Содержание статьи

В рабочих таблицах Excel часто встречаются ячейки, содержащие составные строки: артикул и название товара, ФИО в одной записи, дату вместе с временем, комментарии с разделителями. Для дальнейших расчетов, сортировки или загрузки данных в другие системы требуется получить не всю строку, а строго определённый фрагмент. Задача сводится к точному управлению символами и позициями внутри текста.
Excel предоставляет набор функций, позволяющих извлекать данные по количеству знаков, по их расположению или по заданному символу. Комбинации ЛЕВСИМВ, ПРАВСИМВ, ПСТР, НАЙТИ и ПОИСК дают возможность работать как с фиксированной, так и с изменяющейся структурой строк. Правильный выбор формулы напрямую влияет на корректность результата при обновлении данных.
Особое внимание требуется при работе с разделителями, пробелами и неоднородными значениями, когда длина текста заранее неизвестна. В таких случаях используются вложенные формулы и расчёт позиции символов, что позволяет извлекать фамилии, коды, номера документов или доменные имена без ручной правки. Грамотная настройка формул снижает риск ошибок при масштабировании таблиц и упрощает поддержку файлов.
В статье рассматриваются прикладные способы извлечения частей текста из одной ячейки, ориентированные на реальные сценарии: подготовку отчетов, очистку импортированных данных и автоматизацию рутинных операций. Каждый метод опирается на стандартные функции Excel и может быть применён без использования макросов.
Получение заданного количества символов слева с помощью функции ЛЕВСИМВ
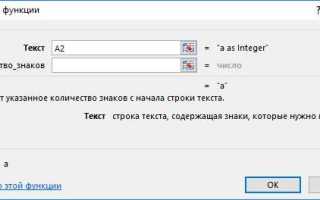
Функция ЛЕВСИМВ применяется, когда требуется извлечь строго определённое число символов, начиная с первого знака в ячейке. Синтаксис формулы имеет вид ЛЕВСИМВ(текст; количество_знаков), где второй аргумент задаёт точную длину возвращаемого фрагмента. Например, формула =ЛЕВСИМВ(A2;5) вернёт первые пять символов из значения ячейки A2 независимо от общей длины строки.
Чаще всего ЛЕВСИМВ используют для отделения кодов, префиксов и фиксированных идентификаторов, расположенных в начале строки. В товарных номенклатурах это могут быть первые 3–4 символа артикула, в банковских выгрузках – начальная часть номера счёта, в логах – дата без времени. При стабильной структуре данных функция работает предсказуемо и не требует дополнительных проверок.
Для динамического управления количеством извлекаемых символов второй аргумент можно задавать формулой. Например, сочетание ЛЕВСИМВ с функцией НАЙТИ позволяет получать текст до первого пробела или другого разделителя: =ЛЕВСИМВ(A2;НАЙТИ(» «;A2)-1). Такой подход полезен при обработке строк с переменной длиной, где фиксированное число символов заранее неизвестно.
Важно учитывать, что ЛЕВСИМВ корректно работает с любыми текстовыми данными, но при использовании с числами Excel сначала преобразует их в текстовый формат. Это может приводить к потере ведущих нулей, если исходное значение не было сохранено как текст. Для сохранения структуры данных рекомендуется заранее проверять формат ячеек или использовать явное преобразование через ТЕКСТ.
Извлечение символов справа из текста функцией ПРАВСИМВ
Функция ПРАВСИМВ используется для получения фрагмента строки, расположенного в конце ячейки. Формула имеет вид ПРАВСИМВ(текст; количество_знаков) и возвращает указанное число символов, начиная с последнего. Пример =ПРАВСИМВ(A2;4) извлекает четыре крайних символа независимо от длины исходного значения.
На практике ПРАВСИМВ применяют для выделения расширений файлов, последних цифр номера документа, суффиксов кодов и доменных зон. При обработке email-адресов формула =ПРАВСИМВ(A2;3) позволяет получить «ru» или «com», если структура данных единообразна. Такой подход подходит для источников с заранее известным форматом.
При переменной длине текста количество извлекаемых символов рассчитывают динамически. Частый сценарий – получение части строки после последнего разделителя. В этом случае используется связка с функцией ДЛСТР: =ПРАВСИМВ(A2;ДЛСТР(A2)-НАЙТИ(«-«;A2)). Формула возвращает всё, что находится справа от дефиса, даже если общая длина строки меняется.
| Исходное значение | Формула | Результат |
|---|---|---|
| DOC-4587 | =ПРАВСИМВ(A2;4) | 4587 |
| report.xlsx | =ПРАВСИМВ(A3;4) | xlsx |
| user@mail.ru | =ПРАВСИМВ(A4;2) | ru |
Функция корректно работает с текстовыми и числовыми значениями, однако при использовании с числами Excel автоматически преобразует их в текст. Это важно учитывать при обработке идентификаторов с фиксированным количеством знаков, чтобы не потерять структуру данных при последующих вычислениях.
Выбор фрагмента текста из середины строки через функцию ПСТР
Функция ПСТР предназначена для извлечения части текста, находящейся между началом и концом строки. Формула записывается как ПСТР(текст; начальная_позиция; количество_знаков), где начальная позиция отсчитывается с первого символа и всегда задаётся числом больше нуля. Пример =ПСТР(A2;4;6) возвращает шесть символов, начиная с четвёртого знака в ячейке.
ПСТР применяется при работе с составными значениями, в которых нужный фрагмент расположен строго в определённом месте. Это характерно для серийных номеров, кодов продукции, ИНН в составе длинной строки или дат, встроенных в текст. Если формат данных стабилен, достаточно один раз задать позиции, после чего формула корректно отрабатывает на всём диапазоне.
Для строк с переменным содержимым начальную позицию часто рассчитывают автоматически. Связка ПСТР и НАЙТИ позволяет извлекать данные между двумя символами. Например, формула =ПСТР(A2;НАЙТИ(«(» ;A2)+1;НАЙТИ(«)»;A2)-НАЙТИ(«(» ;A2)-1) возвращает текст, заключённый в круглые скобки, независимо от длины остальной строки.
При работе с ПСТР важно учитывать наличие лишних пробелов и скрытых символов, особенно в данных, импортированных из внешних источников. Перед извлечением фрагмента рекомендуется очистить строку функцией СЖПРОБЕЛЫ или удалить непечатаемые знаки, чтобы смещение позиций не приводило к искажённому результату.
Поиск позиции символа или слова для последующего извлечения фрагмента
Для извлечения части строки с переменной длиной сначала требуется определить позицию ключевого символа или слова. В Excel для этой задачи применяются функции НАЙТИ и ПОИСК, которые возвращают номер символа в тексте. Полученное значение используется как аргумент в функциях ЛЕВСИМВ, ПРАВСИМВ или ПСТР.
Функция НАЙТИ чувствительна к регистру и подходит для точных совпадений, например при поиске служебных маркеров или кодов. ПОИСК регистр игнорирует, что удобно при обработке пользовательского ввода. Обе функции возвращают позицию первого вхождения искомого фрагмента.
- Получение текста до разделителя: =ЛЕВСИМВ(A2;НАЙТИ(«:»;A2)-1)
- Извлечение данных после символа: =ПСТР(A2;НАЙТИ(«-«;A2)+1;ДЛСТР(A2))
- Определение позиции слова внутри строки для дальнейшего анализа
При наличии нескольких одинаковых символов в строке важно учитывать, что НАЙТИ и ПОИСК работают только с первым совпадением. Для доступа к последнему разделителю используется вложенный расчёт длины строки или замена символов. Это особенно актуально при разборе путей к файлам, URL и составных идентификаторов.
- Определить уникальный символ или слово, относительно которого строится логика извлечения
- Получить позицию с помощью НАЙТИ или ПОИСК
- Передать результат в ЛЕВСИМВ, ПРАВСИМВ или ПСТР
Перед поиском рекомендуется привести данные к единому виду: удалить лишние пробелы, проверить кодировку и формат ячеек. Это снижает риск смещения позиций и некорректного извлечения текста при копировании формул на большие диапазоны.
Извлечение текста до или после разделителя с использованием НАЙТИ и ПСТР
Комбинация функций НАЙТИ и ПСТР позволяет извлекать части строки относительно заданного разделителя, позиция которого заранее неизвестна. НАЙТИ возвращает номер первого вхождения символа или последовательности символов, а ПСТР использует это значение для выбора нужного фрагмента. Такой подход применяется при разборе строк с переменной длиной и нестабильной структурой.
Для получения текста до разделителя используется формула вида =ПСТР(A2;1;НАЙТИ(«/»;A2)-1). Она извлекает все символы слева от первого слэша, что удобно при обработке дат, путей к каталогам и составных кодов. При отсутствии разделителя формула вернёт ошибку, поэтому в рабочих файлах часто добавляют проверку через ЕСЛИОШИБКА.
Извлечение текста после разделителя строится на смещении начальной позиции. Пример =ПСТР(A2;НАЙТИ(«@»;A2)+1;ДЛСТР(A2)) возвращает доменную часть email-адреса независимо от длины имени пользователя. Количество извлекаемых символов задаётся с запасом через ДЛСТР, так как ПСТР автоматически ограничивает результат длиной строки.
При работе с несколькими одинаковыми разделителями важно учитывать, что НАЙТИ ориентируется на первое совпадение. Для получения данных после последнего символа применяют вложенные формулы или предварительную замену разделителей. Точный выбор разделителя и корректный расчёт позиции позволяют избежать смещения данных при копировании формул на весь столбец.
Работа с переменной длиной текста при извлечении данных из ячеек

При переменной длине строк фиксированное количество символов теряет практическую ценность, поэтому извлечение строится на расчёте позиций и общей длины текста. Ключевую роль играют функции ДЛСТР, НАЙТИ, ПОИСК и ПСТР, позволяющие адаптировать формулы под изменяющееся содержимое ячеек.
Распространённый приём – вычисление количества символов для извлечения на основе длины строки. Пример =ПРАВСИМВ(A2;ДЛСТР(A2)-НАЙТИ(«_»;A2)) возвращает всё, что находится после символа подчёркивания, независимо от того, сколько знаков находится слева. Такой подход подходит для кодов, сформированных по шаблону, но с разным наполнением.
- Использование ДЛСТР для определения границы извлечения
- Поиск опорного символа или слова через НАЙТИ или ПОИСК
- Извлечение нужного фрагмента функцией ПСТР
При наличии нескольких разделителей в строке логика усложняется. Для работы с последним вхождением символа применяют замену всех разделителей на уникальный маркер или используют вложенные вычисления длины. Это актуально для URL, путей к файлам и составных идентификаторов с несколькими уровнями.
- Очистить исходные данные от лишних пробелов и непечатаемых символов
- Определить устойчивый ориентир внутри строки
- Построить формулу с учётом возможного отсутствия разделителя
При копировании формул на большие диапазоны рекомендуется сразу учитывать ошибки поиска и оборачивать расчёты в проверку. Это позволяет сохранить корректность извлечённых данных даже при появлении строк с нестандартной структурой.
Использование формул для извлечения текста из ячеек с разным форматом данных
В Excel извлечение текста осложняется, когда в одном столбце встречаются строки, числа, даты и значения с пользовательским форматом. Текстовые функции работают корректно только после приведения данных к строковому виду, поэтому первым шагом часто становится явное преобразование через ТЕКСТ или добавление пустой строки в формуле.
При работе с датами и временем важно учитывать, что Excel хранит их как числовые значения. Формула =ЛЕВСИМВ(ТЕКСТ(A2;»ДД.ММ.ГГГГ»);2) позволяет получить день месяца независимо от региональных настроек и формата отображения. Без преобразования результат будет непредсказуемым и зависимым от текущего формата ячейки.
Числовые идентификаторы с ведущими нулями требуют особого подхода. Если значение хранится как число, нули в начале не сохраняются, и функции ПРАВСИМВ или ПСТР вернут искажённый результат. В таких случаях данные следует хранить как текст или использовать форматирование через ТЕКСТ с заданной маской.
В ячейках со смешанным содержимым рекомендуется заранее проверять тип данных. Комбинация ЕСТЬТЕКСТ и ЕСТЬЧИСЛО позволяет применять разные формулы в зависимости от формата, сохраняя стабильность расчётов при обработке больших массивов данных.
При импорте данных из внешних источников полезно выполнять предварительную нормализацию форматов. Это упрощает дальнейшее извлечение фрагментов текста и снижает риск ошибок при копировании формул на весь диапазон.
Вопрос-ответ:
Почему формула ЛЕВСИМВ возвращает неправильный результат при работе с числами?
ЛЕВСИМВ работает с текстом, а числовые значения Excel хранит без форматирования. Если в числе есть ведущие нули или задан пользовательский формат, функция сначала преобразует значение во внутренний числовой вид и только потом извлекает символы. Для корректного результата число нужно предварительно преобразовать в текст с помощью функции ТЕКСТ или хранить данные в текстовом формате.
Как извлечь часть строки, если длина текста в каждой ячейке разная?
При разной длине строки используется расчёт позиций через функции НАЙТИ или ПОИСК вместе с ДЛСТР. Например, можно определить позицию разделителя и извлечь данные до или после него с помощью ПСТР. Такой подход работает независимо от того, сколько символов содержит исходная ячейка.
Чем отличается НАЙТИ от ПОИСК и какую функцию выбрать?
НАЙТИ учитывает регистр символов и подходит для ситуаций, где важна точная запись текста. ПОИСК регистр игнорирует и удобен при обработке пользовательских данных. Обе функции возвращают позицию первого совпадения, что нужно учитывать при наличии повторяющихся символов.
Как получить текст после последнего разделителя, если в строке их несколько?
Для этой задачи используют связку ПРАВСИМВ и ДЛСТР с вычислением позиции последнего разделителя. Один из подходов — заменить все разделители на уникальный символ и найти его позицию, либо вычислить длину строки и вычесть позицию последнего совпадения. Такой метод применяется при работе с путями к файлам и URL.
Почему формула ПСТР возвращает ошибку #ЗНАЧ! и как этого избежать?
Ошибка возникает, если функция НАЙТИ не обнаружила указанный символ и вернула ошибку вместо позиции. Чтобы формула не прерывала расчёты, её оборачивают в ЕСЛИОШИБКА или предварительно проверяют наличие символа. Это позволяет корректно обрабатывать строки с отличающейся структурой.
Как извлечь фамилию из ячейки, если ФИО записано в одной строке через пробелы?
Если фамилия стоит первой, можно использовать формулу =ЛЕВСИМВ(A2;НАЙТИ(» «;A2)-1), которая вернёт текст до первого пробела. При наличии двойных пробелов или лишних символов строку стоит предварительно обработать функцией СЖПРОБЕЛЫ, чтобы позиция пробела определялась корректно.
Можно ли извлечь часть текста без формул, если данные постоянно обновляются?
Да, для этого подходит инструмент «Текст по столбцам». Он позволяет разделить содержимое ячейки по указанному разделителю или по фиксированной ширине. Однако результат не обновляется автоматически при изменении исходных данных, поэтому при регулярных обновлениях удобнее использовать формулы.