Содержание статьи

В Python часто требуется определить не только наибольшее значение в списке, но и второе по величине. Например, при анализе результатов тестов, продаж или любых числовых данных важно выделить второй по значению элемент, чтобы оценить распределение и выявить аномалии.
Существует несколько способов найти второе максимальное число. Простейший вариант – отсортировать список и выбрать предпоследний элемент, однако это увеличивает время выполнения для больших массивов данных. Альтернативный подход – использовать функцию max() дважды с удалением максимума, что экономит память и ускоряет обработку.
При работе со списками необходимо учитывать дубликаты. Если список содержит несколько одинаковых максимальных значений, стандартный поиск второго максимума через сортировку или max() может вернуть некорректный результат. В таких случаях стоит применять множества (set) для исключения повторов и корректного определения второго наибольшего числа.
Для больших массивов и потоковых данных полезны встроенные модули, например heapq, которые позволяют быстро получить два наибольших элемента без полной сортировки списка. Выбор метода зависит от размера данных, необходимости учитывать дубликаты и требований к производительности.
Использование функции sorted для нахождения второго максимума

Функция sorted() позволяет упорядочить элементы списка по возрастанию или убыванию. Для нахождения второго максимального значения этот метод удобен, когда список небольшой и производительность не критична.
Пример последовательности действий:
- Создать исходный список чисел, например: numbers = [4, 7, 2, 9, 5].
- Применить sorted() с параметром reverse=True для сортировки по убыванию: sorted_numbers = sorted(numbers, reverse=True).
- Выбрать второй элемент отсортированного списка: second_max = sorted_numbers[1].
Важно учитывать дубликаты. Если список содержит одинаковые максимальные значения, второй элемент после сортировки может быть равен первому. Чтобы получить уникальное второе значение, рекомендуется сначала преобразовать список в множество:
- Создать множество из списка: unique_numbers = set(numbers).
- Снова применить sorted() и выбрать второй элемент: second_max = sorted(unique_numbers, reverse=True)[1].
Метод с sorted() работает на списках любой длины и с отрицательными числами. Он прост в реализации и читаем, но для больших массивов данных стоит рассмотреть альтернативные методы, которые не требуют полной сортировки.
Применение функции max и удаления максимального элемента
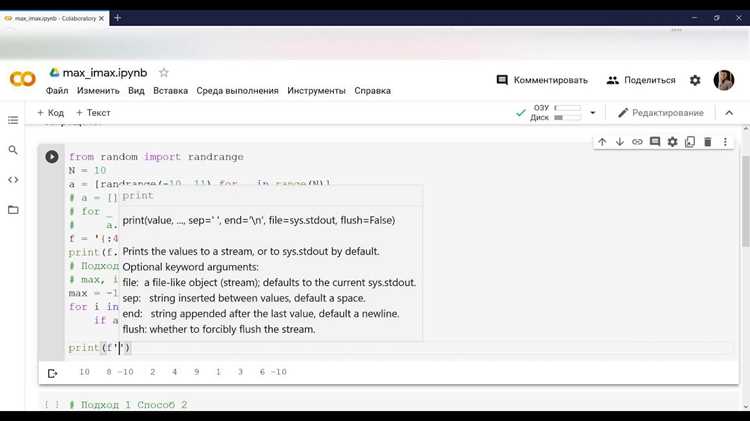
Для нахождения второго максимального значения можно использовать встроенную функцию max() без полной сортировки списка. Этот метод экономит ресурсы на больших массивах.
Алгоритм действий:
- Определить максимальное значение в списке: first_max = max(numbers).
- Удалить все вхождения максимума: numbers_without_max = [x for x in numbers if x != first_max].
- Вычислить второй максимум: second_max = max(numbers_without_max).
Метод учитывает дубликаты: если максимальное значение встречается несколько раз, оно полностью исключается перед поиском второго максимума. Для списков с одним уникальным элементом нужно добавить проверку, чтобы избежать ошибки ValueError.
Этот способ удобен, когда важна минимизация операций сортировки и необходим точный контроль над исключением максимальных значений из анализа.
Нахождение второго максимума с помощью цикла for

Цикл for позволяет найти второе максимальное значение без использования сортировки и дополнительных функций. Метод удобен для потоковых данных и списков, которые нельзя изменять напрямую.
Пример реализации:
- Инициализировать две переменные: first_max и second_max, присвоив им минимальные значения, например float(‘-inf’).
- Пройтись по каждому элементу списка:
- Если текущий элемент больше first_max, присвоить second_max = first_max, а first_max = element.
- Если элемент меньше first_max, но больше second_max, присвоить second_max = element.
- После завершения цикла переменная second_max будет содержать второе максимальное значение.
Метод корректно работает с отрицательными числами и повторяющимися значениями. Для пустого списка или списка с одним уникальным элементом требуется проверка, чтобы избежать некорректного результата.
Использование множества (set) для исключения дубликатов
Множества (set) в Python автоматически удаляют повторяющиеся значения. Это позволяет корректно определить второе максимальное число, когда список содержит одинаковые элементы.
Пример использования:
- Преобразовать список в множество: unique_numbers = set(numbers).
- Проверить, что в множестве больше одного элемента. Если нет – второго максимума не существует.
- Использовать функцию max() для нахождения первого максимума: first_max = max(unique_numbers).
- Удалить его из множества: unique_numbers.remove(first_max).
- Вычислить второй максимум: second_max = max(unique_numbers).
Метод подходит для списков с повторяющимися значениями и работает с отрицательными числами. Он упрощает обработку данных и предотвращает ошибки при наличии дубликатов максимального значения.
Применение функции heapq для получения двух наибольших значений

Модуль heapq предоставляет функции для работы с кучей, что позволяет быстро получить несколько наибольших элементов без полной сортировки списка.
Пример последовательности действий:
- Импортировать модуль: import heapq.
- Использовать функцию nlargest для двух наибольших значений: top_two = heapq.nlargest(2, numbers).
- Второй максимум находится в списке top_two[1].
Метод работает с любыми числовыми данными, включая отрицательные значения, и корректно обрабатывает повторяющиеся элементы. Он подходит для больших списков, так как функция nlargest использует кучу и выполняется быстрее, чем полная сортировка.
Работа со списками, содержащими отрицательные числа и нули
При поиске второго максимального значения важно учитывать, что списки могут содержать отрицательные числа и нули. Простое сравнение без корректной инициализации переменных может дать неправильный результат.
Рекомендации по работе с такими списками:
- Инициализируйте переменные для первого и второго максимума значением float(‘-inf’), чтобы корректно обрабатывать отрицательные числа.
- Используйте методы max() или heapq.nlargest(), которые корректно работают с любыми числами.
- Проверяйте длину списка и количество уникальных значений, чтобы избежать ошибок при вычислении второго максимума.
Пример для визуального понимания:
| Список | Первый максимум | Второй максимум |
|---|---|---|
| [0, -5, -3, -10] | 0 | -3 |
| [-2, -7, -1, -4] | -1 | -2 |
| [0, 0, -1, -1] | 0 | -1 |
Такой подход обеспечивает правильное определение второго максимального значения независимо от знака чисел и наличия нулей.
Обработка пустых списков и списков с одним элементом
При поиске второго максимального значения важно учитывать ситуации, когда список пустой или содержит только один элемент. Без проверки такие случаи вызывают ошибки при использовании max() или индексации.
Рекомендации по обработке:
- Проверять длину списка перед вычислением: if len(numbers) < 2.
- Для пустого списка возвращать None или сообщение об отсутствии данных.
- Если список содержит один элемент, можно вернуть этот элемент как первый максимум и None для второго.
- При использовании множества (set) проверять количество уникальных значений: if len(set(numbers)) < 2.
Пример обработки:
- numbers = [] → second_max = None
- numbers = [5] → second_max = None
- numbers = [7, 7] → second_max = None
Эти меры предотвращают ошибки и обеспечивают корректную работу алгоритмов поиска второго максимума в любых условиях.
Нахождение второго максимума в словарях и других коллекциях

Во многих случаях данные представлены не списками, а словарями или другими коллекциями. Для нахождения второго максимума необходимо правильно извлечь числовые значения.
Примеры действий для словаря:
- Получить значения словаря: values = list(my_dict.values()).
- Удалить дубликаты при необходимости: unique_values = list(set(values)).
- Использовать любой подход для поиска второго максимума: sorted(), max() или heapq.nlargest().
Для других коллекций, например tuple или deque, последовательность действий аналогична:
- Преобразовать коллекцию в список, если она не поддерживает индексацию.
- Удалить дубликаты при необходимости.
- Применить выбранный метод поиска второго максимума.
Такой подход позволяет работать с любыми структурами данных, обеспечивая корректное вычисление второго наибольшего значения независимо от формата коллекции.
Вопрос-ответ:
Как найти второе максимальное значение в списке с повторяющимися числами?
Если список содержит одинаковые элементы, простой поиск второго максимума через сортировку или max() может вернуть то же число, что и максимум. Чтобы избежать этого, сначала преобразуйте список в множество (set), удаляющее дубликаты, а затем примените метод поиска второго максимума, например, max() после удаления первого максимума.
Можно ли найти второй максимум без сортировки списка?
Да. Для этого создают две переменные, first_max и second_max, и перебирают элементы через цикл for. Если элемент больше first_max, обновляют обе переменные, если элемент меньше first_max, но больше second_max, обновляют только second_max. Этот метод подходит для больших списков и потоковых данных.
Как получить второй максимум при работе со словарем?
В словаре нужно извлечь числовые значения с помощью values(), затем преобразовать их в список. После этого можно использовать любой из методов поиска второго максимума — sorted(), max() или heapq.nlargest(). Если значения повторяются, рекомендуется предварительно удалить дубликаты с помощью set.
Что делать, если список пустой или содержит один элемент?
Если список пустой или имеет только один уникальный элемент, второго максимума не существует. В таких случаях алгоритмы должны возвращать None или специальное сообщение. При использовании множества нужно проверять, что количество уникальных элементов больше одного.
Подходит ли метод heapq для больших списков?
Да. Функция heapq.nlargest() позволяет быстро получить несколько наибольших элементов без полной сортировки. Для поиска второго максимума достаточно использовать heapq.nlargest(2, numbers)[1]. Метод корректно работает с отрицательными числами и повторяющимися значениями.
Как найти второе максимальное значение в списке с отрицательными числами?
При работе со списком, содержащим отрицательные числа, обычная инициализация переменных для первого и второго максимума через ноль может привести к ошибкам. Чтобы этого избежать, используйте float(‘-inf’) для начальных значений. Затем переберите элементы через цикл или примените функции max() или heapq.nlargest(), чтобы определить первый и второй наибольшие элементы.
Можно ли найти второй максимум в списке без удаления элементов?
Да, можно. Вместо удаления элементов используют две переменные для первого и второго максимума и обновляют их при обходе списка. Если текущий элемент больше первого максимума, первое значение переносится во второе, а первое обновляется новым элементом. Если элемент меньше первого, но больше второго, обновляется только второе значение. Такой подход сохраняет исходный список без изменений.