Содержание статьи

В Java коллекции предоставляют набор инструментов для хранения и обработки данных, но каждая реализация имеет свои особенности по скорости доступа, вставки и удаления элементов. ArrayList подходит для быстрого доступа по индексу, тогда как LinkedList оптимизирован для частых вставок и удалений в середине списка. Понимание этих различий помогает сократить время выполнения операций и снизить нагрузку на память.
HashSet обеспечивает хранение уникальных элементов с постоянным временем добавления и поиска, но не сохраняет порядок. Если важен отсортированный порядок, лучше использовать TreeSet, который поддерживает автоматическую сортировку элементов по естественному порядку или через Comparator. Выбор структуры напрямую влияет на поведение алгоритмов поиска и обработки данных.
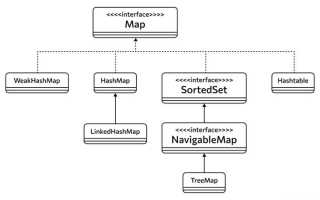
При работе с отображениями ключ-значение HashMap обеспечивает быстрый доступ по ключу без гарантии порядка, LinkedHashMap сохраняет порядок вставки, а TreeMap поддерживает сортировку ключей. Знание этих особенностей позволяет выбрать коллекцию, подходящую для задач кэширования, статистики или упорядоченного хранения информации.
Для многопоточных приложений следует использовать коллекции из пакета java.util.concurrent, например ConcurrentHashMap или CopyOnWriteArrayList, чтобы избежать блокировок и ошибок синхронизации. Анализ конкретных требований к частоте чтения и записи помогает правильно подобрать коллекцию для многопоточного кода.
Сравнение List и Set для хранения уникальных и повторяющихся элементов
В Java интерфейсы List и Set решают разные задачи по хранению данных. List позволяет хранить элементы в порядке вставки и допускает дубликаты, что удобно при формировании последовательностей или при обработке исторических данных. Set автоматически исключает повторяющиеся элементы, обеспечивая уникальность коллекции, что важно для формирования множества уникальных идентификаторов или ключей.
С точки зрения производительности, операции вставки и поиска в HashSet выполняются за время близкое к O(1), тогда как в ArrayList поиск элемента по значению требует O(n). При больших объёмах данных выбор структуры напрямую влияет на скорость выполнения кода и расход памяти.
Ниже приведена сравнительная таблица основных характеристик List и Set:
| Характеристика | List | Set |
|---|---|---|
| Поддержка дубликатов | Да | Нет |
| Порядок элементов | Сохраняется | Не гарантируется (исключение TreeSet – сортировка) |
| Доступ по индексу | Есть (ArrayList, LinkedList через итератор) | Нет |
| Время вставки | O(1) для ArrayList добавление в конец, O(n) для вставки в середину | O(1) для HashSet, O(log n) для TreeSet |
| Поиск элемента | O(n) | O(1) для HashSet, O(log n) для TreeSet |
Рекомендации: List использовать для последовательностей с повторяющимися элементами и когда важен порядок вставки. Set применять для уникальных наборов данных, где критично быстрое добавление и поиск без дубликатов. Для сортировки лучше использовать TreeSet, а для быстрого доступа без порядка – HashSet.
Когда использовать ArrayList и LinkedList в проектах
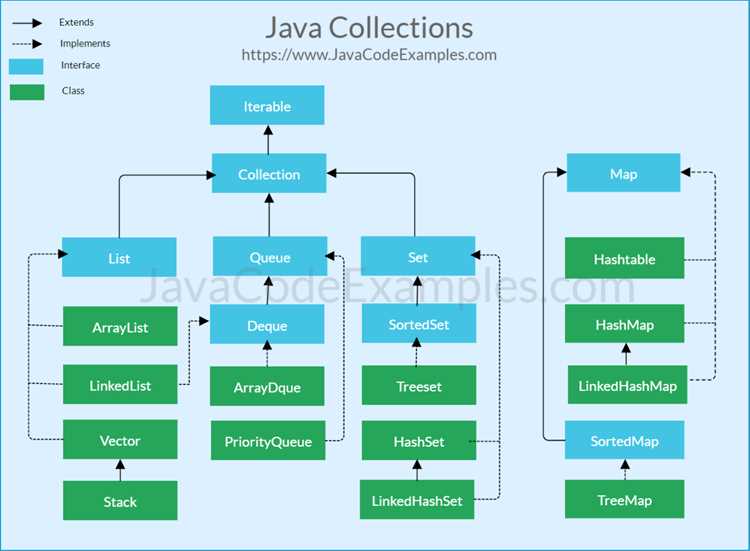
ArrayList хранит элементы в виде динамического массива. Доступ по индексу выполняется за время O(1), поэтому ArrayList подходит для частого чтения элементов и последовательного обхода. Вставка или удаление элемента в середине списка требует сдвига оставшихся элементов, что выполняется за O(n), поэтому такие операции следует минимизировать.
LinkedList реализован как двусвязный список. Вставка и удаление элементов в начале или середине списка выполняются за O(1) при наличии ссылки на узел, а доступ по индексу требует O(n). LinkedList лучше использовать для реализации очередей, стеков и структур с частыми изменениями размеров, когда скорость добавления и удаления важнее скорости доступа по индексу.
Ниже приведены ключевые показатели для сравнения ArrayList и LinkedList:
| Операция | ArrayList | LinkedList |
|---|---|---|
| Доступ по индексу | O(1) | O(n) |
| Добавление в конец | O(1) амортизированное | O(1) |
| Вставка в середину | O(n) | O(1) при наличии узла |
| Удаление элемента | O(n) | O(1) при наличии узла |
| Использование памяти | Ниже, хранит только массив элементов | Выше, хранит ссылки на предыдущий и следующий элементы |
Выбор коллекции зависит от частоты операций чтения и модификации. Для частого доступа по индексу и редких изменений – ArrayList, для структур с интенсивными вставками и удалениями – LinkedList. В многопоточных сценариях дополнительно следует учитывать синхронизацию при работе с этими коллекциями.
Выбор подходящей реализации Map для поиска по ключу
В Java интерфейс Map предоставляет структуру для хранения пар ключ-значение. Для быстрого поиска по ключу чаще всего используют HashMap, которая обеспечивает доступ к элементу за время O(1) при равномерном распределении хешей. HashMap не сохраняет порядок элементов, поэтому подходит для кэширования данных и частого обращения по ключу.
LinkedHashMap сохраняет порядок вставки элементов и позволяет перебирать записи в порядке добавления. Это удобно, когда необходимо создавать упорядоченные кэши или вести журнал действий с сохранением последовательности операций.
TreeMap реализует сортированное отображение на основе красно-чёрного дерева. Время поиска и вставки составляет O(log n). TreeMap используется, когда требуется автоматически упорядочивать ключи по естественному порядку или по пользовательскому Comparator, например для построения отсортированных отчетов или справочников.
При выборе реализации Map следует учитывать следующие критерии:
| Характеристика | HashMap | LinkedHashMap | TreeMap |
|---|---|---|---|
| Скорость поиска по ключу | O(1) | O(1) | O(log n) |
| Сортировка или порядок элементов | Нет | Сохраняет порядок вставки | Автоматическая сортировка по ключу |
| Допустимость null ключей | Да, один null | Да, один null | Нет |
| Использование в многопоточном коде | Не потокобезопасен | Не потокобезопасен | Не потокобезопасен |
Для проектов с большим количеством вставок и быстрым доступом по ключу выбирайте HashMap. Если требуется сохранять порядок операций – LinkedHashMap. Для автоматической сортировки ключей – TreeMap.
Использование Queue и Deque для организации очередей и стеков

Интерфейс Queue предназначен для хранения элементов с доступом по принципу FIFO (first in, first out). Наиболее распространённые реализации – LinkedList и PriorityQueue. LinkedList обеспечивает добавление и удаление элементов с начала и конца за O(1), что удобно для простых очередей. PriorityQueue поддерживает автоматическую сортировку элементов по приоритету, что позволяет строить очереди задач с разными уровнями важности.
Deque расширяет Queue и позволяет работать с обоими концами коллекции, обеспечивая функциональность стека (LIFO) и двухсторонней очереди. ArrayDeque эффективен для операций push, pop и peek, выполняемых за O(1), и не имеет ограничения на размер, кроме объёма памяти. LinkedList также реализует Deque, обеспечивая гибкость при вставках и удалениях в середине структуры.
Ниже приведена сравнительная таблица для выбора между Queue и Deque:
| Характеристика | Queue | Deque |
|---|---|---|
| Принцип работы | FIFO | FIFO и LIFO |
| Основные реализации | LinkedList, PriorityQueue | ArrayDeque, LinkedList |
| Вставка/удаление с начала | O(1) для LinkedList | O(1) для ArrayDeque и LinkedList |
| Вставка/удаление с конца | Не поддерживается напрямую | O(1) |
| Сортировка по приоритету | PriorityQueue поддерживает | Нет |
Для стандартной очереди задач выбирайте LinkedList или PriorityQueue. Для реализации стека или двусторонней очереди оптимальным выбором будет ArrayDeque, благодаря быстрому доступу к обоим концам коллекции.
Особенности работы с HashSet и TreeSet при сортировке и поиске
HashSet реализует структуру на основе хеш-таблицы. Вставка, удаление и поиск элементов выполняются за O(1) при равномерном распределении хешей. HashSet не сохраняет порядок элементов, поэтому он подходит для задач, где важна уникальность данных, но порядок не критичен.
TreeSet использует красно-чёрное дерево, обеспечивая автоматическую сортировку элементов по естественному порядку или через Comparator. Время поиска, вставки и удаления составляет O(log n). TreeSet оптимален для отсортированных множеств, построения диапазонных запросов и поиска минимальных или максимальных значений.
Ниже приведена сравнительная таблица характеристик HashSet и TreeSet:
| Характеристика | HashSet | TreeSet |
|---|---|---|
| Скорость поиска | O(1) | O(log n) |
| Скорость вставки и удаления | O(1) | O(log n) |
| Сортировка | Нет | Автоматическая |
| Порядок элементов | Не гарантируется | По возрастанию или Comparator |
| Использование памяти | Ниже, хранит только хеши | Выше, хранит ссылки на потомков |
Выбор между HashSet и TreeSet зависит от задач: для быстрого поиска и вставки без сортировки – HashSet, для отсортированных наборов и диапазонных операций – TreeSet.
Применение Concurrent коллекций в многопоточном коде
В многопоточных приложениях стандартные коллекции Java, такие как HashMap или ArrayList, не гарантируют корректную работу при одновременном доступе из нескольких потоков. Для безопасной работы используют коллекции из пакета java.util.concurrent, которые реализуют механизмы синхронизации и минимизируют блокировки.
Основные Concurrent коллекции и их особенности:
- ConcurrentHashMap – обеспечивает параллельный доступ к частям карты, позволяя многим потокам выполнять операции чтения и записи без глобальной блокировки. Идеальна для кэширования и хранения статистики.
- CopyOnWriteArrayList – оптимизирована для сценариев с частыми чтениями и редкими модификациями. Каждое изменение создает копию массива, что исключает проблемы синхронизации.
- ConcurrentLinkedQueue – неблокирующая очередь на основе связанного списка, поддерживает быстрые операции добавления и удаления элементов с обоих концов.
- ConcurrentSkipListMap – сортированная карта с параллельным доступом, обеспечивает время O(log n) для поиска и вставки. Полезна для хранения упорядоченных данных в многопоточной среде.
Рекомендации по использованию:
- Для больших объёмов данных с интенсивными чтениями и редкими изменениями – CopyOnWriteArrayList.
- Для кэшей и структур ключ-значение с высокой конкуренцией – ConcurrentHashMap.
- Для очередей задач, где важна минимальная блокировка потоков – ConcurrentLinkedQueue.
- Для сортированных коллекций с многопоточным доступом – ConcurrentSkipListMap.
Выбор правильной Concurrent коллекции позволяет избежать состояния гонки, снизить вероятность ошибок синхронизации и поддерживать стабильное поведение приложения при высокой нагрузке.
Разница между HashMap, TreeMap и LinkedHashMap при хранении данных

Коллекции Map в Java имеют разные реализации, каждая из которых оптимизирована под конкретные задачи хранения и поиска данных. Выбор структуры влияет на порядок элементов, скорость доступа и использование памяти.
Основные особенности:
- HashMap – реализована на основе хеш-таблицы. Обеспечивает быстрый доступ по ключу O(1), не сохраняет порядок элементов. Подходит для больших наборов данных, где важна скорость поиска и вставки, а порядок не критичен.
- LinkedHashMap – расширяет HashMap, сохраняя порядок вставки элементов. Поддерживает быстрый доступ по ключу и последовательный перебор элементов. Используется для реализации кэшей и структур, где важен порядок обработки.
- TreeMap – реализована через красно-чёрное дерево, обеспечивает автоматическую сортировку ключей. Операции поиска, вставки и удаления выполняются за O(log n). Применяется для хранения отсортированных данных и диапазонных запросов.
Сравнительная таблица характеристик:
| Характеристика | HashMap | LinkedHashMap | TreeMap |
|---|---|---|---|
| Скорость поиска | O(1) | O(1) | O(log n) |
| Сортировка | Нет | Порядок вставки | Автоматическая сортировка ключей |
| Поддержка null ключей | Да, один null | Да, один null | Нет |
| Использование памяти | Ниже | Выше, хранит ссылки для порядка | Выше, хранит ссылки на потомков |
Рекомендации:
- Для быстрого поиска без сохранения порядка – HashMap.
- Для упорядоченного перебора или реализации LRU-кэша – LinkedHashMap.
- Для отсортированных наборов данных и диапазонных операций – TreeMap.
Критерии выбора коллекции для больших объёмов данных

При работе с большими объёмами данных важны скорость операций и расход памяти. Для последовательного доступа и частого чтения лучше использовать ArrayList, так как доступ по индексу выполняется за O(1). При интенсивных вставках и удалениях в середине списка эффективнее LinkedList, так как операции выполняются за O(1) при наличии ссылки на узел.
Для хранения уникальных элементов без сортировки оптимален HashSet, обеспечивающий O(1) вставки и поиска. Если требуется сортировка, предпочтителен TreeSet с O(log n) для этих операций.
При использовании отображений ключ-значение выбор зависит от задачи:
- HashMap – быстрый доступ и вставка без сохранения порядка.
- LinkedHashMap – сохранение порядка вставки при умеренной скорости доступа.
- TreeMap – отсортированные ключи с O(log n) операций, но с большим расходом памяти.
Для многопоточного кода критично использовать ConcurrentHashMap или CopyOnWriteArrayList, чтобы избежать блокировок и ошибок синхронизации. Выбор коллекции должен учитывать частоту чтений и изменений, требования к порядку элементов и доступную память.
Вопрос-ответ:
В каких случаях лучше использовать HashSet вместо ArrayList?
HashSet подходит, когда необходимо хранить уникальные элементы и не важен порядок их добавления. Вставка и поиск выполняются за O(1), что ускоряет работу с большими объёмами данных по сравнению с ArrayList, где поиск элемента требует O(n). HashSet удобен для хранения идентификаторов, тегов или любых данных, где дубликаты недопустимы.
Когда целесообразно применять LinkedList вместо ArrayList?
LinkedList эффективен при частых вставках и удалениях элементов в середине списка, так как эти операции выполняются за O(1 при наличии ссылки на узел). Для последовательного доступа или случайного чтения элементов лучше использовать ArrayList, так как доступ по индексу выполняется за O(1), а в LinkedList это занимает O(n).
Как выбрать между HashMap, LinkedHashMap и TreeMap для хранения пар ключ-значение?
Выбор зависит от требований к порядку и скорости доступа. HashMap обеспечивает быстрый доступ без сохранения порядка. LinkedHashMap сохраняет порядок вставки, что полезно для кэшей или журналов. TreeMap поддерживает сортировку ключей и удобен для построения отсортированных справочников или диапазонных запросов, но операции занимают O(log n).
Когда стоит использовать коллекции из java.util.concurrent?
Concurrent коллекции применяют в многопоточном коде для безопасного доступа без блокировки всей структуры. Например, ConcurrentHashMap позволяет нескольким потокам читать и писать данные одновременно. CopyOnWriteArrayList подходит для сценариев с частым чтением и редкими изменениями, а ConcurrentLinkedQueue используется для очередей задач, где важна минимальная задержка при добавлении и удалении элементов.