Содержание статьи

XML остаётся популярным форматом для обмена данными между сервисами и приложениями. JavaScript предоставляет несколько подходов для чтения и обработки XML, включая DOMParser, XMLHttpRequest и fetch API. Выбор метода зависит от объёма данных, формата источника и требований к асинхронной обработке.
DOMParser позволяет преобразовать строку XML в объект DOM, что даёт доступ к методам поиска элементов, атрибутов и текстового содержимого. Это особенно полезно при работе с небольшими XML-файлами или динамически полученными строками XML с сервера.
XMLHttpRequest и fetch обеспечивают загрузку XML из внешних источников. При использовании fetch можно сразу получить текстовый формат XML и передать его в DOMParser для дальнейшего анализа. XMLHttpRequest поддерживает синхронные и асинхронные запросы, что важно при интеграции с существующими приложениями.
Парсинг XML включает несколько ключевых этапов: получение данных, преобразование их в DOM-структуру, извлечение необходимых элементов и обработка ошибок. Каждая стадия требует точной настройки методов и проверки структуры документа, чтобы избежать ошибок при доступе к тегам и атрибутам.
В этом руководстве рассмотрены практические шаги для работы с XML в JavaScript: от загрузки файла до извлечения данных и сохранения результатов. Примеры будут ориентированы на реальные задачи, включая чтение вложенных тегов, обработку атрибутов и использование современных возможностей языка для упрощения кода.
Выбор метода парсинга XML в JavaScript
Для работы с XML в JavaScript доступны несколько инструментов. DOMParser преобразует строку XML в DOM-объект, предоставляя доступ к методам поиска элементов и атрибутов. Этот метод удобен для небольших файлов и динамически полученных данных с сервера.
XMLHttpRequest позволяет загружать XML-файлы с внешних источников, поддерживая как синхронные, так и асинхронные запросы. Он подходит для приложений, где требуется контролировать процесс загрузки и обработки данных по шагам.
fetch API обеспечивает современный способ получения XML через HTTP-запросы. С его помощью можно получить текст документа и передать его в DOMParser для дальнейшего разбора. fetch упрощает асинхронную работу с сетью и легко интегрируется с промисами и async/await.
Выбор метода зависит от задачи: DOMParser – для быстрого разбора строки, XMLHttpRequest – для контроля загрузки, fetch – для работы с современными асинхронными запросами. Рекомендуется учитывать размер XML, необходимость обработки ошибок и совместимость с браузерами.
Чтение XML-файла с помощью fetch и XMLHttpRequest
Для загрузки XML в JavaScript можно использовать fetch или XMLHttpRequest. Оба метода позволяют получать данные с сервера, но имеют разные подходы к асинхронной обработке.
Пример использования fetch:
- Выполнить запрос к файлу XML: fetch(‘data.xml’).
- Преобразовать ответ в текст: response.text().
- Передать текст в DOMParser для создания DOM-объекта.
Преимущества fetch:
- Работа с промисами и async/await.
- Удобная обработка статусов ответа.
- Чистый синтаксис для асинхронного кода.
Пример использования XMLHttpRequest:
- Создать объект: let xhr = new XMLHttpRequest().
- Настроить запрос методом GET и указать путь к XML.
- Назначить обработчик события onreadystatechange для обработки загруженного документа.
- После успешной загрузки передать xhr.responseXML или xhr.responseText в DOMParser.
Рекомендации:
- Использовать fetch для современных проектов с поддержкой промисов.
- XMLHttpRequest подходит при необходимости синхронной загрузки или совместимости со старыми браузерами.
- Всегда проверять статус ответа и наличие ошибок при загрузке.
Преобразование XML в DOM-объект

Для работы с XML в JavaScript необходимо преобразовать текст документа в объектную модель DOM. Основной инструмент для этого – DOMParser, который принимает строку XML и возвращает DOM-дерево.
Пример использования DOMParser:
let parser = new DOMParser();
let xmlDoc = parser.parseFromString(xmlString, «application/xml»);
Проверка корректности парсинга:
- После parseFromString проверяйте наличие parsererror в документе.
- Если xmlDoc.getElementsByTagName(«parsererror») возвращает элементы, значит XML содержит ошибки.
Рекомендации по работе с DOM-объектом:
- Использовать методы getElementsByTagName, querySelector и querySelectorAll для поиска элементов.
- Доступ к атрибутам осуществляется через element.getAttribute(«атрибут»).
- Для вложенных тегов комбинируйте поиск по родительским элементам и фильтрацию по имени тега.
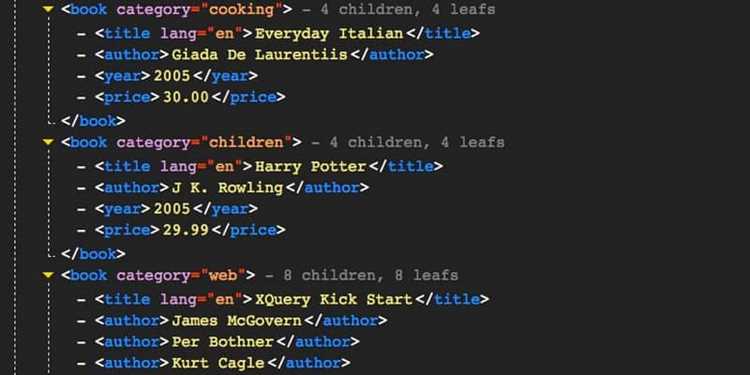
Извлечение данных из XML с использованием getElementsByTagName

getElementsByTagName позволяет получить коллекцию всех элементов с указанным именем тега внутри DOM-объекта XML. Метод возвращает HTMLCollection, которую можно обходить с помощью циклов.
Пример применения:
- Получить все элементы с тегом item: let items = xmlDoc.getElementsByTagName(«item»);
- Обойти коллекцию: for (let i = 0; i < items.length; i++) { … }
- Извлечь текстовое содержимое: let value = items[i].textContent;
- Получить атрибуты элемента: let id = items[i].getAttribute(«id»);
Рекомендации по использованию:
- Для вложенных тегов сначала получите родительский элемент, затем применяйте getElementsByTagName для ограничения области поиска.
- Проверяйте наличие элементов перед обращением к textContent или атрибутам, чтобы избежать ошибок.
- Используйте Array.from() для преобразования коллекции в массив при необходимости работы с методами map или filter.
Использование querySelector для поиска элементов в XML

querySelector и querySelectorAll позволяют находить элементы XML с помощью CSS-селекторов. Эти методы работают на DOM-объекте, полученном через DOMParser, и возвращают первый совпавший элемент или NodeList всех совпадений.
Пример применения:
- Поиск первого элемента item: let firstItem = xmlDoc.querySelector(«item»);
- Поиск всех элементов с классом active: let activeItems = xmlDoc.querySelectorAll(«item.active»);
- Обход найденных элементов: activeItems.forEach(el => { let value = el.textContent; });
- Комбинированный поиск по тегу и атрибуту: let special = xmlDoc.querySelector(«item[id=’123′]»);
Рекомендации по работе:
- Используйте querySelector для сложных условий поиска и фильтрации элементов по атрибутам.
- querySelectorAll возвращает статический NodeList, поэтому изменения DOM после получения списка не обновляют коллекцию автоматически.
- Для получения текста элемента используйте element.textContent, а для атрибутов – element.getAttribute(«атрибут»).
Обработка ошибок при чтении и разборе XML
При работе с XML важно проверять корректность загрузки и структуры документа. Ошибки могут возникать на этапе загрузки через fetch или XMLHttpRequest, а также при разборе с помощью DOMParser.
Основные виды ошибок и способы их обработки:
| Тип ошибки | Причина | Способ обработки |
|---|---|---|
| Сетевые ошибки | Файл не найден, недоступен сервер | |
| Синтаксические ошибки XML | Неправильные теги, отсутствующие закрывающие теги | После parseFromString проверять наличие parsererror в документе |
| Ошибки доступа к элементам | Обращение к несуществующим тегам или атрибутам | Перед доступом проверять длину коллекции, использовать условные проверки для атрибутов |
Рекомендации:
- Оборачивать разбор XML в try-catch при работе с внешними данными.
- Логировать ошибки и сохранять исходный текст XML для анализа.
- Использовать функции-валидаторы для проверки структуры XML перед основной обработкой.
Сохранение и использование извлечённых данных в JavaScript
После извлечения данных из XML их можно сохранять в структуры JavaScript для дальнейшей обработки. Наиболее распространённые форматы хранения – объекты и массивы.
Пример преобразования XML в массив объектов:
let itemsArray = Array.from(xmlDoc.getElementsByTagName(«item»)).map(el => ({
id: el.getAttribute(«id»),
name: el.textContent
}));
Использование данных:
Вопрос-ответ:
Какие методы JavaScript подходят для парсинга XML?
Для работы с XML чаще всего используют DOMParser, который преобразует строку XML в DOM-объект, и методы загрузки данных с сервера: fetch и XMLHttpRequest. DOMParser удобен для разбора локальных строк XML, а fetch и XMLHttpRequest позволяют получать XML-файлы с внешних ресурсов.
Как проверить, что XML был распарсен корректно?
После использования DOMParser нужно проверить наличие ошибок с помощью поиска тегов parsererror. Если такие теги присутствуют, значит структура XML нарушена. Также полезно проверять наличие ожидаемых корневых элементов и атрибутов перед дальнейшей обработкой.
Чем отличается getElementsByTagName от querySelector при работе с XML?
getElementsByTagName возвращает все элементы с указанным тегом внутри XML, позволяя обходить их циклом. querySelector и querySelectorAll используют CSS-селекторы, что позволяет искать элементы по тегам, классам, атрибутам или их комбинациям. querySelector удобен для сложных выборок, getElementsByTagName — для прямого поиска по тегу.
Как извлечь атрибуты и текст элементов из XML?
После получения DOM-объекта можно использовать element.getAttribute(«имя_атрибута») для доступа к атрибутам и element.textContent для получения текста элемента. Если необходимо работать с несколькими элементами, их можно перебрать с помощью цикла или методов массивов после преобразования коллекции NodeList с помощью Array.from().
Какие ошибки чаще всего возникают при парсинге XML и как их обработать?
Основные ошибки: сетевые ошибки при загрузке XML, синтаксические ошибки в структуре файла и обращения к отсутствующим элементам. Для сетевых ошибок проверяют response.ok в fetch или status в XMLHttpRequest. Синтаксические ошибки выявляют через parsererror. Ошибки доступа к элементам предотвращают проверкой наличия элементов и атрибутов перед обращением к ним.
Как загрузить XML-файл с сервера и преобразовать его в объекты JavaScript для дальнейшей обработки?
Для загрузки XML с сервера можно использовать fetch или XMLHttpRequest. С помощью fetch выполняют запрос к файлу, затем вызывают response.text() для получения текста документа. После этого строку XML передают в DOMParser, который создаёт DOM-объект. Для извлечения данных из элементов используют методы getElementsByTagName или querySelectorAll. Полученные значения атрибутов и текст можно сохранять в объекты или массивы JavaScript, чтобы применять фильтрацию, сортировку или передавать данные другим функциям приложения.