Содержание статьи

Копирование страницы сайта – задача, которая возникает при резервном копировании, миграции контента или анализе конкурентов. Полное дублирование требует не только сохранения HTML-кода, но и всех зависимых ресурсов: CSS, JavaScript, изображений, шрифтов и API-запросов. Без этого страница потеряет функциональность или визуальную целостность. Рассмотрим методы, которые позволяют сохранить страницу в исходном виде.
Ручной подход подразумевает использование встроенных средств браузера. В Chrome или Firefox можно сохранить страницу через Ctrl+S (или Cmd+S на macOS) с выбором формата «Веб-страница, полностью». Этот метод сохраняет HTML-файл и папку с ресурсами, но не гарантирует корректную работу динамического контента. Например, формы, загружаемые через AJAX, останутся нерабочими, а относительные пути к ресурсам могут сломаться при переносе на другой домен.
Для автоматизации процесса используют специализированные инструменты. HTTrack – кроссплатформенная утилита, которая скачивает сайт целиком, включая вложенные страницы. Она поддерживает фильтры по расширениям файлов, глубину сканирования и игнорирование определённых URL. Пример команды для копирования сайта с глубиной 3 уровня: httrack https://example.com -O ./backup -r3. Однако HTTrack не справляется с JavaScript-рендерингом, поэтому динамически загружаемый контент останется недоступным.
Для работы с современными SPA-приложениями (React, Angular, Vue) подойдут инструменты на базе Puppeteer или Playwright. Эти библиотеки запускают браузер в фоне и сохраняют страницу после полной загрузки всех скриптов. Пример скрипта на Puppeteer для сохранения страницы в PDF и HTML:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com', { waitUntil: 'networkidle0' });
await page.pdf({ path: 'page.pdf', format: 'A4' });
await page.content().then(html => require('fs').writeFileSync('page.html', html));
await browser.close();
})();
Важный нюанс – легальность копирования. Перед скачиванием проверьте robots.txt сайта (например, https://example.com/robots.txt) и условия использования. Некоторые ресурсы запрещают автоматическое копирование через директиву Disallow: /. В таких случаях требуется письменное разрешение владельца или использование публичных API, если они доступны.
Как сохранить HTML-код страницы через браузер вручную
Откройте страницу в браузере и нажмите Ctrl + U (Windows/Linux) или Cmd + Option + U (macOS). Откроется вкладка с исходным HTML-кодом. Выделите весь текст комбинацией Ctrl + A (или Cmd + A) и скопируйте его через Ctrl + C (Cmd + C). Вставьте содержимое в текстовый редактор (например, Notepad++, Sublime Text или VS Code) и сохраните с расширением .html. Этот метод захватывает только статический HTML без динамически подгружаемых данных.
Для сохранения страницы с ресурсами (CSS, JS, изображениями) используйте встроенные инструменты браузера:
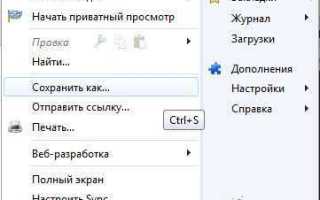
- Chrome/Edge:
Ctrl + S→ выберите формат «Веб-страница, полностью» (сохраняет HTML + папку с ресурсами). - Firefox:
Ctrl + S→ «Веб-страница, полная» (аналогично Chrome). - Safari: «Файл» → «Сохранить как» → «Веб-архив» (формат
.webarchive).
Учтите, что некоторые ресурсы (например, шрифты или API-запросы) могут не сохраниться корректно из-за CORS или динамической загрузки.
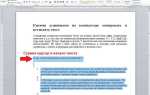
Если нужна только разметка без стилей и скриптов, используйте инструменты разработчика (F12 или Ctrl + Shift + I). Перейдите на вкладку «Elements», кликните правой кнопкой мыши на тег <html> и выберите «Copy» → «Copy outerHTML». Вставьте код в файл – это даст чистую структуру без внешних зависимостей.
Для автоматизации процесса в Chrome/Edge установите расширение SingleFile. Оно сохраняет страницу в один HTML-файл с встроенными CSS/JS и изображениями (base64). Нажмите на иконку расширения – страница сохранится локально с минимальными потерями данных.
Использование команд wget для скачивания сайта с зависимостями
Команда `wget` с флагом `—mirror` (`-m`) создаёт полную копию сайта, включая HTML, CSS, JavaScript и медиафайлы. Для корректного сохранения зависимостей добавьте параметры: `—convert-links` (преобразует ссылки для локального просмотра), `—adjust-extension` (исправляет расширения файлов, например, `.html` для динамических страниц), `—page-requisites` (`-p`) (скачивает стили, скрипты и изображения). Пример базовой команды: `wget -mpEk —user-agent=»Mozilla» https://example.com`. Флаг `—user-agent` маскирует запрос под браузер, чтобы обойти ограничения сервера.
Для скачивания сайтов с динамическим контентом (например, загружаемым через AJAX) используйте `—span-hosts` и `—domains=example.com,cdn.example.com`, чтобы включить внешние ресурсы с указанных доменов. Если сайт требует аутентификации, добавьте `—http-user=логин —http-password=пароль`. Для ограничения глубины рекурсии применяйте `-l 5` (по умолчанию – 5 уровней). При проблемах с кодировкой добавьте `—restrict-file-names=windows` для совместимости с файловыми системами Windows. Избегайте флага `—no-clobber` при повторных загрузках – он пропускает уже скачанные файлы, что может нарушить целостность копии.
Настройка зеркалирования сайта с помощью HTTrack
HTTrack – кроссплатформенный инструмент для создания локальных копий сайтов, поддерживающий HTTP/HTTPS, FTP и прокси-серверы. Утилита работает через командную строку или графический интерфейс (WinHTTrack для Windows), сохраняя структуру каталогов, CSS, JavaScript и медиафайлы. Для базовой настройки достаточно указать URL сайта и целевую директорию, но продвинутые параметры позволяют фильтровать контент, ограничивать глубину сканирования и управлять задержками между запросами.
Основные параметры командной строки для точной настройки зеркалирования:
| Параметр | Описание | Пример значения |
|---|---|---|
-rN |
Ограничение глубины сканирования (N – число уровней) | -r3 |
-%eN |
Задержка между запросами в миллисекундах (N – значение) | -%e2000 |
-A |
Максимальный размер загружаемых файлов в байтах | -A10000000 (10 МБ) |
-N |
Шаблон именования файлов (например, %h%p/%n%q.%t) |
-N "%h%p/%n%q.%t" |
--mirror |
Режим зеркалирования (сохраняет оригинальную структуру) | --mirror |
Для исключения динамического контента или нежелательных разделов используйте фильтры в файле filters.txt. Пример содержимого файла для игнорирования PHP-скриптов и PDF-документов: -*.php +*.html +*.css +*.js -*.pdf. При работе с крупными сайтами рекомендуется запускать HTTrack ночью, ограничивая нагрузку на сервер параметром -C2 (кеширование) и --disable-security-limits для обхода ограничений по умолчанию. После завершения проверьте целостность копии с помощью --check-type, чтобы выявить битые ссылки или отсутствующие ресурсы.
Автоматизация копирования через Python и библиотеку BeautifulSoup
Для копирования страницы сайта с помощью Python и BeautifulSoup установите библиотеки через pip: `pip install requests beautifulsoup4`. Базовый скрипт начинается с импорта модулей: `import requests` для загрузки HTML и `from bs4 import BeautifulSoup` для парсинга. Пример кода для сохранения страницы целиком: `response = requests.get(«https://example.com»)`, затем `soup = BeautifulSoup(response.text, ‘html.parser’)`. Сохраните результат в файл с помощью `with open(«page.html», «w», encoding=»utf-8″) as file: file.write(soup.prettify())`. Учтите, что статические страницы копируются корректно, но динамический контент (загружаемый через JavaScript) потребует дополнительных инструментов, например, Selenium.
Для копирования специфических элементов используйте методы BeautifulSoup: `soup.find_all(«div», class_=»content»)` выберет все блоки с классом `content`, а `soup.select(«a[href^=’https’]»)` – ссылки с HTTPS. Чтобы избежать блокировок, добавьте заголовки запроса: `headers = {«User-Agent»: «Mozilla/5.0»}` и передайте их в `requests.get(url, headers=headers)`. Для обработки относительных ссылок используйте `urljoin` из модуля `urllib.parse`: `from urllib.parse import urljoin` и преобразуйте ссылки перед сохранением. При работе с большими сайтами оптимизируйте скрипт, добавив задержки между запросами (`time.sleep(2)`) и обработку исключений (`try-except`).
Копирование динамического контента с помощью расширений браузера
Динамические страницы, загружающие данные через AJAX или JavaScript после первоначальной загрузки, не сохраняются полностью стандартными методами браузера. Расширения вроде Web Scraper (Chrome) или SingleFile решают эту проблему, фиксируя состояние страницы после выполнения всех скриптов. Web Scraper позволяет настроить сценарии для извлечения контента, появляющегося при прокрутке или кликах, например, ленты новостей или бесконечных галерей. Для работы с ним требуется создать селекторы для целевых элементов, что занимает 5–10 минут на страницу средней сложности.
SingleFile сохраняет страницу в один HTML-файл, включая стили и динамически подгруженный контент. Расширение обрабатывает даже сложные SPA (Single Page Applications), такие как React-приложения, но может некорректно работать с iframe или контентом, загружаемым по событию scroll. Версия SingleFileZ добавляет сжатие, уменьшая размер файла на 30–50%. Для активации полного захвата нужно включить опцию «Save dynamic content» в настройках.
PageArchiver (Firefox) специализируется на архивации страниц с динамическими элементами, включая видео и аудиоплееры. Расширение сохраняет контент в формате MHTML, совместимом с большинством браузеров. Оно эффективно для страниц с ленивой загрузкой изображений, но требует ручной настройки тайм-аута (по умолчанию 5 секунд) для ожидания завершения загрузки скриптов. На сайтах с медленным API рекомендуется увеличить значение до 15–20 секунд.
Для копирования таблиц или списков, обновляемых в реальном времени, подходит расширение Table Capture. Оно извлекает данные из DOM после выполнения всех асинхронных запросов и экспортирует их в CSV или Excel. Инструмент работает с таблицами, скрытыми под вкладками или фильтрами, но не сохраняет стили ячеек. Пример использования: копирование котировок с биржевых сайтов, где данные подгружаются через WebSocket.
Расширение Save Page WE сохраняет страницы с динамическим контентом в формате HTML с встроенными ресурсами. Оно поддерживает локальное сохранение видео с YouTube или Vimeo, если контент не защищён DRM. Для корректной работы нужно отключить блокировщики рекламы, так как они могут мешать загрузке скриптов. Расширение не справляется с контентом, требующим авторизации через OAuth или капчу.
При работе с защищёнными страницами (например, личными кабинетами) расширения могут не получить доступ к данным из-за политики CORS или ограничений Same-Origin. В таких случаях используют инструменты вроде Puppeteer или Playwright, запускаемые локально. Они эмулируют действия пользователя (ввод логина, прокрутку) и сохраняют итоговый HTML. Для автоматизации процесса создают скрипты на Node.js, которые обрабатывают страницы пакетно.
Перед выбором расширения проверяют его совместимость с целевым сайтом. Например, Web Scraper не работает на страницах с Content Security Policy (CSP), блокирующей внедрение скриптов. SingleFile может некорректно сохранять страницы с Shadow DOM, используемым в современных фреймворках. Тестирование проводят на нескольких страницах с разными типами динамического контента, чтобы выявить ограничения.
Сохранение полной версии страницы через инструменты разработчика
Инструменты разработчика в браузерах позволяют сохранить страницу со всеми зависимостями, включая стили, скрипты и медиафайлы, без использования сторонних расширений. В Chrome, Edge и Firefox процесс начинается с открытия панели DevTools (F12 или Ctrl+Shift+I). Перейдите на вкладку Sources (Chrome/Edge) или Отладчик (Firefox), затем в дереве файлов найдите корневой каталог страницы – обычно это домен сайта.
Щелкните правой кнопкой мыши по корневому каталогу и выберите Save as… (Chrome/Edge) или Сохранить папку как… (Firefox). Браузер сохранит HTML-файл вместе с папкой, содержащей все загруженные ресурсы: CSS, JS, изображения и шрифты. Важно: этот метод работает только для статически загруженных ресурсов – динамически подгружаемые данные (например, через AJAX) сохранены не будут.
- Chrome/Edge: вкладка Sources → правый клик на домене → Save as….
- Firefox: вкладка Отладчик → правый клик на домене → Сохранить папку как….
- Safari: Develop → Show Web Inspector → вкладка Resources → правый клик на странице → Save Page As….
Для страниц с ленивой загрузкой (lazy loading) или бесконечной прокруткой предварительно прокрутите контент до конца, чтобы все элементы загрузились в DOM. В Chrome можно принудительно загрузить все изображения через консоль: выполните команду document.querySelectorAll('img[loading="lazy"]').forEach(img => img.loading = 'eager'), затем обновите страницу перед сохранением.
Если страница использует Service Workers или кеширование через Cache API, часть ресурсов может не отображаться в дереве файлов. В этом случае откройте вкладку Application (Chrome/Edge) или Хранилище (Firefox), перейдите в раздел Cache Storage и экспортируйте нужные файлы вручную. Альтернатива – использовать режим Offline в DevTools (вкладка Network → чекбокс Offline), чтобы браузер загрузил все ресурсы из кеша.
Ограничения метода: не сохраняются данные, загружаемые через WebSocket, IndexedDB или LocalStorage. Для таких случаев используйте расширения вроде SingleFile или комбинируйте сохранение через DevTools с ручным копированием контента из вкладки Elements (Ctrl+A → Ctrl+C). Проверяйте целостность сохраненной копии: откройте HTML-файл локально и убедитесь, что все стили и скрипты подгружаются корректно.
Обработка и восстановление ссылок после скачивания сайта
После загрузки сайта локально ссылки часто ломаются из-за изменения структуры путей. Инструменты вроде HTTrack или wget сохраняют файлы в директориях, но не всегда корректно обновляют относительные пути в HTML, CSS и JavaScript. Например, ссылка /assets/style.css может превратиться в ../../assets/style.css, если страница сохранена в подпапке. Для исправления используйте регулярные выражения в текстовом редакторе (например, Notepad++ или VS Code) или скрипты на Python с библиотекой BeautifulSoup. Замените все абсолютные пути на относительные, учитывая новую иерархию файлов.
Особое внимание уделите динамическим ссылкам, генерируемым JavaScript. Если сайт использует фронтенд-фреймворки (React, Vue), ссылки могут формироваться через window.location или API-запросы. В таких случаях потребуется либо эмулировать серверную часть с помощью локального сервера (например, http-server для Node.js), либо вручную переписывать логику роутинга. Для статических сайтов достаточно заменить все вхождения href="/path" на href="./path" или href="subfolder/path", где subfolder – новая локальная директория.
Проверьте работоспособность ссылок автоматизированными инструментами: linkchecker для Linux или онлайн-сервисы вроде Dead Link Checker. Игнорируйте внешние ссылки – их восстановление бессмысленно без доступа к исходному домену. Для внутренних ссылок на изображения, скрипты и стили используйте относительные пути с учётом глубины вложенности. Если сайт содержит формы с POST-запросами, замените их на GET или настройте локальный прокси-сервер (например, Fiddler) для перехвата и модификации запросов.