборки. Пересмотрите условия WHERE и JOIN, добавьте составные индексы при необходимости.
3. Сокращение количества строк (rows). Ограничение выборки через LIMIT или более точные фильтры уменьшает нагрузку и ускоряет выполнение.
4. Избегание операций Using temporary и Using filesort. Эти операции создают временные таблицы и сортировки на диске. Оптимизация индексов и пересмотр ORDER BY позволяют их исключить.
5. Анализ подзапросов. Подзапросы с большим объемом данных могут быть заменены на JOIN с фильтрацией или использованием индексов.
6. Пошаговая проверка изменений. После изменения структуры таблицы или добавления индекса, повторите EXPLAIN, чтобы убедиться, что запрос стал быстрее и использует оптимальные индексы.
Кэширование результатов запросов для повторного использования
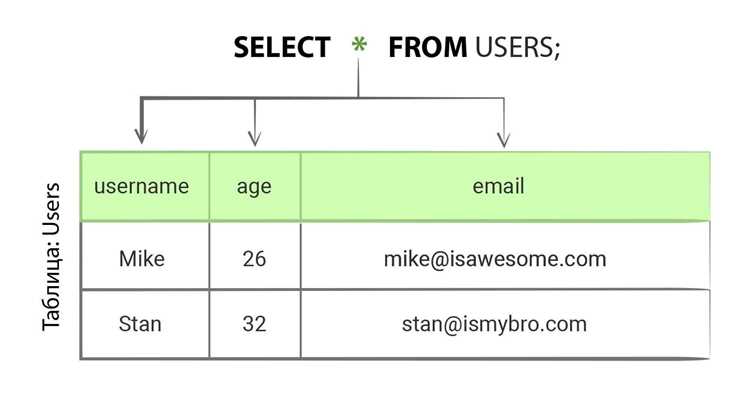
Кэширование позволяет сократить нагрузку на базу, сохраняя результаты часто выполняемых запросов. В MySQL применяются несколько подходов: встроенный query cache (устаревший в MySQL 8.0), внешние кэширующие слои и кэширование на уровне приложения.
1. Использование внешнего кэша. Redis или Memcached хранят результаты SELECT-запросов. При повторном выполнении проверяется наличие данных в кэше, что исключает обращение к таблицам. Ключи кэша формируют на основе текста запроса или параметров фильтрации.
2. Фрагментарное кэширование. Кэшируют не весь результат, а отдельные части: агрегаты, списки идентификаторов, часто используемые JOIN. Это снижает расход памяти и ускоряет выборку.
3. Управление временем жизни (TTL). Устанавливают срок хранения данных в кэше. Для динамических таблиц TTL выбирают короткий (секунды–минуты), для редко изменяемых – длинный (часы–дни). При изменении данных TTL может быть сброшен.
4. Кэширование на уровне приложения. Хранение результатов в переменных, объектах или локальной базе (например SQLite) для повторного использования в течение одной сессии или запроса пользователя. Уменьшает количество сетевых вызовов к MySQL.
5. Индексирование кэша. Для ускоренного доступа к данным в кэше используют хеши ключей, упорядоченные списки и структуры типа sorted set в Redis. Это позволяет быстро находить нужные записи без перебора всего кэша.
6. Контроль актуальности. При изменении данных таблиц необходимо инвалидировать кэш. Поддержка триггеров или механизма публикации изменений гарантирует синхронизацию кэша с базой.
Разделение таблиц и партиционирование для ускорения выборки

Партиционирование разбивает большие таблицы на логические сегменты, позволяя MySQL читать только нужные части данных. Типы партиционирования: RANGE, LIST, HASH, KEY.
1. RANGE и LIST. Используются для данных с диапазонами дат, чисел или категорий. Например, RANGE-партиционирование по дате позволяет выполнять SELECT только по нужным месяцам, сокращая чтение строк.
2. HASH и KEY. Разделяют данные равномерно по вычисляемому хешу. Эффективны для равномерного распределения нагрузки при больших таблицах без явного диапазона.
3. Горизонтальное разделение (шардинг). Таблица разбивается на несколько отдельных таблиц с одинаковой структурой по диапазонам идентификаторов или другим критериям. Это снижает объем данных для каждого запроса.
4. Индексирование партиций. Внутри каждой партиции сохраняются собственные индексы. Запросы с фильтром по ключу партиционирования используют только соответствующую партицию, уменьшая время выборки.
5. Ограничение числа партиций. Слишком большое количество партиций увеличивает накладные расходы MySQL. Оптимальное количество зависит от объема данных и структуры запросов, обычно до нескольких сотен.
6. Мониторинг производительности. EXPLAIN PARTITIONS позволяет определить, какие партиции задействуются запросом. Неиспользуемые партиции указывают на необходимость пересмотра условий WHERE или структуры партиционирования.
Вопрос-ответ:
Что показывает команда EXPLAIN и как её использовать для ускорения запросов?
EXPLAIN отображает план выполнения SELECT-запроса: порядок чтения таблиц, используемые индексы, тип соединений и количество обрабатываемых строк. Анализ этих данных помогает выявить медленные участки, например полный перебор таблицы (type = ALL) или операции Using temporary и Using filesort. На основе EXPLAIN можно добавить индексы, изменить условия WHERE или структуру JOIN, чтобы запросы читали меньше строк и использовали оптимальные индексы.
Как правильно использовать индексы для ускорения выборки данных?
Индексы сокращают количество строк, которые MySQL просматривает при выборке. Для фильтров и соединений создают индексы по колонкам, участвующим в WHERE и JOIN. Составные индексы полезны, если запросы используют несколько колонок одновременно. Важно проверять через EXPLAIN, что индекс реально применяется (поле key), иначе оптимизация не даст результата. Индексы на часто изменяемых полях могут замедлять INSERT и UPDATE, поэтому баланс между чтением и записью учитывается.
Какие методы кэширования запросов подходят для повторного использования результатов?
Для кэширования используют внешние системы, например Redis или Memcached, и хранение результатов на уровне приложения. Результаты SELECT сохраняют с ключами, формируемыми по тексту запроса или параметрам. В кэш помещают полные результаты или фрагменты, например агрегаты или списки идентификаторов. TTL задаёт срок жизни данных, а при обновлении таблиц кэш необходимо инвалидировать, чтобы не возвращать устаревшие значения.
В каких случаях имеет смысл разделять таблицы и использовать партиционирование?
Партиционирование применяют для больших таблиц, где обычные индексы недостаточно ускоряют выборку. RANGE или LIST подходят для диапазонов дат и категорий, HASH и KEY — для равномерного распределения. Горизонтальное разделение (шардинг) уменьшает объем данных для каждого запроса. При этом важно поддерживать индексы внутри каждой партиции и контролировать число партиций, чтобы не увеличить накладные расходы на выполнение запросов.
Как снизить нагрузку на MySQL при повторяющихся сложных запросах?
Используют кэширование и фрагментацию данных. Результаты запросов сохраняют в Redis, Memcached или в памяти приложения, чтобы повторные вызовы не обрабатывали всю таблицу. Разделение таблиц на партиции или шардинг позволяет работать только с нужными сегментами. Оптимизация индексов и фильтров уменьшает количество строк для чтения. Также применяют агрегирование данных заранее, чтобы SELECT возвращал уже подготовленные результаты без вычислений на лету.
Как правильно оптимизировать выборку больших таблиц в MySQL без снижения точности данных?
Для ускорения работы с большими таблицами сначала анализируют запрос с помощью EXPLAIN, чтобы определить, какие индексы используются и какие операции вызывают полное чтение таблицы или сортировку на диске. Добавляют индексы по колонкам, участвующим в WHERE и JOIN, при необходимости используют составные индексы. Для часто повторяющихся запросов применяют кэширование результатов в Redis, Memcached или на уровне приложения. Разделение таблиц на партиции или шардинг позволяет читать только релевантные сегменты данных, уменьшая объем обрабатываемых строк. Ограничение выборки через точные фильтры и LIMIT также снижает нагрузку без потери данных. Мониторинг через EXPLAIN после изменений помогает убедиться, что оптимизация действительно ускорила выполнение запроса.