Содержание статьи

Elastic Stack – это набор инструментов для сбора, хранения, анализа и визуализации данных в реальном времени. Он включает Elasticsearch для хранения и поиска информации, Logstash для обработки и передачи данных, Kibana для визуализации и Elastic Agent для сбора логов и метрик. Такая комбинация позволяет централизованно управлять данными из различных источников, включая серверные логи, базы данных и сетевые события.
Elasticsearch использует структуру индексов для организации информации, что ускоряет поиск даже при миллионах записей. Правильная настройка индексов и шардирования критически важна для быстрого отклика и масштабирования. Logstash поддерживает более 200 плагинов для подключения к различным источникам данных и их предварительной обработки, включая фильтрацию, нормализацию и преобразование форматов.
Kibana предоставляет интерактивные дашборды, графики и отчеты, что позволяет оперативно выявлять аномалии и анализировать тенденции. Настройка визуализаций и дашбордов должна учитывать структуру данных и цели мониторинга. Elastic Agent облегчает развертывание агентов на множестве серверов и упрощает сбор логов и метрик без ручной конфигурации каждого узла.
Использование Elastic Stack позволяет централизованно собирать данные и быстро получать инсайты, а также интегрироваться с внешними системами для автоматизации процессов анализа и оповещений. Оптимизация потоков данных и мониторинг состояния компонентов помогают поддерживать стабильную работу инфраструктуры при увеличении объема данных.
Компоненты Elastic Stack и их функции

Elastic Stack состоит из нескольких специализированных инструментов, каждый из которых выполняет конкретные задачи в обработке и анализе данных:
- Elasticsearch – распределенная поисковая и аналитическая система. Хранит данные в виде индексов и поддерживает быстрый поиск по миллионам записей. Рекомендуется настраивать шардирование и репликацию для балансировки нагрузки и отказоустойчивости.
- Logstash – инструмент для сбора, трансформации и передачи данных. Поддерживает подключение к множеству источников через плагины и позволяет фильтровать, нормализовать и преобразовывать данные перед отправкой в Elasticsearch.
- Kibana – визуализатор данных и инструмент построения дашбордов. Позволяет создавать графики, диаграммы и интерактивные панели мониторинга, что облегчает анализ тенденций и выявление аномалий.
- Elastic Agent – единый агент для сбора логов, метрик и данных об инцидентах. Упрощает развертывание на множестве серверов и обеспечивает централизованное управление конфигурацией.
- Beats – легковесные агенты для передачи данных в Elasticsearch или Logstash. Существуют специализированные версии: Filebeat для логов, Metricbeat для метрик систем и приложений, Packetbeat для сетевых данных.
Каждый компонент можно использовать автономно, но максимальная эффективность достигается при их совместном использовании. Рекомендация: сначала организовать сбор данных через Beats и Logstash, затем настроить индексы в Elasticsearch и визуализировать результаты в Kibana для мониторинга и анализа.
Как настроить сбор данных с разных источников

Для сбора данных в Elastic Stack используют комбинацию Beats, Logstash и Elastic Agent. Выбор инструмента зависит от типа источника и объема данных.
Filebeat применяют для отправки логов приложений, системных логов и событий. Он поддерживает модульные конфигурации для популярных сервисов, таких как Nginx, Apache, MySQL. Рекомендуется использовать multiline-парсинг для логов с многострочными событиями.
Metricbeat собирает метрики серверов, контейнеров и приложений. Можно настроить сбор CPU, памяти, дисковых операций, сетевых статистик и метрик баз данных. Для комплексного мониторинга следует включить все соответствующие модули сервисов.
Packetbeat анализирует сетевой трафик, собирая данные о запросах, протоколах и задержках. Его используют для мониторинга производительности API, баз данных и сетевых взаимодействий.
Logstash обеспечивает централизованную обработку данных с более сложными трансформациями. Он подключается к различным источникам через входные плагины (TCP, HTTP, Kafka, JDBC) и позволяет фильтровать, обогащать и преобразовывать данные перед отправкой в Elasticsearch.
Elastic Agent объединяет функции Beats и упрощает управление на множестве хостов. Его можно развернуть через Fleet для автоматической регистрации устройств и централизованного обновления конфигураций.
Рекомендации: сначала определить критические источники данных, выбрать соответствующие Beats или Logstash-плагины, настроить фильтры и тестировать сбор на небольшой выборке перед массовым развертыванием. Это снижает нагрузку на систему и предотвращает потерю данных.
Процесс индексации и хранения информации в Elasticsearch

Elasticsearch хранит данные в виде документов JSON, объединенных в индексы. Каждый документ имеет уникальный идентификатор и поля, по которым выполняется поиск. Индекс можно рассматривать как логическую структуру для группировки схожих данных.
Для масштабирования и отказоустойчивости индексы делятся на шарды. Каждый шард представляет собой отдельный фрагмент данных и может храниться на разных узлах кластера. Рекомендуется выбирать количество шардов с учетом объема данных и количества нод, чтобы избежать перегрузки отдельных узлов.
Процесс индексации включает анализ текста через анализаторы, токенизацию и нормализацию данных. Это обеспечивает корректный поиск и фильтрацию, включая работу с языковыми особенностями, стоп-словами и синонимами. Для больших объемов данных следует использовать bulk API, чтобы снизить нагрузку и ускорить вставку документов.
Elasticsearch поддерживает репликацию шардов, что обеспечивает резервирование и повышает доступность данных. Рекомендуется настраивать хотя бы одну реплику для критически важных индексов. Настройка refresh interval позволяет балансировать между скоростью индексации и доступностью свежих данных для поиска.
Для контроля структуры данных полезно создавать шаблоны индексов, определяющие типы полей и правила анализа. Это упрощает автоматическое создание новых индексов с нужной конфигурацией и предотвращает ошибки при хранении разнообразных данных.
Поиск и фильтрация данных с использованием Kibana
Kibana предоставляет инструменты для интерактивного поиска, фильтрации и визуализации данных, хранящихся в Elasticsearch. Основной способ работы – использование запросов на языке Lucene или KQL (Kibana Query Language), позволяющих строить точные условия поиска по полям документов.
Фильтры можно создавать по любым полям индекса, включая числовые, строковые, даты и булевы значения. Рекомендация: использовать фильтры вместо сложных запросов для улучшения производительности дашбордов и ускорения отклика интерфейса.
Для анализа временных рядов полезно применять временные фильтры, выбирая диапазоны дат или интервал агрегации. Это позволяет быстро выявлять изменения метрик, пики нагрузки и аномалии. Визуальные элементы, такие как гистограммы, диаграммы и карты тепла, помогают оценить распределение данных и выявить закономерности.
Kibana поддерживает комбинированные фильтры и сохранение поисковых условий в виде сохраненных объектов (Saved Searches). Это упрощает повторное использование сложных запросов и дашбордов, а также интеграцию с алертингом и отчетами.
Для работы с большими индексами рекомендуется использовать агрегации для группировки и подсчета данных вместо получения всех документов. Практическая рекомендация: заранее планировать структуру визуализаций и фильтров, чтобы минимизировать нагрузку на кластер и ускорить отклик интерфейса Kibana.
Мониторинг и визуализация показателей системы
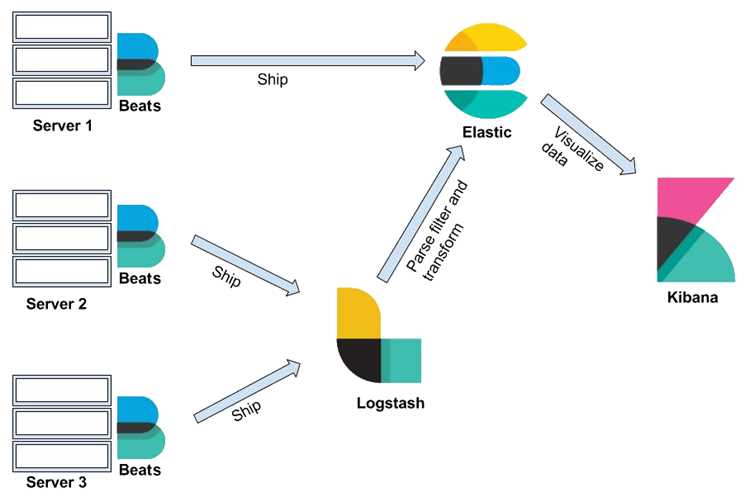
Для контроля состояния Elastic Stack используют встроенные возможности Kibana и Metricbeat. Metricbeat собирает метрики узлов Elasticsearch, нагрузки CPU, использования памяти, дисковых операций и сетевых интерфейсов. Эти данные позволяют оценивать производительность и выявлять узкие места.
Kibana позволяет создавать дашборды с визуализациями в виде графиков, гистограмм и круговых диаграмм. Рекомендация: объединять метрики узлов, индексов и запросов на одной панели для комплексного анализа состояния кластера. Это помогает быстро обнаруживать перегрузки, сбои или аномалии в работе сервисов.
Для мониторинга логов и событий используют Filebeat и Logstash с последующей визуализацией в Kibana. Можно строить панели для отслеживания ошибок, предупреждений и событий безопасности. Настройка оповещений через Kibana Alerting позволяет получать уведомления о критических изменениях в реальном времени.
Агрегации в Kibana позволяют группировать данные по временным интервалам, типам событий и хостам. Практическая рекомендация: использовать агрегации для выявления тенденций, предотвращения перегрузок и прогнозирования роста нагрузки на инфраструктуру.
Интеграция Elastic Stack с внешними приложениями

Elastic Stack поддерживает интеграцию с внешними системами через API, плагины и стандартные протоколы передачи данных. Наиболее распространенные способы включают REST API, Webhooks и соединение через Logstash или Beats.
REST API Elasticsearch позволяет внешним приложениям отправлять запросы на поиск, индексацию и агрегацию данных. API поддерживает работу с документами, индексами и кластером, обеспечивая полный контроль над данными.
Logstash выполняет роль промежуточного слоя, который может получать данные из баз данных, очередей сообщений и HTTP-сервисов, а затем отправлять их в Elasticsearch. Beats и Elastic Agent упрощают интеграцию с приложениями, генерирующими логи и метрики.
Пример интеграции с внешними приложениями:
| Приложение | Метод интеграции | Цель |
|---|---|---|
| MySQL | Logstash JDBC input | Сбор и индексация данных таблиц |
| Apache Kafka | Logstash Kafka input / output | Передача событий и логов в реальном времени |
| Grafana | Elasticsearch datasource | Визуализация метрик и построение дашбордов |
| Slack / Email | Kibana Alerting | Отправка уведомлений о событиях и аномалиях |
Рекомендация: при интеграции с внешними системами заранее планировать структуру данных и форматы обмена, чтобы избежать дублирования и потери информации. Использование API и Logstash-плагинов позволяет автоматизировать сбор данных и минимизировать ручную настройку.
Вопрос-ответ:
Что такое Elastic Stack и для чего он используется?
Elastic Stack — это набор инструментов для сбора, хранения, анализа и визуализации данных. Он включает Elasticsearch для хранения и поиска информации, Logstash для обработки и передачи данных, Kibana для визуализации и Elastic Agent для сбора логов и метрик. Stack применяется для централизованного мониторинга серверов, анализа логов, работы с метриками и построения дашбордов для контроля состояния инфраструктуры.
Как настроить сбор логов и метрик с серверов в Elastic Stack?
Для сбора логов используют Filebeat, который отправляет данные в Elasticsearch или Logstash. Metricbeat собирает системные и прикладные метрики, включая загрузку CPU, использование памяти, дисковые операции и сетевой трафик. Для централизованного управления на множестве серверов применяется Elastic Agent через Fleet. Рекомендуется сначала протестировать конфигурацию на нескольких узлах, чтобы убедиться, что данные собираются корректно и без пропусков.
В чем разница между индексами и шардированием в Elasticsearch?
Индекс в Elasticsearch — это логическая структура для хранения документов JSON, сгруппированных по типу данных или назначению. Каждый индекс может быть разделен на шард — отдельный фрагмент данных, который хранится на одном узле кластера. Шардирование позволяет распределять нагрузку и обеспечивать отказоустойчивость. Дополнительно настраивают реплики шардов для резервирования и повышения доступности данных.
Какие методы поиска и фильтрации данных доступны в Kibana?
В Kibana используют KQL (Kibana Query Language) или Lucene для построения запросов. Фильтры создаются по полям документов, включая строки, числа, даты и булевы значения. Для анализа временных рядов применяют временные фильтры и агрегации, позволяющие группировать данные по периодам или категориям. Saved Searches позволяют сохранять сложные запросы для повторного использования и построения дашбордов.
Как интегрировать Elastic Stack с внешними системами и приложениями?
Интеграция возможна через REST API, Logstash-плагины, Beats и Elastic Agent. Например, Logstash может подключаться к базам данных через JDBC, к очередям сообщений через Kafka или к HTTP-сервисам. Kibana Alerting позволяет отправлять уведомления в Slack или по email. Внешние приложения, такие как Grafana, могут использовать Elasticsearch как источник данных для построения дашбордов и отчетов. Рекомендуется заранее согласовать формат данных и частоту обновления, чтобы не создавать лишнюю нагрузку на кластер.
Как настроить визуализацию метрик сервера в Kibana с использованием Elastic Stack?
Для визуализации метрик сервера сначала нужно собрать данные с помощью Metricbeat, включив модули для CPU, памяти, дисков и сетевых интерфейсов. После отправки данных в Elasticsearch создают индекс-паттерн в Kibana, соответствующий собранным метрикам. Далее формируются визуализации: линейные графики для нагрузки CPU, гистограммы для операций с дисками, круговые диаграммы для распределения памяти. Для анализа динамики используют временные фильтры и агрегации по интервалам. Рекомендуется объединять несколько визуализаций на дашборде, чтобы одновременно видеть все ключевые показатели и быстро реагировать на аномалии.