Веб-страницы часто содержат десятки или сотни изображений, которые могут понадобиться для анализа, архивации или повторного использования. Ручное сохранение каждого файла – неэффективный подход, особенно если речь идет о галереях, каталогах или динамических ресурсах. Существует несколько проверенных способов автоматизировать этот процесс, каждый из которых подходит для разных сценариев.
Самый быстрый вариант – использование встроенных инструментов браузера. В Chrome и Firefox откройте Инструменты разработчика (F12 или Ctrl+Shift+I), перейдите на вкладку Network и отфильтруйте запросы по типу img. Обновите страницу, выделите все найденные изображения, щелкните правой кнопкой мыши и выберите Save all as HAR или Open in new tab для массового сохранения. Этот метод работает с любыми статическими изображениями, но не захватывает контент, загружаемый через JavaScript.
Для более сложных случаев подойдут специализированные расширения. Image Downloader (Chrome) и Download All Images (Firefox) позволяют скачивать файлы по заданным критериям: размеру, формату (JPG, PNG, WebP) или домену. Установите расширение, откройте страницу, запустите сканирование и выберите нужные файлы из списка. Преимущество – возможность исключить рекламные баннеры и фоновые картинки, оставив только целевой контент.
Если требуется скачать изображения с защищенных страниц или динамических сайтов (например, социальных сетей), используйте Python-скрипты с библиотекой BeautifulSoup или Scrapy. Пример кода для извлечения всех src атрибутов тегов <img>:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for img in soup.find_all('img'):
img_url = img.get('src')
if img_url:
with open(img_url.split('/')[-1], 'wb') as f:
f.write(requests.get(img_url).content)
Для пользователей командной строки подойдет утилита wget. Команда wget -r -l 1 -nd -H -A jpg,jpeg,png,gif -e robots=off https://example.com рекурсивно загрузит все изображения с указанного URL, игнорируя ограничения robots.txt. Ключ -A позволяет фильтровать файлы по расширению, а -nd – сохранять их в одну папку без создания структуры каталогов.
Как сохранить изображения через встроенные инструменты браузера
В Chrome, Edge и Firefox откройте веб-страницу, щелкните правой кнопкой мыши на нужном изображении и выберите «Сохранить изображение как». В Safari используйте контекстное меню с опцией «Сохранить изображение на диск». Для массового сохранения в Firefox установите расширение *Save Images* из официального магазина дополнений – оно добавляет пункт «Сохранить все изображения» в контекстное меню страницы. В Chrome и Edge аналогичную функцию предоставляет расширение *Image Downloader*, доступное через Chrome Web Store.
В Opera и браузерах на базе Chromium (например, Yandex Browser) откройте инструменты разработчика клавишей F12 или через меню «Дополнительные инструменты». Перейдите на вкладку *Elements*, найдите теги `` в коде страницы, щелкните правой кнопкой на ссылке в атрибуте `src` и выберите «Open in new tab». В новой вкладке сохраните файл стандартным способом. Для ускорения процесса используйте поиск по DOM-дереву с фильтром `img[src$=».jpg»], img[src$=».png»], img[src$=».webp»]`.
В мобильных браузерах (Chrome для Android, Safari для iOS) долгое нажатие на изображение вызывает контекстное меню с опцией «Скачать изображение» или «Сохранить». В Firefox для Android включите режим «Запрос рабочего стола», чтобы получить доступ к полной версии страницы и сохранить изображения через контекстное меню. На iOS в Safari используйте жест «Скопировать» для изображения, затем вставьте ссылку в приложение *Файлы* или *Заметки* для загрузки.
Использование расширений для Chrome и Firefox для массовой загрузки

Расширения для браузеров – самый быстрый способ скачать все изображения с веб-страницы без программирования. В Chrome Web Store и Firefox Add-ons доступны инструменты с разным функционалом: от базового парсинга до фильтрации по разрешению, формату и даже исключения фоновых картинок. Популярные решения:
- Image Downloader (Chrome, Firefox) – анализирует DOM, выгружает изображения в оригинальном качестве, поддерживает массовую загрузку через ZIP-архив. Позволяет исключать дубликаты по хэшу и настраивать минимальный размер файла.
- Fatkun Batch Download Image (Chrome) – интегрируется с контекстным меню, сортирует результаты по доменам, сохраняет метаданные (EXIF). Работает с ленивой загрузкой (lazy load) и динамическим контентом.
- Download All Images (Firefox) – фильтрует изображения по атрибутам
src,srcsetиdata-src, поддерживает прокси для обхода блокировок. Есть встроенный предпросмотр перед скачиванием.
При выборе расширения учитывайте ограничения: большинство инструментов не парсят изображения, загруженные через JavaScript (например, в слайдерах), а некоторые блокируют загрузку с защищённых страниц (HTTPS с CORS). Для сложных случаев используйте PageArchiver (Chrome) – он сохраняет полную копию страницы, включая ресурсы, или SingleFile (Firefox), который упаковывает HTML и медиафайлы в один файл. Перед установкой проверяйте отзывы: актуальные версии часто исправляют баги с кодировкой имён файлов и конфликтами с другими расширениями.
Скачивание картинок с помощью консольных команд в браузере
Откройте инструменты разработчика в браузере (F12 или Ctrl+Shift+I) и перейдите на вкладку «Console». В Chrome и Firefox поддерживается метод document.querySelectorAll('img'), который возвращает коллекцию всех изображений на странице. Для сохранения URL-адресов картинок в массив выполните:
let images = Array.from(document.querySelectorAll('img')).map(img => img.src);
Этот код извлекает атрибуты src всех тегов <img>, включая динамически загруженные изображения. Если требуется фильтрация по домену или формату, добавьте условие:
images = images.filter(url => url.includes('.jpg') || url.includes('.png'));
Для скачивания изображений используйте команду fetch() с последующим сохранением через Blob. Пример для одной картинки:
fetch(images[0])
.then(response => response.blob())
.then(blob => {
let a = document.createElement('a');
a.href = URL.createObjectURL(blob);
a.download = 'image.jpg';
a.click();
});
Чтобы скачать все изображения разом, оберните код в цикл. Учтите ограничения браузера на одновременные запросы – Chrome блокирует более 6 параллельных загрузок с одного домена. Решение: добавить задержку между запросами с помощью setTimeout:
images.forEach((url, i) => {
setTimeout(() => {
fetch(url).then(...); // Код из предыдущего примера
}, i * 500);
});
| Команда | Назначение | Примечания |
|---|---|---|
document.images |
Получает коллекцию всех <img> на странице |
Не учитывает фоновые изображения CSS |
Array.from() |
Преобразует коллекцию в массив для работы с методами map/filter |
Альтернатива: [...document.images] |
URL.createObjectURL() |
Создает временный URL для Blob-объекта | Освобождайте ресурсы с URL.revokeObjectURL() |
Для страниц с ленивой загрузкой изображений (loading="lazy") предварительно прокрутите страницу до конца или используйте скрипт для принудительной загрузки:
window.scrollTo(0, document.body.scrollHeight);
setTimeout(() => {
// Код для извлечения изображений
}, 2000);
Если изображения загружаются через JavaScript (например, React или Vue), дождитесь завершения рендеринга компонентов. В Chrome DevTools доступна опция «Pause on exceptions» для отладки динамического контента.
Автоматизация загрузки через Python и библиотеку BeautifulSoup
Для парсинга изображений с веб-страницы установите библиотеки requests и beautifulsoup4 через pip: pip install requests beautifulsoup4. Импортируйте их в скрипт вместе с os для работы с файлами. Пример кода для извлечения всех тегов <img> с атрибутом src:
soup = BeautifulSoup(response.text, 'html.parser')
images = soup.find_all('img', src=True)
for img in images:
url = img['src']
if not url.startswith(('http:', 'https:')):
url = f"{base_url}{url}" if url.startswith('/') else f"{base_url}/{url}"
response = requests.get(url, stream=True)
if response.status_code == 200:
with open(f"images/{os.path.basename(url)}", 'wb') as f:
f.write(response.content)
Обрабатывайте относительные пути (/path/to/image.jpg) и динамические URL (например, с CDN) – используйте urljoin() из модуля urllib.parse для корректной сборки полного адреса. Для фильтрации изображений по размеру или формату добавьте проверку заголовков Content-Type или атрибутов width/height в теге. Сохраняйте файлы в отдельную директорию, предварительно создав её с помощью os.makedirs('images', exist_ok=True). Для обхода ограничений сервера используйте заголовки User-Agent и задержки между запросами (time.sleep(1)).
Работа с инструментами командной строки: wget и curl

wget и curl – утилиты для загрузки контента через командную строку, но их подходы к скачиванию изображений отличаются. wget оптимизирован для рекурсивного парсинга страниц, а curl – для точечных HTTP-запросов. Выбор зависит от задачи: если нужно скачать все изображения с одной страницы, wget справится быстрее, а curl подойдет для сложных сценариев с авторизацией или динамическим контентом.
Для скачивания всех изображений с веб-страницы через wget используйте команду:
wget -r -l 1 -nd -H -A jpg,jpeg,png,gif,webp -e robots=off https://example.com
Ключи расшифровываются так:
-r– рекурсивный режим;-l 1– глубина рекурсии (только текущая страница);-nd– не создавать директории;-H– следовать по ссылкам на другие домены;-A– фильтр по расширениям файлов;-e robots=off– игнорироватьrobots.txt.
curl требует предварительного парсинга HTML для извлечения ссылок на изображения. Пример скрипта на Bash:
- Сохраните HTML-страницу:
curl -o page.html https://example.com. - Извлеките ссылки на изображения с помощью
grepиsed:
grep -Eo 'src="[^"]+\.(jpg|jpeg|png|gif|webp)"' page.html | sed -E 's/src="([^"]+)"/\1/' > images.txt. - Скачайте файлы по списку:
xargs -n 1 curl -O < images.txt.
Для динамических страниц с JavaScript используйте curl с заголовками браузера: curl -A "Mozilla/5.0" -H "Accept: text/html" https://example.com.
Оба инструмента поддерживают прокси и авторизацию. Для wget добавьте параметры:
--proxy-user=USER --proxy-password=PASS;--user=USER --password=PASSдля базовой аутентификации.
В curl это выглядит так:
-x http://proxy:port -U USER:PASS;-u USER:PASSдля авторизации на сайте.
Ограничения скорости и параллельные загрузки ускорят процесс. В wget используйте --limit-rate=1M для ограничения скорости до 1 МБ/с. Для параллельных загрузок в curl подойдет xargs -P 4 (4 параллельных потока). Пример:
cat images.txt | xargs -n 1 -P 4 curl -O.
Сохранение изображений через онлайн-сервисы без установки программ
Онлайн-сервисы для скачивания изображений с веб-страниц работают через браузер и не требуют установки дополнительного ПО. Они подходят для разовых задач, когда нужно быстро сохранить несколько файлов без настройки скриптов или расширений. Большинство таких инструментов поддерживают форматы JPEG, PNG, GIF, WebP и иногда SVG, но редко обрабатывают динамически загружаемые контент (например, через AJAX).
Основные преимущества онлайн-сервисов:
- Доступность с любого устройства – достаточно браузера и интернет-соединения.
- Отсутствие необходимости разбираться в коде страницы или API.
- Возможность скачивания изображений по URL без открытия исходной страницы.
- Некоторые сервисы предлагают базовую обработку: изменение размера, конвертацию форматов.
Популярные сервисы с проверенной репутацией:
- Image Downloader Online (imagedownloader.com) – анализирует HTML-код страницы и извлекает прямые ссылки на изображения. Поддерживает массовое скачивание, но ограничивает количество файлов за один запрос (обычно до 50).
- Download All Images (download-all-images.apponic.com) – работает через вставку URL страницы. Позволяет фильтровать изображения по размеру (например, исключать миниатюры). Есть опция загрузки в ZIP-архиве.
- Extract.pics (extract.pics) – специализируется на извлечении изображений из CSS-фонов и спрайтов. Подходит для страниц с динамическим контентом, но требует ручной проверки результатов.
Ограничения и риски:
- Большинство сервисов не сохраняют оригинальные имена файлов – изображения скачиваются с автоматически сгенерированными названиями (например,
image1.jpg). - Некоторые инструменты добавляют водяные знаки или ограничивают разрешение скачиваемых файлов в бесплатной версии.
- При работе с конфиденциальными данными (например, личными фото) есть риск утечки информации – сервисы могут хранить загруженные URL в логах.
- Страницы с защитой от парсинга (например, Cloudflare) часто блокируют запросы онлайн-сервисов.
Как выбрать подходящий сервис:
- Для страниц с небольшим количеством изображений (<100) подойдут любые инструменты из списка выше.
- Если нужны оригинальные имена файлов, ищите сервисы с поддержкой атрибута
altилиtitle(например, img2go.com). - Для массового скачивания (>500 файлов) используйте сервисы с API или локальные скрипты – онлайн-инструменты в таких случаях работают нестабильно.
- Проверяйте отзывы на независимых платформах (например, Reddit) – многие сервисы появляются и исчезают, не обеспечивая долгосрочной поддержки.
Алгоритм работы с онлайн-сервисом на примере Image Downloader Online:
- Откройте целевую веб-страницу в браузере и скопируйте её URL из адресной строки.
- Перейдите на imagedownloader.com и вставьте ссылку в поле ввода.
- Нажмите кнопку Download Images – сервис начнёт анализ страницы (может занять от 5 до 30 секунд в зависимости от объёма контента).
- После завершения анализа появится список найденных изображений с превью. Отметьте нужные файлы или выберите опцию Select All.
- Нажмите Download Selected – изображения скачаются в ZIP-архиве или по отдельности (зависит от настроек сервиса).
- Если сервис предлагает фильтры (например, по размеру), примените их перед скачиванием, чтобы исключить ненужные файлы.
Альтернативы для сложных случаев:
- Если онлайн-сервис не находит изображения, попробуйте открыть исходный код страницы (Ctrl+U в Chrome) и вручную найти ссылки на файлы по тегу
<img>или CSS-свойствуbackground-image. Затем используйте сервис для скачивания по прямым URL. - Для страниц с ленивой загрузкой (lazy load) прокрутите страницу до конца перед копированием URL – иначе часть изображений не загрузится в DOM и не будет обнаружена.
- Если сервис блокирует запросы, измените User-Agent в браузере (например, через расширение User-Agent Switcher) или используйте VPN.
Извлечение картинок из исходного кода страницы вручную
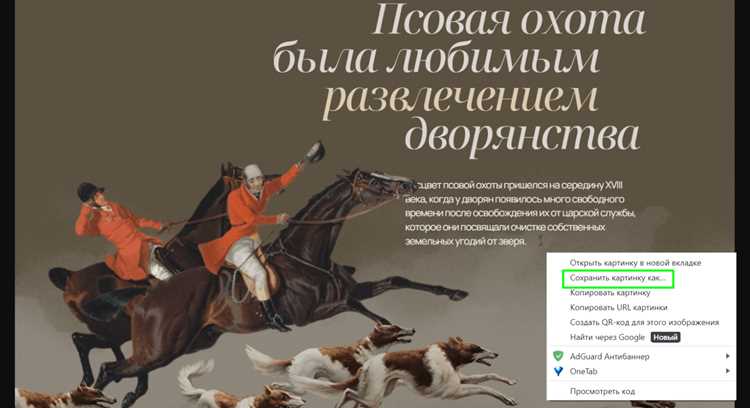
Используйте инструменты разработчика (F12 или Cmd+Option+I) для анализа динамически загружаемых изображений: перейдите на вкладку Network, выберите фильтр Img и обновите страницу. Найдите нужные файлы в списке, щёлкните правой кнопкой мыши по строке и выберите Open in new tab для скачивания. Обратите внимание на заголовки запросов – если сервер требует User-Agent или Referer, добавьте их вручную через расширения вроде ModHeader или утилиты curl/wget.